


Retail Strategy Optimization AI Agent
Transform Retail Margins with Intelligent Promotion Management through AI-Agents - Built on Snowflake Cortex
Retail Strategy Optimization AI Agent Overview
The Retail Strategy Optimization AI Agent (also known as PromoGenie) transforms retail promotion management by providing autonomous decision-making and real-time optimization. Powered by advanced analytics, the agent monitors customer interactions to optimize pricing and maximize margins. This intelligent solution allows marketing leaders to move from reactive to proactive planning, ensuring measurable results across every campaign.
Problem Addressed
Traditional retail promotion management is often fragmented and too slow to keep pace with dynamic market conditions:
- Manual Bottlenecks: Managing promotions across spreadsheets is time-consuming and prone to administrative errors.
- Inaccurate Forecasting: Relying on intuition for budget allocation often leads to overruns or missed revenue opportunities.
- Fragmented Data: Disconnected customer signals make it difficult to unify marketing efforts across different channels.
- Static Pricing: Delayed responses to competitor pricing or shifts in consumer behavior result in lost sales and eroded margins.
What the Agent Does
The agent acts as an autonomous retail strategist that handles end-to-end promotion workflows:
- Identifies Opportunities: Uses machine learning to micro-segment customers and identify high-value cross-selling opportunities.
- Optimizes Pricing: Adjusts prices automatically based on real-time demand, inventory levels, and competitor activity.
- Targets Customers Intelligently: Groups subscribers based on behavior to deliver personalized offers and journey-based triggers.
- Simulates Scenarios: Performs "what-if" modeling for price adjustments and promotional displays to predict outcomes before execution.
- Triggers Automated Actions: Directly executes replenishment tasks or promotional pivots across e-commerce and physical channels.
Benefits
- Maximized Campaign ROI: Boost profitability through data-driven lead scoring and optimized investment efficiency.
- Agility in Dynamic Markets: Detect shifts in consumer behavior and pivot campaigns in seconds rather than days.
- Improved Customer Engagement: Drive loyalty by delivering personalized experiences that match individual intent and behavior.
- Reduced Operational Overhead: Automate repetitive administrative tasks, allowing teams to focus on high-level innovation.
Standout Features
- Autonomous Decision-Making: Moves beyond predefined rules to act intelligently based on real-time environmental cues.
- Real-Time Margin Protection: Monitors margin thresholds to ensure discounts never compromise overall profitability.
- Extensible AI Architecture: Seamlessly integrates with existing CRM, ERP, and Snowflake infrastructure for rapid deployment.
- Dynamic Scenario Modeling: Allows users to query supply chain and loyalty data in natural language to test new strategies.
- Cross-Channel Coordination: Orchestrates frictionless journeys across web, mobile, and in-store touchpoints.
Who This Agent Is For
This agent is built for retail executives, marketing directors, and store operations leads who need to scale their decision-making.
Ideal for:
- Marketing Leaders: Professionals who need real-time visibility into customer behavior to justify campaign spend.
- Merchandisers: Teams focused on shelf optimization and reducing surplus inventory through targeted markdowns.
- E-commerce Managers: Leaders looking to unify fragmented data and automate high-frequency price adjustments.
- Retail Operations Leads: Staff responsible for managing multi-channel promotions and workforce allocation in a fast-paced environment.
How it works

Manufacturing Process Transformation AI Agent
Empowering Manufacturing with Proactive Manufacturing Decision-Making - Built on Snowflake Cortex
Intelligent AI for Modern Manufacturing Operations
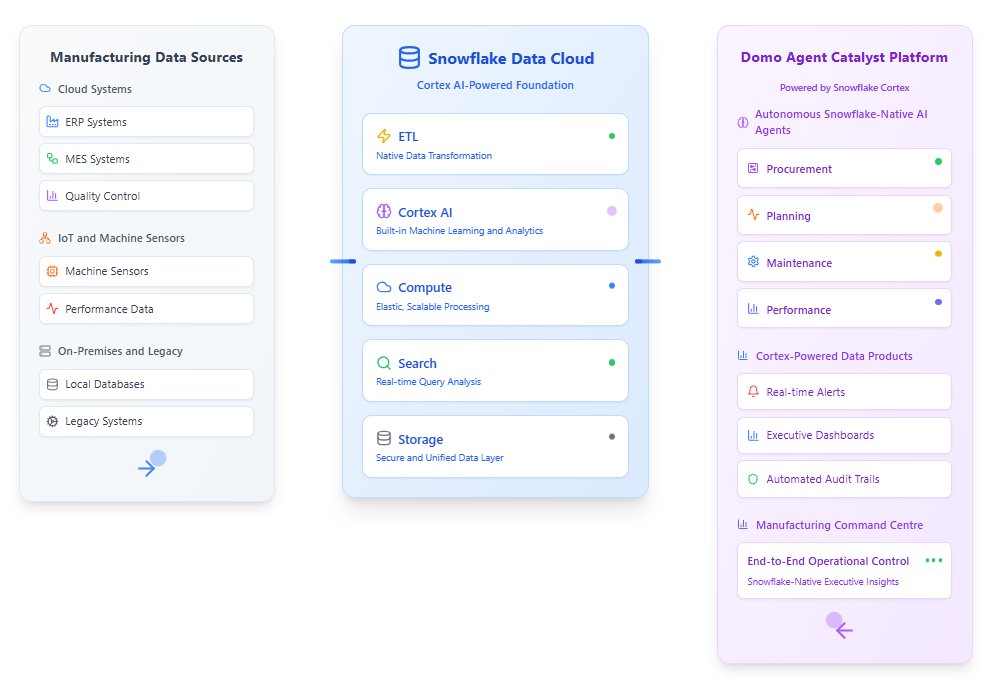
The Manufacturing Process Transformation AI Agent helps manufacturers modernize and optimize production by turning operational data into real time, actionable intelligence. Built on Domo’s AI Agent Catalyst Platform with secure Snowflake integration, this agent continuously monitors production environments, predicts issues before they occur, and recommends targeted actions to improve efficiency, quality, and profitability.
Instead of relying on periodic reports or manual analysis, the agent acts as a centralized decision engine across your production ecosystem. It connects data from machines, sensors, maintenance systems, and supply chain tools to help teams reduce downtime, improve margins, and drive continuous operational improvement.
Benefits
- Reduced downtime
Predict equipment failures before they happen using continuous monitoring and AI driven maintenance recommendations. - Improved operational efficiency
Optimize production schedules, labor allocation, and energy usage based on real time conditions. - Stronger quality control
Detect process deviations earlier by identifying patterns linked to defects or inconsistencies. - Higher margins
Surface cost saving opportunities and efficiency gains that directly impact profitability. - Smarter supply chain alignment
Forecast material needs and adjust production plans based on supply availability and constraints. - Transparent decision making
Every AI recommendation includes a clear explanation and expected business impact. - Continuous improvement over time
The agent learns from outcomes and adapts as your operations evolve.
Why Use AI for Manufacturing Transformation?
Traditional manufacturing optimization depends on delayed analysis and manual interpretation of complex operational data. That approach makes it difficult to respond quickly to emerging issues or simulate the impact of changes before acting.
AI excels at processing large volumes of production data across multiple systems at once. This agent continuously evaluates machine performance, process signals, and historical trends to detect subtle patterns that human teams often miss. Over time, it builds a more accurate operational model that improves predictions and recommendations.
Unlike static dashboards, the Manufacturing Process Transformation AI Agent proactively identifies improvement opportunities, recommends specific actions, and quantifies expected outcomes while maintaining full auditability and governance.
How It Works
Who This Agent Is For
This agent is designed for teams who want to modernize manufacturing operations with intelligent, data driven decision making.
It is ideal for organizations looking to:
- Reduce unplanned downtime and maintenance costs
- Improve production efficiency across multiple lines or facilities
- Detect quality issues earlier in the manufacturing process
- Align production planning with real world supply chain conditions
- Move from reactive reporting to proactive operational optimization
Ideal for: manufacturing operations leaders, plant managers, industrial engineers, maintenance teams, supply chain managers, and continuous improvement teams.

Competitive Content Intelligence AI Agent
Accelerate internal and external research, content strategy, and asset deployment through your marketing channels
Streamline Competitive Content Creation
Competitive intelligence is hard to scale and even harder to keep consistent in fast-moving markets. Roxie, your AI Content Strategist, continuously monitors internal CRM data alongside external sources like competitor websites and analyst reports to surface actionable insights.
Roxie helps teams understand where you’re winning or losing deals, why it’s happening, and how to improve your go-to-market messaging—so content stays relevant, differentiated, and aligned to real market signals.
How Roxie Works
Roxie uses purpose-built AI agents to handle every stage of the content lifecycle—from research to publication—while keeping humans in control.
It combines:
- Internal data such as CRM insights, deal notes, and performance signals
- External intelligence including competitor content, analyst coverage, and market trends
The result is content that reflects both what the market is saying and what your data proves.
Key Benefits
- End-to-end content intelligence
Purpose-built agents support deep research, strategy development, SEO optimization, content authoring, tagging, and categorization. - Data-driven topic discovery
Leverages proprietary internal data and publicly available external sources to identify high-impact content opportunities. - Human-in-the-loop quality control
Built-in approvals and integrations ensure tone, accuracy, and brand voice stay consistent. - Seamless publishing
Automatically pushes finalized copy, metadata, and assets to your preferred content management system (CMS).
Powered by Deep Research
Roxie can leverage Domo’s Deep Research agent or focus on a specific topic of your choice to generate competitive insights and content recommendations tailored to your goals.
Built for Scale
Roxie can automatically translate content and be extended to publish across multiple channels, helping teams scale global content efforts without sacrificing quality or consistency.
Who This Agent Is For
The Competitive Content Intelligence AI Agent is designed for teams that need faster, more consistent competitive insights to power better content and messaging.
- Product Marketing Teams
Turn win-loss data and competitive signals into sharper positioning, clearer differentiation, and stronger go-to-market narratives. - Content and Editorial Teams
Identify high-impact topics, create content aligned to real buyer questions, and maintain consistency across formats and channels. - SEO and Growth Teams
Discover competitor gaps, prioritize keywords and topics, and optimize content based on performance data and market demand. - Sales Enablement Teams
Create competitive content, battlecards, and supporting assets that reflect what prospects are actually responding to in deals. - Enterprise Marketing Organizations
Scale competitive intelligence and content creation across products, regions, and teams without sacrificing accuracy or quality.

Sales Ops Agent
Raw activity in. Deal intelligence out. AI-ranked deal queue, evidence-backed risks, and one-click Salesforce write-back.
Raw activity in. Deal intelligence out.
Sales Ops Agent reads every call, email, and CRM update — then tells each rep exactly which deal to work next, what risks are hiding in it, and what to do about them. Then it writes the update back to Salesforce for you.
Your best reps already do this intuitively. Sales Ops Agent makes it automatic for everyone — at no additional license cost for existing Domo customers.
Benefits
- Reps stop guessing which deal to work next — every opportunity is ranked by risk, momentum, and urgency
- Risks surface with severity rankings and direct-quote evidence from real call transcripts
- AI-drafted follow-up emails and call agendas grounded in actual conversations, not CRM stage
- One-click Salesforce write-back for Close Date, ACV, Next Steps, and Forecast Comments
- 6-milestone tracking with Rep Edited vs. AI-predicted badges for full forecast accountability
- Zero additional license cost for existing Domo customers — live in hours, not quarters
Problem Addressed
Every revenue team already has the raw material — calls are recorded, emails are logged, Salesforce is updated (eventually). What's missing is the layer that connects it all into a single, trustworthy signal about which deals are real, which are at risk, and what to do next.
- Deal slippage arrives as a surprise, not a signal — manual pipeline reviews miss what's actually happening
- CRM stages don't reflect buyer reality — true deal status hides in call transcripts and email threads
- Call data, CRM, and email signals stay siloed — no one stitches them together in real time
- Forecast accuracy depends on rep self-reporting — not on what the buyer actually said
- Coaching is reactive, never real-time — managers learn what happened instead of what's happening
What the Agent Does
- AI-Prioritized Deal Queue — Every deal scored on risk, momentum, and urgency. Reps stop guessing which account to touch first.
- Evidence-Backed Risk Detection — Severity-ranked risks (Critical / High / Medium / Low) with direct quotes from real call transcripts.
- Embedded AI Coach — Drafts follow-up emails and call agendas grounded in actual calls, so reps show up prepared to every meeting.
- Live Write-Back — One-click CRM write-back for Close Date, ACV, Next Steps, Forecast Comments, and other forecast fields without leaving Sales Ops Agent.
- 6-Milestone Deal Tracking — AI-predicted milestone dates alongside rep-reported stages, with Rep Edited vs. AI badges on every milestone.
Standout Features
- Multi-source intelligence — reads Gong transcripts, Salesforce, and email simultaneously
- Direct-quote evidence on every risk — not a gut-feel score, actual signal with the receipts
- Immediate / This Week / Next Week action sorting per deal, per rep
- 7-swimlane Deal Pulse Timeline across Calls, Emails, Stages, Risks, Milestones, Engagement, and Write-Backs
- Runs on the Domo instance you already own — no new warehouse, no new vendor, no IT ticket
Who This Agent Is For
This agent is designed for teams who want to:
- Replace gut-feel forecasts with evidence-backed deal intelligence
- Give reps clear, prioritized action lists instead of activity spray
- See risk before it shows up in the forecast — with receipts
- Eliminate dual-entry between call tools, email, and CRM
- Scale coaching to every rep, not just the ones a manager happens to sit with
Ideal for: VPs of Sales, CROs, Sales Ops and RevOps leaders, front-line Sales Managers, and revenue teams running Salesforce alongside a conversation-intelligence tool like Gong, Chorus, or Clari Copilot.
How It Works
Sales Ops Agent runs a four-layer pipeline from raw signal to closed deal:
- Connect — Salesforce (or your CRM), Gong (or your call tool), email. Read-only where possible; write-back where it matters.
- Analyze — AI reads every transcript, every thread, every stage change. Extracts signals, risks, momentum, and milestone completion.
- Prioritize — Every deal gets an AI Priority Score. Risks are severity-ranked with direct-quote evidence. Actions are sorted Immediate / This Week / Next Week.
- Act — Rep clicks into the top deal, reads the AI-drafted follow-up, edits Close Date and Forecast Comments, hits save. Salesforce updates in real time.
Runs on the Domo instance you already own. No new data warehouse. No new vendor. No IT ticket.

Sales Incentive & Gamification AI Agent
Real-time sales incentive platform tracking multiple parallel programs with live leaderboards, tier progression, sweep entries, and manager-created bonus contests.
Three programs. Twenty-six reps. One leaderboard that everyone actually looks at.
Sales incentive programs only work when reps can see exactly where they stand. A marketing company managing a wireless carrier’s incentive program had the opposite problem: 26 sales representatives across 11 offices, 8 regions, and 4 skill groups were participating in three parallel incentive programs, and nobody could tell you in real time how many points they had, what tier they were in, or which bonus contests were currently active. The compensation data lived in spreadsheets that were updated weekly — sometimes biweekly — and distributed via email. Reps disputed their numbers. Managers couldn’t tell who was close to a tier threshold. And the promotional contests that were supposed to drive short-term performance spikes went largely unnoticed because they were buried in the same email thread as everything else.
The Sales Incentive & Gamification platform replaces all of that with a real-time, competitive experience that reps actually want to open every morning. Built as a custom ProCode application on Domo, it tracks individual sales history across three parallel programs, calculates points accumulation and sweep entries in real time, visualizes tier progression (Bronze, Silver, Gold) for every rep, and surfaces a live promotions ticker where managers can create and push bonus contests without any development cycle. The result is a transparent, gamified system that motivates reps through competition and visibility rather than opaque spreadsheets and delayed updates.
Benefits
This platform transforms sales incentive management from an administrative burden into a competitive advantage that drives measurable behavior change.
- Real-time transparency: Every rep sees their exact point total, tier status, sweep entries, and ranking the moment a qualifying sale is recorded — no more waiting for weekly spreadsheet updates
- Comp dispute elimination: When every calculation is visible and traceable in real time, the disputes that consumed manager hours every pay period disappear entirely
- Manager-created promotions: Office and regional managers create bonus contests through an AppDB-backed interface and push them to the live promotions ticker instantly — no development cycle, no IT ticket
- Multi-program tracking: Three parallel incentive programs run simultaneously with independent point calculations, tier progressions, and leaderboards — all visible in one interface
- Competitive motivation: Leaderboards by office, region, and skill group create the kind of visible competition that drives incremental effort from reps who can see they are two sales away from the next tier
- Regional leadership visibility: Office-level and region-level roll-ups show exactly which teams are driving program results and which need coaching or support
Problem Addressed
Sales incentive programs fail silently when the people they are designed to motivate cannot see the scoreboard. A rep who does not know they are 50 points from Gold tier has no reason to push for one more sale before Friday. A manager who cannot see which reps are close to bonus thresholds cannot coach them toward the finish line. An office that does not know it is trailing another office by a narrow margin has no competitive spark to close the gap.
The operational burden is equally damaging. Calculating points across three programs with different rules, tracking tier progression for 26 reps, managing sweep entry eligibility, and coordinating promotional contests manually is a full-time administrative job. When it is done in spreadsheets, errors compound, updates lag, and the incentive program — which exists to drive behavior — becomes just another email attachment that reps check once and forget.
What the Agent Does
The platform operates as a real-time incentive calculation and gamification engine:
- Sales data ingestion: Connects to the sales transaction system and attributes each qualifying sale to the correct rep, office, region, and skill group with program-specific point calculations
- Multi-program point engine: Calculates points independently for each of three parallel programs using program-specific rules, multipliers, and qualification criteria
- Tier progression tracking: Maps each rep’s cumulative points against Bronze, Silver, and Gold thresholds, visualizing progress and distance to the next tier in real time
- Sweep entry calculation: Determines sweep entry eligibility based on program rules, calculating and displaying total entries earned per rep per program
- Live promotions ticker: Surfaces active bonus contests — such as gift cards for top earners or extra PTO for reaching specific thresholds — with countdown timers and current standings
- Leaderboard generation: Ranks reps by points, tier, and program across multiple dimensions — by office, by region, by skill group — creating competitive visibility at every organizational level
Standout Features
- No-code promotion creation: Managers create bonus contests through a simple AppDB-backed form — name the promotion, set the rules, pick the date range, and it appears on every rep’s promotions ticker immediately
- Four-dimensional leaderboards: View rankings by individual, by office, by region, or by skill group — each dimension tells a different performance story and creates a different competitive dynamic
- Tier threshold alerts: Reps within striking distance of a tier upgrade receive automated notifications showing exactly how many points or sales they need to advance
- Historical program analytics: Track program performance over time — which program drives the most incremental sales, which promotions generated the biggest spikes, which offices consistently outperform
- Skill group benchmarking: Compare performance across four skill groups to identify training opportunities and ensure incentive structures are calibrated appropriately for different role levels
Who This Agent Is For
This platform is built for organizations running sales incentive programs that are complex enough to need real-time calculation but are currently managed in spreadsheets or legacy comp systems.
- Sales reps who want to see their exact standings, points, and tier progress without waiting for a manager to send an update
- Office managers who need visibility into their team’s incentive performance and the ability to create local promotions that drive short-term results
- Regional leaders managing multiple offices who need comparative performance data to allocate coaching and support resources
- Program administrators calculating points, tiers, and eligibility across multiple parallel incentive structures
- HR and finance teams who need clean, auditable incentive calculation records for compensation processing
Ideal for: telecommunications retailers, insurance sales organizations, automotive dealership groups, staffing agencies, mortgage brokerages, and any organization where sales compensation includes points, tiers, contests, or gamification elements across distributed teams.

Department Sales Recap AI Agent
Weekly department-level sales tracking app that captures daily revenue by department across retail locations with cross-location analysis and benchmarking.
Every department. Every store. Every day of the week.
For a small retail chain, the gap between gut instinct and governed data can be surprisingly expensive. A regional thrift retailer operating three locations was tracking department-level sales in spreadsheets that each store manager maintained independently. The Tampa manager had one format. The St. Petersburg manager had another. The Bradenton manager sometimes forgot to update theirs until the following week. When the regional manager wanted to compare weekend performance across stores or identify which departments were trending up, the answer was always the same: give me a few days to pull the numbers together.
The Department Sales Recap app eliminates that lag entirely. Store managers enter daily revenue by department directly in a ProCode application that handles inline editing, auto-save, and even offline entry when the store’s Wi-Fi drops. Every submission flows into a sync-enabled AppDB collection that automatically pushes structured data into a Domo dataset. Within seconds of entry, the regional manager can see cross-location comparisons, day-of-week patterns, department trends, and store-versus-store benchmarks — no spreadsheet consolidation, no format normalization, no waiting.
Benefits
This app transforms department-level sales tracking from a manual reporting chore into an always-current intelligence layer that makes cross-location retail analysis effortless.
- Instant cross-location analysis: The moment a store manager saves their numbers, the regional view updates — compare Tampa versus St. Petersburg versus Bradenton without any manual consolidation
- Day-of-week pattern detection: See exactly how Saturday revenue compares to Tuesday across every department and location, surfacing weekend traffic patterns and weekday opportunities
- Department benchmarking: Which store’s Women’s department outperforms the others? Is Household trending up in one location and down in another? The data answers these questions instantly
- Offline resilience: Store managers can enter sales data even when Wi-Fi drops — localStorage fallback preserves entries and syncs automatically when connectivity returns
- Zero spreadsheet overhead: No more emailing Excel files, no more version conflicts, no more format normalization — everyone enters data in the same app and it flows into one governed dataset
- Historical trend analysis: Weeks and months of daily department data accumulate into a rich dataset for seasonal analysis, promotional impact measurement, and year-over-year comparison
Problem Addressed
Small and mid-size retail chains often outgrow spreadsheets long before they realize it. When you have three stores, each with five departments, tracking daily revenue across seven days, you are managing 105 data points per week per store. Across three stores, that is 315 weekly entries that someone needs to collect, normalize, and analyze. It sounds manageable until you consider that the analysis — comparing stores, identifying trends, spotting anomalies — requires all 315 entries to be in the same format, in the same place, at the same time. Spreadsheets almost never achieve that.
The downstream cost is invisible but real. A department that is underperforming at one location goes unnoticed for weeks because nobody had time to compare the numbers. A weekend promotion that drove significant traffic at one store is not replicated at others because the data was buried in a spreadsheet that arrived late. The regional manager makes staffing and inventory decisions based on impressions rather than data because the data takes too long to assemble.
What the Agent Does
The app operates as a lightweight but governed sales data capture and cross-location analysis system:
- Department-level entry: Store managers enter daily revenue for each department — Women’s, Men’s, Children’s, Shoes, and Household — through a simple, purpose-built interface
- Inline editing and auto-save: Corrections and updates happen in-place with automatic saving, eliminating the risk of lost entries or version conflicts
- Offline fallback: When store connectivity drops, entries are cached in localStorage and automatically sync to AppDB when the connection is restored
- AppDB-to-Dataset sync: Every submission flows from the app into an AppDB collection that automatically pushes structured records into a Domo dataset for analytics
- Cross-location dashboards: Pre-built views compare department revenue across all locations by day, week, and trend, with store-versus-store benchmarking
- Day-of-week analysis: Visualizations break down revenue patterns by day of the week, surfacing which days drive traffic to which departments at which locations
Standout Features
- Purpose-built simplicity: The entry interface shows only what the store manager needs — their store, today’s date, and five department fields. No training required, no complex navigation, no confusion
- Governed from entry to analysis: Data flows from the store manager’s screen through AppDB into a Domo dataset without any manual export, email, or file transfer — the chain of custody is clean
- Works on any device: Store managers can enter data from a tablet at the register, a phone in the back office, or a desktop — the responsive interface adapts to any screen
- Automatic data quality: The app validates entries at submission — no negative numbers, no missing departments, no duplicate days — ensuring the dataset stays clean without manual review
- Scalable to more locations: Adding a fourth or fifth store requires only adding the location to the app configuration — the cross-location analysis automatically incorporates the new data
Who This Agent Is For
This app is built for retail operators who have outgrown spreadsheets but don’t need (or can’t afford) an enterprise POS analytics platform.
- Store managers who need a fast, simple way to record daily department sales without spreadsheet overhead
- Regional managers who need cross-location performance comparisons without waiting for manual data consolidation
- Operations teams identifying top-performing departments, underperforming locations, and day-of-week patterns
- Finance teams tracking actual department revenue against budgets with daily granularity
- Franchise or chain operators scaling from a few locations who need consistent data capture from day one
Ideal for: thrift stores, specialty retail chains, consignment shops, small grocery chains, boutique retailers, and any multi-location retail operation where department-level sales tracking happens today in spreadsheets.

Studio Performance Dashboard AI Agent
Real-time franchise performance dashboard tracking the complete member funnel from leads through retention across multiple studio locations with churn prediction and LTV modeling.
Every location. Every metric. Every stage of the member journey.
Running a multi-location fitness franchise means managing dozens of variables that compound across sites. One studio might be converting leads at 40% but hemorrhaging members at 90 days. Another might have low lead volume but exceptional retention. A third might look healthy on revenue but is propped up by a promotional pricing wave that expires next month. Without a unified view that connects the full member funnel — from first lead to long-term retention — corporate leadership discovers these patterns too late to intervene effectively.
The Studio Performance Dashboard gives franchise operators that unified view. Built as a custom ProCode application on Domo, it tracks every location across the complete membership lifecycle: leads generated, intro appointments booked, sessions completed, memberships closed, monthly churn rates, frozen account volumes, active member counts, and projected versus actual revenue. Each location is tiered against a performance baseline so managers see not just raw numbers but context — is this studio above or below where it should be? — and corporate leadership gets a roll-up view that instantly surfaces which locations need attention and which are driving growth.
Benefits
This dashboard transforms franchise management from reactive monthly reviews into proactive daily intervention based on real-time funnel performance across every location.
- Complete funnel visibility: Track every stage from lead generation through long-term retention in one view — no more piecing together booking data from one system, membership data from another, and revenue from a third
- Early revenue risk detection: 30-day cancellation notice tracking and churn trend analysis surface revenue risk weeks before it hits the P&L, giving operators time to intervene
- Performance tiering: Each location is benchmarked against its expected performance baseline, so a studio converting at 35% is flagged if its baseline is 45% but celebrated if its baseline is 25%
- Lifetime value modeling: LTV calculations per location and membership type show which studios are acquiring high-value members versus cycling through promotional sign-ups
- Corporate roll-up: Every location-level metric aggregates into a single corporate view showing portfolio health, top performers, and at-risk studios in one dashboard
- Frozen account intelligence: Tracks frozen membership volumes separately from active churn, distinguishing between members who paused temporarily and those who left permanently
Problem Addressed
Franchise operators typically have access to pieces of member data but not the connected picture. The booking system shows appointment volume. The membership system shows active counts. The billing system shows revenue. But none of these systems connect the full journey from lead to long-term member, and none of them provide the cross-location comparison that franchise leadership needs to allocate resources and attention effectively.
The result is that corporate leadership operates on lagging indicators. They see last month’s revenue after the month closes. They discover a studio’s churn problem when quarterly reviews reveal the trend. They learn about a lead generation collapse when a studio manager mentions it in a call. By the time these signals reach the decision-makers, the operational window to course-correct has often passed.
What the Agent Does
The dashboard operates as a real-time franchise intelligence system tracking the complete member lifecycle across all locations:
- Lead tracking: Ingests lead data from marketing platforms and CRM, attributing lead volume and source by location with conversion rate calculations at each funnel stage
- Funnel analysis: Maps every member through leads → intro appointments → bookings → completions → closes, calculating conversion rates and drop-off points at each stage per location
- Retention monitoring: Tracks monthly churn, 30-day cancellation notices, frozen account rates, and active member counts with trend lines showing directional movement per studio
- Revenue projection: Compares projected revenue (based on active membership and pricing) against actual collections, flagging variances and identifying the underlying causes
- Performance tiering: Each location is assigned a performance tier based on its baseline and current trajectory, with automated escalation when a studio drops below threshold
- Lifetime value calculation: Computes member LTV by studio, membership type, and acquisition channel, showing which lead sources produce the highest long-term value
Standout Features
- 30-day cancellation pipeline: Members who have submitted cancellation notices are tracked separately as upcoming churn, giving studios a window to engage retention efforts before the member leaves
- Manager-specific views: Each studio manager sees their location’s performance with their specific targets, while corporate sees the full portfolio — same data, different context
- Seasonal adjustment: Performance baselines adjust for known seasonal patterns (January surge, summer dip) so managers are evaluated against realistic expectations, not flat annual targets
- Drill-through from corporate to studio: Corporate leaders can click from the portfolio view directly into any studio’s detailed metrics, seeing the specific funnel stage or retention metric driving the overall score
- Automated risk alerts: When a studio’s churn rate exceeds its baseline or lead conversion drops below threshold for three consecutive weeks, automated alerts notify regional and corporate leadership
Who This Agent Is For
This dashboard is built for franchise operators who need to manage member lifecycle performance across multiple locations without waiting for month-end reports to discover problems.
- Studio managers tracking their daily funnel performance and retention metrics against targets
- Regional directors overseeing multiple locations who need to quickly identify which studios need attention
- Franchise leadership making resource allocation decisions based on real-time portfolio performance
- Marketing teams measuring lead quality and conversion rates by source and location
- Finance teams projecting revenue based on active membership trends and cancellation pipeline
Ideal for: fitness franchises, wellness studios, healthcare clinics, tutoring centers, salon chains, and any multi-location service business where member acquisition and retention drive recurring revenue.

Lab Compliance & Data Collection AI Agent
Digital lab compliance system with ten interconnected forms, immutable audit records, and real-time regulatory visibility for GMP environments.
Ten forms. One compliance posture. Zero paper.
In a GMP production environment, documentation is not a suggestion — it is the difference between passing an FDA audit and receiving a warning letter. A regulated biotechnology research facility was managing this documentation across paper binders, standalone spreadsheets, and email chains. Sample intake logs lived in one binder. Equipment calibration records lived in another. Deviation reports were handwritten and filed in folders that only one person knew how to navigate. When an inspection was announced, the team spent days assembling documentation that should have been instantly accessible. Worse, calibration due dates sometimes slipped because nobody was systematically tracking them — the reminder lived in someone’s head or on a sticky note on a lab bench.
The Lab Compliance system replaces all of that with a unified digital platform built on Domo. Ten interconnected forms cover every documentation requirement in the GMP production workflow, each backed by a dedicated AppDB collection that syncs in real time to Domo datasets. Every submission is timestamped, immutable, and immediately available for audit review. Calibration due dates surface automatically. Non-conformance events trigger resolution workflows. And the QA team has a live dashboard showing the compliance status of every piece of equipment, every active batch, and every training certification in the facility.
Benefits
This system transforms lab compliance from a paper-based retrospective exercise into a continuously updated, audit-ready digital operation.
- Inspection-ready at all times: Every piece of compliance documentation is digital, timestamped, and instantly accessible — no more multi-day scrambles to assemble binders before an FDA visit
- Immutable audit trail: Every form submission creates a permanent, timestamped record in AppDB that cannot be altered after the fact, giving auditors exactly the traceability they require
- Automated calibration tracking: Equipment calibration due dates are computed and surfaced automatically — no more missed recalibrations because the reminder was on a sticky note that fell off the bench
- Non-conformance visibility: Deviation reports flow into a structured workflow that tracks resolution status, assigned investigators, and corrective actions through completion
- Real-time training status: Every employee’s training certifications, expiration dates, and completion records are visible in a single view, ensuring the facility never operates with uncertified personnel
- Connected data model: Sample intake connects to experiment logs which connect to batch records which connect to equipment use — the entire production history is linked rather than scattered across independent documents
Problem Addressed
Regulated laboratories operate under documentation requirements that assume every action is recorded, every record is retrievable, and every piece of equipment is within its calibration window at the time of use. Paper-based systems technically satisfy these requirements — if you can find the right binder, if the handwriting is legible, if the form was actually filled out at the time of the event rather than reconstructed later, and if the calibration sticker on the equipment matches the record in the log.
In practice, paper systems create gaps that compound silently. A reagent lot gets used without being logged. An environmental monitoring reading is taken but not transcribed until the next day. A training certification expires and nobody notices for two weeks because the tracking spreadsheet was not updated. Each gap on its own is minor. Accumulated across months of production cycles, they create the kind of systemic documentation weakness that regulators are specifically trained to identify.
What the Agent Does
The system operates as a unified digital documentation platform covering the complete GMP production workflow:
- Sample intake forms: Digital capture of incoming sample metadata, chain-of-custody records, and storage condition documentation with barcode or manual entry
- Experiment logging: Structured forms for recording experimental procedures, observations, results, and deviations in real time as work is performed
- Equipment use tracking: Logs which equipment was used for which procedures, automatically verifying that calibration status was current at time of use
- Environmental monitoring: Records temperature, humidity, particulate counts, and other environmental parameters with automated out-of-range alerting
- Calibration management: Tracks calibration schedules, records calibration results, computes next-due dates, and surfaces overdue instruments before they are used
- Deviation and CAPA workflow: Structured reporting for non-conformance events with assigned investigation, root cause analysis, corrective action tracking, and closure verification
Standout Features
- Ten interconnected form types: Sample intake, experiment logging, equipment use, environmental monitoring, reagent tracking, calibration records, deviation reports, batch records, audit checklists, and training certifications — all linked through a common data model
- AppDB-to-Dataset sync: Every form submission writes to a dedicated AppDB collection that automatically syncs into Domo datasets, enabling cross-form analytics without manual data movement
- Proactive compliance alerts: Calibrations approaching due date, training certifications nearing expiration, and unresolved deviations older than their SLA all trigger automated notifications to the responsible party
- Audit-ready reporting: Pre-built compliance reports generate the exact documentation packages that FDA inspectors and GMP auditors request, organized by date range, equipment, batch, or personnel
- Offline capability: Lab personnel can submit forms from tablets in areas with intermittent connectivity, with data syncing automatically when connection is restored
Who This Agent Is For
This system is built for regulated laboratories and production facilities where compliance documentation is not optional and paper-based systems are creating risk.
- QA managers responsible for maintaining audit-ready documentation across all GMP operations
- Lab supervisors who need their teams documenting work in real time rather than reconstructing records after the fact
- Compliance officers preparing for FDA inspections who need instant access to any documentation an auditor might request
- Equipment managers tracking calibration schedules across dozens or hundreds of instruments
- Training coordinators ensuring every employee operating in the GMP environment has current certifications
Ideal for: biotechnology companies, pharmaceutical manufacturers, contract research organizations, medical device manufacturers, food production facilities, and any organization operating under FDA, GMP, GLP, or ISO quality management requirements.

Retail Intelligence Hub AI Agent
Omni-channel intelligence hub consolidating performance data across eight retail channels into a unified view with sales trends, financial tracking, marketing attribution, product health, and competitive share.
Eight channels. Five data domains. One truth.
A consumer products brand selling through Amazon, Walmart, Target, Wayfair, and four additional marketplace platforms was running each channel’s reporting in isolation. The Amazon team had their dashboards. The Walmart team had theirs. Marketing had a separate set of spreadsheets tracking ROAS by platform. Finance pulled actuals from yet another system. Nobody had a unified view of where revenue was actually coming from, which marketing spend was driving sell-through, or which products were at risk of stocking out across channels. Every Monday’s leadership meeting started with 45 minutes of reconciling numbers before anyone could discuss strategy.
The Retail Intelligence Hub eliminates that entirely. Built as a custom ProCode application on Domo, it consolidates all eight retail channels into a single governed dataset model and surfaces five unified data domains: a 52-week rolling sales history with seasonal trend modeling, actual-versus-budget financial performance by product category, marketing spend efficiency including ROAS and conversion attribution by platform and campaign, product health indicators such as weeks-of-supply and buy-box percentage, and competitive market share trending by brand. Category managers open one dashboard and see everything.
Benefits
This agent transforms fragmented, channel-specific retail reporting into a unified intelligence layer that gives every stakeholder the same numbers, the same context, and the same early warnings.
- Unified cross-channel visibility: Eight retail channels consolidated into one governed view — no more reconciling Amazon numbers against Walmart numbers against Shopify numbers before every meeting
- 52-week seasonal intelligence: Rolling sales history with trend modeling that surfaces seasonal patterns, year-over-year shifts, and emerging category dynamics across all channels simultaneously
- Marketing attribution clarity: ROAS and conversion attribution broken down by platform, campaign, and product category so marketing knows exactly which spend is driving measurable sell-through and which is not
- Product health early warning: Weeks-of-supply calculations, buy-box percentage tracking, and inventory risk indicators that flag problems before they become stockouts or lost listings
- Competitive share trending: Brand-level market share data showing how your products are performing relative to competitors across every tracked category and channel
- Daily operational cadence: Data refreshes daily so category managers and channel directors operate on current numbers rather than last week’s exports
Problem Addressed
Omni-channel retail creates an omni-channel data problem. Each marketplace platform provides its own reporting portal with its own metrics, its own export formats, and its own update cadence. Amazon Seller Central shows one version of reality. Walmart Retail Link shows another. Target’s portal has its own structure. Wayfair, Shopify, and marketplace aggregators each add their own layer. The result is that nobody in the organization can answer a simple question like “what was our total revenue last week across all channels?” without pulling exports from eight systems and spending hours normalizing them into a comparison.
The problem compounds when you add marketing, inventory, and competitive data to the picture. Marketing spend flows through different platforms than sales data. Inventory feeds come from warehouse and 3PL systems. Competitive intelligence comes from syndicated data providers. Without a unified model that connects all of these, the organization makes decisions in silos — the marketing team optimizes spend without seeing inventory constraints, the sales team pushes volume without seeing margin impact, and finance discovers the gaps after the quarter closes.
What the Agent Does
The hub operates as a unified retail intelligence engine connecting every data source into a single analytical model:
- Multi-channel data ingestion: Connectors pull daily data from eight retail platform APIs — Amazon, Walmart, Target, Wayfair, Babylist, Shopify, and two additional marketplaces — normalizing different schemas into a unified product-channel-date model
- Rolling sales analysis: Maintains a 52-week rolling sales history with automated seasonal trend detection, year-over-year comparison, and category-level growth rate calculations across all channels
- Financial performance tracking: Compares actual revenue and margin against budget targets by product category and channel, surfacing variances with root-cause indicators
- Marketing attribution engine: Maps marketing spend to conversion outcomes by platform and campaign, calculating ROAS, cost-per-acquisition, and attributed revenue at the channel and product level
- Product health monitoring: Calculates weeks-of-supply from current inventory and sales velocity, tracks buy-box ownership percentage on Amazon, and flags products at risk of stockout or delisting
- Competitive share analysis: Integrates syndicated market data to show brand-level share trending within tracked categories, identifying where share is growing or eroding relative to competitors
Standout Features
- Channel-agnostic data model: Adding a ninth or tenth retail channel requires only a new connector configuration — the unified schema, dashboards, and calculations automatically incorporate the new data without rebuilding anything
- Revenue mix decomposition: Instantly see how total revenue breaks down by channel, product category, and time period — identifying which channels are growing share of the portfolio and which are declining
- Inventory risk scoring: Products are scored by stockout risk based on current velocity, weeks-of-supply, and replenishment lead times — giving operations a prioritized action list rather than a wall of SKU data
- Campaign-level drill-through: From a ROAS summary, drill directly into individual campaign performance by platform, seeing creative-level metrics alongside attributed conversions
- Governed single source of truth: Every number in every dashboard traces back to the same unified dataset — eliminating the “my numbers don’t match your numbers” problem that derails most cross-functional retail meetings
Who This Agent Is For
This hub is built for consumer products organizations selling through multiple retail channels who need a single, governed view of performance across their entire distribution footprint.
- Category managers responsible for product performance across multiple retail partners who currently reconcile data from separate portals
- Channel directors managing marketplace relationships who need daily visibility into sales velocity, inventory health, and competitive positioning
- Marketing teams allocating spend across platforms who need attribution data that connects campaigns to actual sell-through by channel
- Finance teams tracking actual-versus-budget performance who need consistent, timely revenue data without waiting for month-end reconciliation
- Executive leadership seeking a single dashboard view of the omni-channel business rather than a slide deck assembled from eight different exports
Ideal for: consumer products companies, CPG brands, DTC brands expanding into retail, marketplace sellers operating across multiple platforms, and any organization where retail revenue flows through more channels than any single team can manually track.

Development Due Diligence AI Agent
Enter an address or parcel ID and receive a comprehensive due diligence report covering zoning, environmental, title, tax, demographics, and comparable sales.
One address. One click. Complete site intelligence.
You know the drill. A new site comes across your desk — maybe a broker sent it over, maybe your land team flagged it, maybe an owner reached out directly. Before anyone can make an informed decision about whether to pursue it, someone needs to pull zoning records, check environmental history, review title, look up tax assessments, analyze demographics, and run comparable sales. That someone is usually a junior analyst who spends two to five days assembling a report from ten different county websites, GIS systems, environmental databases, and MLS platforms. And even after all that work, the report format varies depending on who compiled it, important details get missed depending on which databases they remembered to check, and the development team still has follow-up questions that require going back to the same sources.
The Development Due Diligence Agent eliminates all of that. You enter an address or parcel ID. The agent queries every connected data source simultaneously, compiles the results into a standardized report with risk scoring and development feasibility analysis, and delivers it in minutes. Every site gets the same depth of analysis. Every report follows the same structure. Every data source is checked every time.
Benefits
This agent transforms site due diligence from a multi-day research project into an on-demand intelligence service that delivers consistent, comprehensive reports from a single input.
- Minutes instead of days: A complete due diligence report that previously required two to five days of analyst research generates in minutes from a single address or parcel ID entry
- Consistent depth every time: Every site evaluation checks the same data sources, applies the same risk criteria, and follows the same report structure — no more variability based on who compiled it or which databases they remembered to check
- Comprehensive data coverage: Zoning, environmental history, title records, tax assessments, demographic profiles, comparable sales, flood zone status, and utility availability — all pulled automatically from connected sources
- Risk scoring: Each report includes a composite risk score based on environmental flags, zoning restrictions, title encumbrances, and development feasibility factors — giving deal teams a quick read on site viability before investing further resources
- Standardized output: Reports follow a consistent template that development teams, lenders, and investors expect, eliminating the reformatting and restructuring that ad-hoc research requires
- Portfolio-scale screening: Evaluate dozens of potential sites in a single day instead of committing analyst weeks to sequential deep dives, enabling a much wider initial screening funnel
Problem Addressed
Real estate development due diligence is fundamentally a data aggregation problem. The information exists — zoning codes are public, environmental records are searchable, tax assessments are filed, title history is recorded, demographics are published, and comparable sales are tracked. The problem is that this information lives in ten or more disconnected systems, each with its own interface, search methodology, and output format. An analyst performing due diligence on a single site might visit the county assessor website, the zoning department portal, the state environmental database, a title search service, the Census Bureau, a GIS platform, and an MLS system before having enough data to write the first section of the report.
The time cost is significant, but the quality cost is worse. When an analyst is checking ten sources under a deadline, some sources get thorough searches and others get cursory checks. Environmental history might get a deep review while flood zone status gets a quick glance. The report that reaches the development committee reflects not just the site’s characteristics but also the analyst’s time constraints, source familiarity, and individual judgment about what to prioritize. Two analysts evaluating the same site will produce reports with different depth, different emphasis, and potentially different conclusions.
What the Agent Does
The agent operates as an automated site intelligence engine that converts a single address or parcel ID into a comprehensive, standardized due diligence report:
- Address/parcel resolution: Accepts a street address, APN, or parcel ID and resolves it to precise geographic coordinates and jurisdictional boundaries for targeted data queries
- Multi-source data retrieval: Simultaneously queries connected data sources for zoning classification, permitted uses, environmental records, title history, tax assessment, demographic profile, comparable sales, flood zone designation, and utility availability
- Data normalization: Converts disparate source formats into a unified data model — zoning codes from different jurisdictions are mapped to standardized use categories, tax values are normalized to per-square-foot metrics, and demographic data is structured for development feasibility analysis
- Risk scoring: Applies a composite scoring model that evaluates environmental contamination risk, zoning compatibility with intended use, title encumbrance severity, flood exposure, and infrastructure adequacy
- Report assembly: Generates a structured due diligence report with executive summary, property profile, zoning analysis, environmental assessment, title summary, financial analysis (tax + comps), demographic context, and risk matrix
- Feasibility analysis: Based on the assembled data and intended development type, provides a preliminary feasibility assessment including estimated development costs, comparable project performance, and key risk factors to investigate further
Standout Features
- Single-input simplicity: The entire workflow starts from one field — enter an address or parcel ID and the agent handles everything else. No forms to fill out, no sources to select, no parameters to configure
- Jurisdiction-aware queries: Automatically identifies the county, municipality, and special district jurisdictions for the parcel and routes queries to the correct data sources for each — critical when operating across multiple markets
- Comparable sales analysis: Pulls recent sales of similar properties within configurable radius and property type criteria, calculating price-per-square-foot benchmarks and market trend indicators
- Environmental red flag detection: Scans environmental databases for brownfield designations, underground storage tanks, hazardous waste sites, and remediation history within the parcel and surrounding area
- Report versioning: Maintains a history of all reports generated for each parcel, enabling teams to see how site conditions and market data have changed between evaluation periods
Who This Agent Is For
This agent is built for real estate professionals who evaluate potential development sites and need comprehensive, consistent due diligence without the multi-day research timeline.
- Development analysts who currently spend days compiling site research from disconnected public and commercial data sources
- Acquisitions teams screening multiple potential sites who need to evaluate more opportunities in less time
- Development directors who want every site evaluation to meet the same depth and quality standard regardless of which analyst performs it
- Lenders and investors who require standardized due diligence documentation before committing capital to a project
- Land brokers who want to provide clients with comprehensive site intelligence as a value-added service
Ideal for: real estate developers, land acquisition firms, commercial real estate brokerages, REITs, construction companies evaluating new projects, municipal planning departments, and any organization where site selection decisions depend on aggregating data from multiple disconnected public and commercial sources.

Legal Review AI Agent
Reviews contracts for risk clauses, compliance issues, and non-standard terms, then routes severity-scored findings through structured review workflows.
Every clause checked. Every risk scored. Every finding routed.
Contract review at scale is a pattern recognition problem that most legal departments solve with the most expensive pattern recognizer available: attorney hours. An associate reads through a 40-page vendor agreement, mentally checking each clause against the organization’s risk policies, flagging non-standard terms, and noting compliance requirements. It works. It is also slow, inconsistent across reviewers, and economically unsustainable when contract volume exceeds the team’s capacity. The Legal Review Agent applies the same analytical framework systematically to every document. Built natively in Domo using Agent Catalyst, Workflows, Filesets, and Task Center, the agent ingests contracts from a governed document repository, scans every clause against configurable risk patterns and compliance requirements, assigns severity scores to each finding, and routes results through a structured review workflow where attorneys focus on the items that need judgment rather than reading every page of every agreement.
Benefits
This agent restructures legal review from a sequential, read-everything process into a risk-prioritized workflow where AI handles the scanning and humans handle the judgment calls.
- Systematic risk detection: Every contract is scanned against the full library of risk patterns and compliance requirements — no clause is skipped because the reviewer was tired at page 37
- Severity-scored findings: Each flagged item includes a severity classification (critical, high, medium, low) with the specific clause text, the rule it triggered, and a recommended action — reviewers know exactly where to focus
- Consistent standards: The same risk rules apply to every contract regardless of which attorney reviews it, eliminating the reviewer-dependent variability that creates compliance gaps
- Attorney time optimization: Associates spend their time on high-severity findings that require legal judgment rather than reading routine clauses that match standard templates
- Compliance traceability: Every scan, finding, severity score, and review decision is logged with timestamps, creating an auditable record that demonstrates systematic due diligence
- Faster contract cycle: Contracts that would sit in the review queue for days get their initial risk assessment in minutes, accelerating the entire procurement and vendor onboarding timeline
Problem Addressed
Legal departments face an impossible scaling equation: contract volume grows with business complexity, but adding attorneys is expensive and slow. The result is a review bottleneck where contracts wait in queue for days or weeks, procurement timelines slip, and business teams work around the process by accepting terms without proper review. When everything is urgent, nothing gets the attention it deserves.
The quality risk is equally concerning. Manual review is inherently variable. One attorney might flag an indemnification clause that another considers standard. A non-standard liability cap might be caught in a focused morning review session but missed during an exhausted late-afternoon pass through the same type of agreement. Without systematic scanning, the organization’s risk exposure depends on which attorney reviewed which contract on which day — a compliance lottery that no general counsel would accept if they quantified it.
What the Agent Does
The agent operates as a systematic contract scanning and risk routing engine:
- Document ingestion: Contracts uploaded to the governed FileSet repository are automatically queued for review, supporting PDF, Word, and structured text formats with OCR for scanned documents
- Clause extraction: The agent parses each document into individual clauses, identifying section boundaries, defined terms, and cross-references to build a structured representation of the agreement
- Risk pattern matching: Each clause is evaluated against a configurable library of risk patterns: non-standard indemnification, unlimited liability, auto-renewal terms, unilateral amendment rights, restrictive IP assignment, inadequate termination provisions, and more
- Severity scoring: Findings are classified by severity based on the risk type, the deviation from standard terms, and the financial exposure implied — critical findings surface immediately while informational items are logged for reference
- Review routing: Task Center assignments deliver findings to the appropriate reviewer based on contract type, risk category, and severity level — senior counsel gets critical items, associates handle standard deviations
- Resolution tracking: Reviewers document their decision (accept risk, negotiate change, reject term) directly in the workflow, creating a complete record of how each finding was addressed
Standout Features
- Customizable risk library: Organizations define their own risk patterns and severity thresholds — what constitutes a critical finding for a healthcare company differs from a technology vendor, and the rule library reflects those differences
- Clause comparison: When a non-standard term is detected, the agent shows the standard language side-by-side with the contract language, making it immediately clear what the deviation is and how significant it is
- Contract type classification: The agent automatically identifies the contract type (NDA, MSA, SOW, vendor agreement, lease) and applies the appropriate risk rules for that category rather than using a one-size-fits-all scan
- Precedent tracking: Records how similar findings were resolved in past contracts, giving current reviewers visibility into organizational precedent — if the same clause was accepted three times before, that context informs the current decision
- Volume analytics: Dashboards show contract review throughput, average findings per contract, severity distribution, and resolution time trends — giving legal operations data to optimize staffing and process
Who This Agent Is For
This agent is built for legal departments where contract volume has outpaced the team’s ability to review every agreement with consistent depth and speed.
- General counsel seeking systematic risk management across all contracts rather than reviewer-dependent quality
- Legal operations managers responsible for review throughput and cycle time without proportional headcount growth
- Procurement teams waiting on legal review before vendor agreements can be executed
- Compliance officers who need documented evidence that every contract was reviewed against the organization’s risk policies
- Associates who would rather spend their time on complex negotiations than reading boilerplate clauses
Ideal for: enterprises with high contract volume, regulated industries requiring compliance documentation, organizations with distributed procurement where legal cannot review every agreement manually, and any company where contract review bottlenecks delay business operations.

Employee Time Management AI Agent
Monitors time entries across the workforce, flags anomalies like missed punches and overtime, routes exceptions through approval workflows, and generates compliance-ready reports.
Zero payroll surprises. Every exception caught before the pay cycle closes.
The results speak for themselves: payroll errors from time entry anomalies drop to near zero, HR teams reclaim hours previously spent on manual exception review, and managers receive real-time alerts instead of discovering problems during payroll processing when it is too late to fix them cleanly. The Employee Time Management Agent monitors every time entry across your workforce in real time, applying configurable rules to detect missed clock punches, unapproved overtime, scheduling conflicts, and pattern anomalies before they become payroll errors. Exceptions route automatically through manager approval workflows with full context attached, so the reviewer sees exactly what the anomaly is, why it was flagged, and what the recommended resolution is. Compliance reports generate automatically at the end of every pay period, giving HR and finance a clean, auditable record without manual compilation.
Benefits
This agent eliminates the reactive cycle of discovering time entry problems during payroll processing and replaces it with continuous, proactive detection that catches every exception before it becomes a payroll error.
- Near-zero payroll errors: Anomalies are detected and resolved in real time rather than discovered during payroll processing, eliminating the corrections, adjustments, and employee complaints that follow every pay cycle
- HR time reclaimed: Manual exception review that consumed hours every pay period is replaced by automated detection and routing — HR reviews only the items that need judgment, not every time entry
- Manager accountability: Exceptions route directly to the responsible manager with full context and recommended actions, creating clear ownership rather than a centralized HR bottleneck
- Compliance confidence: Automated reports meet labor law documentation requirements for overtime tracking, break compliance, and work hour limits — generated automatically without manual assembly
- Pattern detection: The agent identifies trends that individual reviews miss — a department consistently approaching overtime thresholds, a shift pattern creating scheduling conflicts, or a location with above-average missed punches
- Real-time visibility: Instead of a weekly or bi-weekly payroll surprise, supervisors see time entry status continuously with alerts on exceptions as they occur
Problem Addressed
In most organizations, time entry problems are discovered at the worst possible moment: during payroll processing. A missed clock punch means an employee shows zero hours for a day they worked. Unapproved overtime means a budget variance that nobody accounted for. A scheduling conflict means two employees were both clocked into the same restricted-capacity role. By the time these issues surface in payroll, the pay cycle is closing, corrections are rushed, and someone ends up with an incorrect paycheck that creates an HR ticket.
The manual prevention approach — HR staff reviewing time entries before payroll — does not scale. With hundreds or thousands of employees generating time entries daily, human review catches obvious errors but misses subtle patterns. A single missed punch is easy to spot; a department trending toward overtime thresholds over three weeks is not. And the review itself consumes HR hours that should be spent on strategic workforce management rather than data auditing.
What the Agent Does
The agent operates as a continuous time entry monitoring and exception management system:
- Real-time entry monitoring: Magic ETL ingests time entries from all clock-in systems and normalizes data across locations, departments, and employee types into a unified monitoring view
- Configurable rule engine: Agent Catalyst applies organization-specific rules — overtime thresholds, mandatory break windows, maximum consecutive hours, scheduling conflict detection, missed punch identification — to every entry as it arrives
- Anomaly classification: Each detected exception is classified by type and severity — informational (approaching overtime), warning (missed punch), or critical (labor law compliance risk) — with recommended resolution actions
- Automated approval routing: Exceptions route through Workflow-driven approval chains to the appropriate manager with full context: the employee, the anomaly, the rule violated, and the recommended action
- Notification escalation: If a manager does not act within a configurable window, the exception escalates to the next level with an urgency flag, ensuring nothing falls through the cracks before payroll closes
- Compliance report generation: At the end of each pay period, the agent automatically generates compliance documentation covering overtime hours, break adherence, work hour limits, and exception resolution history
Standout Features
- Department-level trend detection: Goes beyond individual exceptions to identify team-level patterns — a department consistently approaching overtime limits, a location with rising missed punch rates, or a shift pattern creating recurring conflicts
- Pre-payroll audit: A dedicated pre-payroll checkpoint runs all time entries through the full rule set 48 hours before processing, generating a clean/exception report that gives HR confidence before the cycle closes
- Manager self-service: Managers approve or resolve exceptions directly from notification links without logging into a separate system — one click to approve overtime, one click to request employee correction
- Multi-jurisdiction compliance: Rule sets can be configured per state, country, or labor agreement, ensuring overtime thresholds, break requirements, and work hour limits reflect local regulations
- Historical benchmarking: Compares current period exception rates against historical baselines, flagging when a location or department deviates significantly from its normal pattern
Who This Agent Is For
This agent is built for organizations where time entry accuracy directly impacts payroll costs, labor compliance, and HR operational efficiency.
- HR teams spending disproportionate time reviewing and correcting time entries before every pay cycle
- Payroll administrators who need clean, exception-free time data to process payroll without last-minute corrections
- Operations managers responsible for overtime budgets who need real-time visibility into hours worked across their teams
- Compliance officers ensuring labor law adherence across multiple jurisdictions with different overtime and break rules
- Finance teams who need accurate labor cost data without waiting for payroll adjustments to settle
Ideal for: retailers, healthcare systems, manufacturers, hospitality companies, staffing firms, and any organization with an hourly workforce large enough that manual time entry review cannot catch every exception before payroll processes.

RFP/RFI Response AI Agent
Automates RFP/RFI responses by matching questions against a governed knowledge base of past responses, product docs, and pricing, then generating consistent draft answers.
Weeks of cross-functional scrambling. Replaced by a first draft in minutes.
An RFP lands in the inbox on a Tuesday. It is 47 pages long, contains 312 questions, and the deadline is two weeks away. What follows is predictable and painful: the proposal lead creates a spreadsheet, assigns sections to product, engineering, legal, and pricing teams, sends reminder emails that go unanswered for days, collects inconsistent answers written in different voices and at different levels of detail, then spends the final weekend stitching it all together into something that looks coherent. Two weeks of elapsed time. Dozens of hours of distributed effort. And the worst part is that 80% of the questions have been answered before — in last quarter’s RFP, in the one before that, in product documentation that already exists. The knowledge is there. It is just scattered, unindexed, and inaccessible under deadline pressure.
Benefits
This agent transforms RFP/RFI response from a cross-functional scramble into a governed, knowledge-driven workflow where AI handles the first draft and humans focus on strategy and differentiation.
- Response time collapsed: What took two weeks of distributed effort now produces a complete first draft within hours, giving teams time to refine and differentiate rather than scramble to assemble
- Governed knowledge base: Every past response, product document, pricing table, and compliance statement lives in a searchable FileSet that the agent queries for every new question — no more reinventing answers from memory
- Voice consistency: Every generated response follows the same professional tone and structural standards, eliminating the patchwork quality that comes from six different people writing six different sections
- Compliance accuracy: Legal and regulatory responses are pulled from approved language in the knowledge base rather than paraphrased from memory, reducing the risk of inadvertent misstatements
- Continuous improvement: Winning responses are fed back into the knowledge base, making every future RFP draft stronger than the last based on what actually resonated with evaluators
- Cross-functional time savings: Product, engineering, and legal teams spend minutes reviewing and approving AI-generated drafts instead of hours writing from scratch for every submission
Problem Addressed
RFP and RFI responses are one of the highest-effort, most repetitive workflows in enterprise sales. Every submission requires assembling answers from multiple subject matter experts who are already busy with their primary responsibilities. The proposal lead becomes a project manager, chasing down contributors, reconciling conflicting answers, standardizing formatting, and meeting a deadline that never has enough buffer.
The deeper inefficiency is that most questions are not new. Across a year of RFP responses, the same questions about security posture, integration capabilities, pricing models, SLA commitments, and compliance certifications appear over and over with slight variations. But without a systematic way to retrieve and reuse past answers, each submission starts nearly from scratch. Teams write the same answers differently each time, creating inconsistency that evaluators notice and penalize. Meanwhile, the institutional knowledge that should make each response faster and better remains locked in previous submissions that nobody has time to search through.
What the Agent Does
The agent operates as an intelligent proposal drafting engine that matches incoming questions to the best available answers in your governed knowledge base:
- Document ingestion: Imports the RFP/RFI document and extracts individual questions, requirements, and evaluation criteria into a structured format for processing
- Knowledge base matching: For each question, searches the governed FileSet containing past responses, product documentation, pricing tables, compliance statements, and approved messaging to find the most relevant existing content
- Draft response generation: Synthesizes matched content into a coherent draft answer that addresses the specific question while maintaining consistent voice, appropriate detail level, and compliance-safe language
- Confidence scoring: Each generated response includes a confidence score indicating how well the knowledge base covered the question — high-confidence answers are ready for review, low-confidence items are flagged for subject matter expert input
- Review routing: Responses are organized by section and routed to the appropriate reviewer (product, legal, pricing, technical) with the AI draft and source citations attached for efficient approval
- Knowledge base enrichment: After submission, winning responses and reviewer edits are ingested back into the knowledge base, improving match quality for future RFPs
Standout Features
- Question deduplication: The agent recognizes when an RFP asks the same question multiple ways or splits a single topic across several questions, generating consistent answers that cross-reference rather than contradict each other
- Source citation: Every generated response includes links to the specific documents, past submissions, or product pages that informed the answer, giving reviewers full traceability
- Multi-format output: Generates responses in the format the RFP requires — spreadsheet cells, narrative paragraphs, or structured compliance matrices — without manual reformatting
- Pricing table integration: Pulls current pricing directly from governed datasets rather than requiring manual lookup, ensuring quotes reflect the latest approved rates and discount structures
- Win/loss learning: Tracks which proposals won and which lost, identifying response patterns that correlate with success so future drafts can emphasize proven approaches
Who This Agent Is For
This agent is designed for organizations that respond to formal procurement requests regularly enough that the manual process has become a bottleneck on revenue capacity.
- Proposal managers coordinating multi-team RFP responses who need a faster path from questions to first draft
- Sales teams that lose deals to competitors who simply respond faster with more polished submissions
- Product and engineering teams tired of writing the same capability descriptions for every new RFP
- Legal and compliance teams who need approved language used consistently rather than paraphrased differently each time
- Revenue operations leaders who see RFP response capacity as a constraint on pipeline throughput
Ideal for: enterprise software companies, professional services firms, government contractors, healthcare providers, financial institutions, and any organization where RFP volume exceeds the team’s ability to respond manually without sacrificing quality or missing deadlines.

Inventory Reorder AI Agent
Monitors real-time stock levels, applies demand forecasting to predict depletion timelines, and auto-generates purchase orders before stockouts occur.
Never stockout. Never overorder. Always right-sized.
If you have ever walked into a Monday morning planning meeting and learned that a key SKU ran out over the weekend, you know the feeling. The scramble to expedite, the lost sales, the customer apologies. And the worst part is that the data was there — the depletion trend was visible weeks ago if anyone had been watching. The Inventory Reorder Agent watches for you. Built natively in Domo with Magic ETL, Workflows, Agent Catalyst, and AppDB, it connects to your real-time inventory data, applies demand forecasting models to every SKU and location, and generates purchase orders or reorder alerts before stock levels hit critical thresholds. The reorder points are not static numbers set once a year — they adapt continuously based on actual consumption patterns, seasonal trends, and lead time variability.
Benefits
This agent replaces reactive inventory management with a predictive system that keeps stock levels optimized across every location without manual monitoring.
- Predictive reorder timing: Purchase orders trigger based on forecasted depletion curves rather than static min/max thresholds, accounting for demand velocity changes that fixed reorder points miss entirely
- Stockout prevention: Continuous monitoring across all SKUs and locations means depletion warnings surface days or weeks before a stockout, giving procurement enough lead time to act without expediting
- Dynamic safety stock: Safety stock levels adjust automatically based on demand variability and supplier lead time reliability — tighter for stable items, wider for volatile ones
- Auto-generated purchase orders: When reorder thresholds are crossed, the agent generates purchase orders with calculated optimal quantities factoring in MOQs, price breaks, and warehouse capacity
- Multi-location visibility: A single view across all warehouses and stores shows which locations need replenishment, enabling transfer recommendations between overstocked and understocked sites
- Reduced carrying costs: By ordering the right quantity at the right time instead of over-ordering for safety, total inventory carrying costs decrease while service levels improve
Problem Addressed
Most inventory reorder systems operate on fixed thresholds — when stock hits a predetermined level, a reorder is triggered. This sounds reasonable until you realize that demand is not fixed. A SKU that sells 100 units per week in summer might sell 30 per week in winter, but the reorder point stays the same year-round. The result is a cycle of stockouts during high-demand periods and overstock during low-demand periods, both of which cost money.
The manual alternative is even worse. Planners review spreadsheets, eyeball trends, and make judgment calls about what to order and when. This works for a small catalog, but at scale — hundreds or thousands of SKUs across multiple locations — human attention cannot keep up. Items slip through the cracks, orders go out late, and the business absorbs the cost of lost sales and expedited shipping without ever quantifying how much the broken process is costing them.
What the Agent Does
The agent operates as a continuous demand-aware inventory optimization system:
- Real-time stock monitoring: Magic ETL ingests inventory levels across all locations and SKUs, maintaining a live view of current stock, committed orders, and available-to-promise quantities
- Demand forecasting: Applies time-series forecasting to historical consumption data, factoring in seasonality, trends, and recent velocity changes to project when each SKU will hit its reorder threshold
- Dynamic threshold calculation: Reorder points and safety stock levels are recalculated continuously based on current demand patterns and supplier lead time performance — not set annually and forgotten
- Purchase order generation: When projected stock-on-hand crosses the dynamic reorder point, the agent auto-generates a purchase order with optimal quantities factoring in MOQs, price breaks, lead times, and warehouse capacity constraints
- Alert routing: Notifications flow to the appropriate procurement team member based on SKU category, supplier assignment, and urgency level, ensuring the right person acts on the right items
- Transfer recommendations: Before triggering new purchase orders, the agent checks if other locations have excess stock that could be transferred, reducing total inventory investment across the network
Standout Features
- Adaptive forecasting: The demand model continuously recalibrates based on actual consumption, automatically detecting trend shifts and seasonal pattern changes without manual model retraining
- Supplier lead time learning: Tracks actual vs quoted lead times per supplier, adjusting reorder timing based on real delivery performance rather than catalog estimates
- Multi-constraint optimization: Purchase order quantities balance minimum order quantities, volume price breaks, warehouse capacity limits, and cash flow constraints simultaneously
- Exception-first dashboard: Instead of showing every SKU, the interface surfaces only the items that need attention — approaching reorder, stockout risk, excess stock, or supplier delay — so planners focus on what matters
- What-if scenario modeling: Planners can simulate demand changes or supplier disruptions to see how reorder timing and quantities would adjust, enabling proactive planning for known upcoming events
Who This Agent Is For
This agent is built for operations and procurement teams who are tired of discovering stockouts after they happen and overordering to compensate.
- Inventory planners managing hundreds or thousands of SKUs who cannot manually monitor every item every day
- Procurement teams who want purchase orders generated automatically with the right quantities at the right time
- Operations managers responsible for service levels who need confidence that stock will be available when customers order
- Finance teams looking to reduce carrying costs and working capital tied up in excess inventory
- Supply chain directors managing multi-location networks who need transfer-before-purchase intelligence
Ideal for: retailers, distributors, manufacturers, e-commerce companies, food service operators, and any organization where inventory availability directly impacts revenue and customer satisfaction.

Freight Quote Aggregator AI Agent
Pulls quotes from multiple freight carriers via API, normalizes rate structures, compares across cost, transit time, and service level, and recommends optimal shipping selections.
Every carrier. Every rate. One decision engine.
When a shipment needs to move, the traditional process involves emailing or calling multiple freight carriers, waiting for rate quotes to come back in different formats, and then manually normalizing everything into a comparison spreadsheet. By the time the best option is identified, hours have passed and rates may have already shifted. The Freight Quote Aggregator eliminates this entirely. Built natively in Domo using Workflows, Connectors, Agent Catalyst, and Code Engine, the agent connects to multiple carrier APIs simultaneously, pulls real-time quotes, normalizes every rate into a unified structure, and scores each option across cost, transit time, reliability history, and service level. The result is a ranked recommendation delivered in seconds rather than hours, with full transparency into why each carrier was scored the way it was.
Benefits
This agent transforms freight procurement from a manual, relationship-driven process into a data-driven optimization engine that operates at the speed of your logistics operation.
- Multi-carrier comparison in seconds: Simultaneously queries rate APIs across all connected carriers, eliminating the sequential email-and-wait cycle that delays every shipment decision
- Normalized rate structures: Converts varying carrier pricing formats — per-mile, per-hundredweight, flat rate, fuel surcharges, accessorial fees — into a unified comparison framework so every quote is apples-to-apples
- Composite scoring algorithm: Each quote is scored across four dimensions: total landed cost, estimated transit time, carrier reliability rating, and service level match, producing a single recommendation with full scoring transparency
- Real-time rate accuracy: Quotes are pulled live from carrier systems rather than cached or estimated, ensuring decisions are based on current market pricing
- Automated lane optimization: Identifies patterns across shipping lanes where certain carriers consistently outperform, building institutional knowledge into every future recommendation
- Complete audit trail: Every quote request, carrier response, scoring calculation, and final selection is logged for procurement review and carrier negotiation leverage
Problem Addressed
Freight procurement in most organizations operates on a combination of habit, relationships, and manual comparison. A logistics coordinator receives a shipment request, reaches out to two or three preferred carriers, waits for quotes that arrive in different formats and timelines, manually enters numbers into a spreadsheet, and makes a selection based on incomplete data under time pressure. The process works when volume is low and relationships are stable, but it breaks down as shipment frequency increases, new lanes open, or market rates fluctuate.
The deeper problem is invisible: without systematic comparison across all available carriers for every shipment, organizations overpay on freight consistently without knowing it. The coordinator picks the carrier who responds fastest or the one they have the best relationship with, not necessarily the one offering the best combination of cost and service for that specific lane and timeline. Over thousands of shipments per year, this adds up to significant unnecessary logistics spend with no mechanism to detect or correct it.
What the Agent Does
The agent operates as an automated freight procurement engine that handles the full quote-to-recommendation cycle:
- Shipment intake: Receives shipment parameters including origin, destination, weight, dimensions, commodity type, and required delivery window from the requesting system or user input
- Multi-carrier API queries: Simultaneously connects to all configured carrier rate APIs via Domo Connectors, submitting the shipment parameters and receiving real-time rate quotes
- Rate normalization: Code Engine processes each carrier response, extracting base rates, fuel surcharges, accessorial fees, and service commitments into a standardized schema for direct comparison
- Composite scoring: Agent Catalyst applies the weighted scoring algorithm across cost (40%), transit time (25%), reliability (20%), and service level (15%), producing a ranked recommendation list
- Recommendation delivery: Top-scored options are presented with full transparency — total cost breakdown, estimated transit, reliability score, and the reasoning behind the ranking
- Historical pattern analysis: Over time, the agent builds lane-level performance profiles for each carrier, enriching future scoring with actual delivery performance data rather than relying solely on quoted estimates
Standout Features
- Carrier-agnostic architecture: Add any freight carrier with an API — LTL, FTL, parcel, intermodal — without modifying the scoring logic. The normalization layer handles format differences automatically
- Configurable scoring weights: Organizations can adjust the cost-vs-speed-vs-reliability balance based on their priorities — a pharmaceutical shipper weights reliability higher than a commodity shipper optimizing for cost
- Lane intelligence: The agent tracks actual carrier performance by lane over time, automatically adjusting reliability scores based on on-time delivery rates rather than carrier-reported estimates
- Exception handling: When a carrier API is unavailable or returns an error, the agent proceeds with available quotes and flags the gap rather than blocking the entire recommendation
- Procurement negotiation data: The historical quote database becomes a powerful tool for annual carrier negotiations, showing exactly where each carrier won and lost business and at what price points
Who This Agent Is For
This agent is designed for any organization where freight costs represent a material spend category and the current quoting process relies on manual comparison or carrier favoritism.
- Logistics coordinators managing daily shipment routing decisions across multiple carrier relationships
- Procurement teams seeking data-driven freight cost optimization without adding headcount
- Supply chain directors who need visibility into carrier performance and spend allocation across lanes
- Operations managers shipping from multiple facilities who need consistent carrier selection logic across locations
- Finance teams looking to identify and reduce freight cost leakage across the organization
Ideal for: manufacturers, distributors, retailers, 3PLs, food and beverage companies, and any organization shipping frequently enough that a few percentage points of freight savings creates meaningful bottom-line impact.

Inventory Movement Optimizer AI Agent
AI-powered palletizer balancing system that analyzes inventory distribution across warehouse lanes, generates scored move recommendations with distance costs, and activates automated evacuation protocols when equipment goes offline.
400% ROI. Every lane balanced. Every move scored.
On a cold storage production floor, palletizer balance is not a nice-to-have. It is the difference between a smooth shift and a cascade of manual interventions that eat into throughput, increase product handling risk, and leave supervisors making gut decisions under time pressure. A national cold storage and logistics operator deployed this Domo-powered inventory movement optimizer to replace exactly that kind of manual, judgment-based palletizer balancing. The custom ProCode application ingests live batch inventory data, maps the current distribution state across every active palletizer lane, identifies imbalances using a multi-factor scoring algorithm, and generates prioritized move recommendations that specify exactly which dispatch load unit to move, from which source lane, to which destination, and at what distance cost. The result is a production floor where every palletizer lane carries a balanced load, supervisors have real-time decision support instead of guesswork, and every move is logged in an immutable history for operational review.
Benefits
This system transforms palletizer management from reactive manual balancing into a governed, data-driven optimization loop that delivers measurable throughput improvements from the first shift.
- 400% measured ROI: The optimization algorithm delivers four times the return on investment by reducing manual moves, minimizing product handling, and maximizing palletizer utilization across every production cycle
- Normalized product distribution: Before the optimizer, some lanes carried 350+ units while others held fewer than 50. After optimization, distribution is balanced across all active lanes, eliminating bottlenecks and idle capacity simultaneously
- Scored move recommendations: Every suggested move includes a composite score factoring balance improvement, distance cost, source excess, and destination need — supervisors see exactly why each move is recommended and how much value it delivers
- Automated evacuation protocols: When a palletizer lane goes offline for maintenance or breakdown, the system automatically generates evacuation moves to redistribute all inventory before equipment goes down — no manual coordination required
- Immutable move history: Every executed move — whether suggested, manual, or evacuation — is logged with full context including source, destination, distance, score, and timestamp, creating a complete audit trail for operational review
- Real-time before/after visualization: Supervisors see the starting inventory state alongside the current state after executed moves, making the optimization impact immediately visible and verifiable
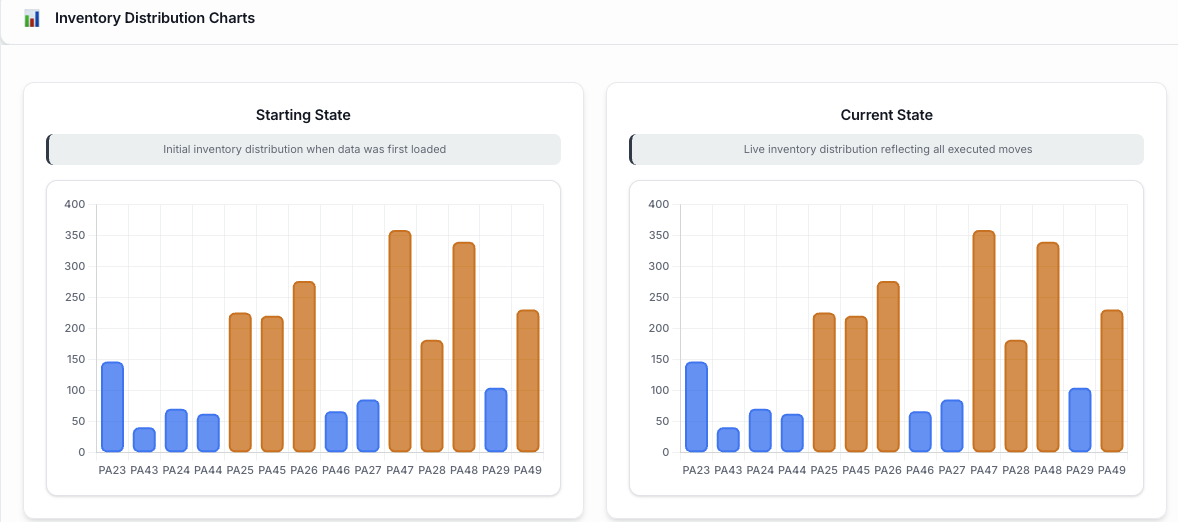
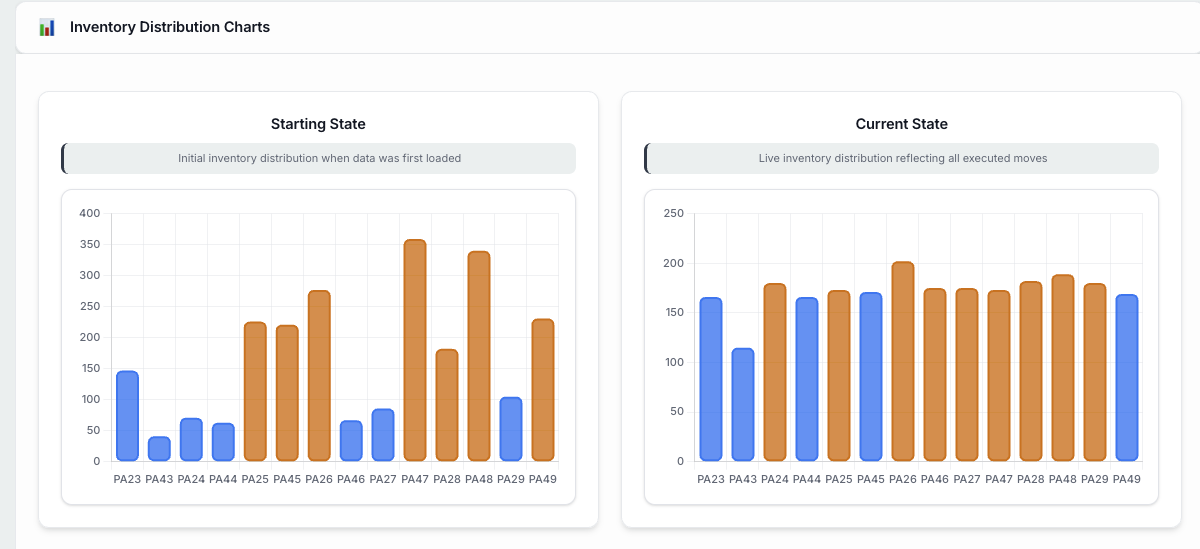
Problem Addressed
In cold storage warehouses running high-volume batch production, palletizer lanes accumulate inventory at uneven rates. Some lanes end up overloaded while others sit nearly empty. The traditional response is manual assessment — a supervisor walks the floor, eyeballs the distribution, and makes judgment calls about which units to move where. This approach is slow, inconsistent, and leaves no record of what was moved or why. During shift changes, the next supervisor starts from scratch with no visibility into what decisions were already made.
The problem compounds when equipment goes offline. If a palletizer needs maintenance or breaks down unexpectedly, every dispatch load unit on that lane needs to be evacuated to other active lanes before work can proceed. Without an automated protocol, this evacuation is chaotic — units get moved to whatever lane has space rather than where they would best balance the overall distribution. The result is a floor that was already imbalanced becoming even more so, with cascading effects on throughput for the rest of the shift.
What the Agent Does
The optimizer operates as a continuous balancing engine that monitors, analyzes, and recommends inventory movements across the entire production floor:
- Live inventory ingestion: Connects to batch inventory data and maps the current dispatch load unit count, status, and distribution across every active palletizer lane in real time
- Imbalance detection: Compares each lane against the target balance average, identifying lanes that are over-allocated (too much inventory) and under-allocated (need more) with precise deviation metrics
- Multi-factor move scoring: Generates move recommendations using a composite algorithm that weighs balance improvement (70%), distance cost (20%), and size fit (10%), with bonus points for filling empty lanes and applying progressive criteria strictness
- Evacuation protocol activation: When a lane goes offline, automatically generates evacuation moves that redistribute all inventory to active lanes while respecting distance limits and maintaining overall floor balance
- Move execution and tracking: Supervisors can execute suggested moves individually or in batch, with every action logged to an immutable move history including move type (suggested, manual, evacuation), score, distance, and timestamp
- Before/after state comparison: Maintains both the starting inventory state and the current live state, enabling supervisors to see exactly how optimization moves have changed the distribution profile
Standout Features
- Progressive criteria system: The scoring algorithm tries strict criteria first (requiring significant balance improvement), then medium criteria, then loose criteria — ensuring the best possible moves are recommended before falling back to acceptable alternatives
- Distance-cost optimization: Every move recommendation includes the physical distance between source and destination lanes, scored on a 1-5 scale where closer moves earn higher scores, minimizing unnecessary product travel across the warehouse floor
- Three move types: Suggested moves optimize balance, evacuation moves handle offline lanes, and manual moves give supervisors full override control — all tracked in the same history with move type classification
- Emergency mode prioritization: Evacuation moves always take priority over optimization moves, with maximum emergency moves per offline lane, no distance restrictions, and automatic activation when lane status changes
- Undo and simulation: Supervisors can undo the last move or reset the entire simulation to starting state, enabling what-if analysis before committing to a move sequence on the physical floor
Who This Agent Is For
This optimizer is built for warehouse operations teams managing high-volume production floors where palletizer balance directly impacts throughput, product handling quality, and shift efficiency.
- Warehouse supervisors making real-time decisions about inventory movement across palletizer lanes during active production shifts
- Production floor managers responsible for throughput targets who need data-driven optimization instead of manual assessment
- Operations directors seeking visibility into move history, balance metrics, and evacuation protocol compliance across facilities
- Maintenance coordinators who need automated evacuation protocols when equipment goes offline for planned or unplanned service
- Continuous improvement teams analyzing move history data to identify patterns, optimize lane configurations, and reduce unnecessary product handling
Ideal for: cold storage operators, warehouse production managers, logistics companies, food and beverage distribution centers, and any operation where balanced palletizer utilization directly drives throughput and efficiency.
Live Tournament Tracker AI Agent
Real-time tournament tracking application that auto-computes standings, bracket progressions, and team analytics across 20 nations and 47 games — with automatic score updates from external sources.
47 games. 20 nations. One app. Always current.
This application was built to follow the 2026 World Baseball Classic without bouncing between five different websites to piece together what was happening. Pool standings on one site, bracket results on another, team stats somewhere else. A single Domo app handles everything — and the moment that made it worth every hour was when the system was triggered to check for the championship game score at 11:02 PM. It went out to the web, found the final score, updated the dataset, refreshed every visualization in the app, and published. Venezuela 3, United States 2. Opening the app the next morning revealed everything was already there. No manual entry, no copy-paste, no waiting for someone to update a spreadsheet. That is what real-time means.
Benefits
This application transforms how tournament data reaches the people who care about it, whether they are casual fans checking scores or operations staff coordinating logistics across four international venues.
- Always-current standings: Pool standings, advancement status, and elimination tags update the instant a game result enters the dataset — no refresh button, no waiting for a batch process, no stale data
- Automatic score ingestion: The app fetches scores from external web sources on schedule, updates the underlying dataset, and publishes changes without any human intervention — even at 11:02 PM on championship night
- Complete bracket visualization: Quarterfinals, semifinals, and championship results render automatically as games complete, showing the full tournament progression from pool play through the final
- Team-level drill-down: Click any nation to see their complete tournament run — every game, every opponent, every score, win-loss record, and pool assignment in one view
- Multi-venue coverage: Four pool sites across three countries (San Juan, Houston, Tokyo, Miami) tracked simultaneously with venue-specific scheduling and results
- Filterable game history: Surface any matchup by round type — pool play, quarterfinals, semifinals, or championship — or view the complete 47-game history chronologically
Problem Addressed
Following an international tournament across four time zones and twenty teams should not require a spreadsheet and six browser tabs. But that is exactly what most fans and analysts resort to during events like the World Baseball Classic. Official sites update slowly. Third-party trackers show standings but not brackets. Box scores live on one platform while team records live on another. By the time you have pieced together what happened overnight in Tokyo, the Houston games are already underway.
For operations staff coordinating across venues, the fragmentation is worse. Advancement scenarios change with every result, travel logistics depend on bracket outcomes, and broadcast schedules shift based on which teams advance. There was no single source that combined standings, brackets, schedules, team profiles, and game results into one always-current view — until now.
What the Agent Does
The application connects to a live game results dataset and performs all tournament logic computationally, eliminating manual standings management entirely:
- Standings computation: Calculates wins, losses, games played, runs scored, runs allowed, and run differential for every team in every pool, automatically determining advancement and elimination status
- Bracket generation: Renders the knockout stage bracket from quarterfinals through championship based on actual game results, updating progressions as each round completes
- Automatic score updates: On a configurable schedule, fetches game results from external web sources, parses scores, updates the Domo dataset, and triggers app refresh — all without manual intervention
- Team profile aggregation: Compiles per-nation tournament summaries including pool assignment, venue location, complete game-by-game results, and final tournament placement
- Round-based filtering: Enables users to isolate games by tournament phase — pool play, quarterfinals, semifinals, or championship — for focused analysis
- Multi-pool management: Tracks four simultaneous pools across four international venues with independent standings, tiebreaker logic, and advancement rules
Standout Features
- Zero-touch score updates: The championship game score was captured automatically at 11:02 PM — fetched from the web, written to the dataset, app refreshed, and published with no human involvement whatsoever
- 20-nation team cards: Every participating country gets a visual card showing flag, pool assignment, venue, record, and tournament status (Champion, Runner-Up, Semifinalist, QF Eliminated, Pool Stage)
- Single governed card: Pool standings, bracket visualization, game history, and team analytics all live in one Domo card — no cross-referencing, no context switching, no stale secondary sources
- Real-time bracket progression: As quarterfinal and semifinal results are posted, the bracket visualization updates immediately to show advancing teams and upcoming matchups
- Built as a ProCode app: Demonstrates that a single developer can build a production-quality, real-time sports analytics application entirely within Domo using ProCode, datasets, and scheduled workflows
Who This Agent Is For
This application serves anyone who needs a unified, real-time view of a multi-venue tournament without piecing together information from scattered sources.
- Sports fans who want standings, brackets, and team profiles in one place without refreshing multiple sites
- Sports analysts tracking advancement scenarios, run differentials, and matchup history across pools
- Tournament operations staff coordinating logistics that depend on real-time bracket outcomes
- Broadcast and media teams planning coverage based on which teams advance and when
- Developers and builders looking for a reference implementation of a real-time ProCode application powered by Domo
Ideal for: sports organizations, tournament operators, media companies, analytics teams, and any builder who wants to see what a single developer can ship with Domo ProCode and live data connectivity.

Enterprise AI/ML Demo Suite AI Agent
A proof-of-concept suite of four Domo-on-Snowflake demonstrations showcasing AI/ML models across fraud detection, call center optimization, flight operations analytics, and predictive maintenance for enterprise stakeholders.
Benefits
Enterprise stakeholders evaluating AI/ML capabilities need more than slide decks and theoretical architectures. They need to see working models applied to their specific operational domains with real data structures, actual prediction outputs, and interactive dashboards that demonstrate end-to-end value. This demonstration suite provides exactly that: four distinct AI/ML proof-of-concept applications built on Domo-on-Snowflake architecture, each targeting a different operational challenge within a major commercial airline environment.
- Concrete proof of AI/ML capability: Each of the four demonstrations moves beyond abstract AI promises by showing working models producing actual predictions and classifications on domain-specific data, giving stakeholders tangible evidence of what the technology can deliver in their operational context
- Architecture validation: The suite proves that Domo-on-Snowflake can serve as a unified platform for enterprise AI/ML applications, with Snowflake providing the data foundation and Domo delivering the model management, visualization, and interactive experience layers
- Multi-domain applicability: By spanning four distinct operational areas including fraud detection, call center optimization, flight operations, and predictive maintenance, the suite demonstrates that the same architectural pattern scales across fundamentally different use cases without requiring separate technology stacks per domain
- Accelerated evaluation cycles: Stakeholders who would typically require months of vendor evaluation and pilot development can see working AI/ML applications in days, compressing the decision timeline from theoretical assessment to evidence-based commitment
- End-to-end visibility: Each demonstration traces the complete path from raw data ingestion through model training and inference to actionable dashboard output, showing stakeholders the full pipeline rather than just the model accuracy metrics that tell only part of the story
- Reduced proof-of-concept risk: Building demonstrations on an established platform architecture eliminates the risk of custom-built POCs that work in the lab but fail to scale, because the underlying infrastructure is already production-grade
Problem Addressed
A major commercial airline needed to evaluate whether Domo-on-Snowflake could power enterprise-scale AI/ML applications across its operations. The challenge was not a single use case but a cross-domain question: could one platform architecture handle the fundamentally different data structures, model types, and output requirements of fraud detection, call center optimization, flight operations analytics, and predictive maintenance? Existing approaches required separate technology stacks for each domain, creating siloed implementations that were expensive to build, difficult to maintain, and impossible to compare against a unified standard.
The airline's stakeholders needed to see concrete demonstrations, not architectural diagrams. They needed working AI/ML models producing real predictions on representative data, displayed through interactive dashboards that showed the full pipeline from data to decision. Without this proof of concept, the conversation about enterprise AI/ML adoption would remain theoretical, with each department continuing to evaluate point solutions independently rather than converging on a unified platform strategy.
What the Agent Does
The demonstration suite delivers four complete AI/ML proof-of-concept applications, each built on the same Domo-on-Snowflake architecture but tailored to its specific operational domain:
- Fraud detection demonstration: An AI/ML model trained on transactional data identifies suspicious patterns indicative of fraudulent activity, scoring transactions in real-time and presenting results through a risk dashboard where analysts can review flagged transactions, examine contributing factors, and track detection accuracy metrics
- Call center optimization demonstration: Machine learning models analyze call volume patterns, agent performance metrics, and customer interaction data to generate staffing recommendations, predict peak demand periods, and identify the conversation patterns that correlate with first-call resolution versus escalation
- Flight operations analytics demonstration: AI models process operational data including scheduling, delays, gate assignments, and resource utilization to surface efficiency opportunities, predict disruption cascades before they propagate, and provide operations teams with decision-support dashboards for real-time flight management
- Predictive maintenance demonstration: ML models trained on equipment telemetry data predict component failure probabilities, generate maintenance scheduling recommendations, and present risk-prioritized work orders through dashboards that help maintenance teams focus resources on the highest-impact interventions before failures occur
- Unified architectural layer: All four demonstrations share the same Domo-on-Snowflake foundation, with Snowflake serving as the data warehouse, Domo providing model management and data science capabilities, and interactive dashboards delivering the user experience layer for each domain
- Interactive exploration: Each demonstration supports drill-down exploration where stakeholders can examine model inputs, review prediction confidence levels, explore feature importance, and interact with the data at whatever depth their evaluation requires
Standout Features
- Four-domain proof on one platform: The most significant architectural achievement is demonstrating that fraud, call center, flight ops, and maintenance use cases all run on identical infrastructure, proving that enterprise AI/ML does not require domain-specific technology stacks and can consolidate onto a single platform
- Domo-on-Snowflake native integration: The demonstrations leverage the native connection between Domo and Snowflake, meaning data flows directly from the warehouse into model training and inference pipelines without intermediate staging layers, API integrations, or data movement that would add latency and complexity in production
- End-to-end pipeline transparency: Each demonstration exposes the full pipeline from raw data through feature engineering, model training, inference, and dashboard output, giving technical evaluators complete visibility into how predictions are generated rather than presenting AI as an opaque black box
- Model management integration: The demonstrations use built-in model management and data science capabilities for training, versioning, and deploying models, showing stakeholders that the entire ML lifecycle can be managed within the platform rather than requiring external ML infrastructure
- Production-grade architecture: Because the demonstrations are built on the same Domo-on-Snowflake stack that would power production deployment, there is no gap between the POC and the production implementation, eliminating the common problem where successful demonstrations fail to translate into working systems at scale
Who This Agent Is For
This demonstration suite serves organizations evaluating enterprise AI/ML platforms who need concrete, multi-domain proof of capability before committing to a platform strategy.
- Enterprise IT leadership evaluating whether a unified platform can handle diverse AI/ML use cases across different operational domains without requiring separate technology stacks per department
- Operations directors in aviation, logistics, or similarly complex industries who need to see AI/ML applied to their specific operational challenges before advocating for platform investment
- Data science teams assessing whether Domo-on-Snowflake can support the full ML lifecycle from data preparation through model deployment and monitoring within a single environment
- Executive stakeholders who require tangible demonstrations of AI/ML value rather than theoretical capability presentations before approving enterprise platform commitments
- Technology evaluation committees responsible for selecting platforms that can serve multiple departments and use cases without creating siloed implementations that duplicate infrastructure costs
Ideal for: Large enterprises evaluating unified AI/ML platform strategies across multiple operational domains, particularly in aviation, transportation, logistics, financial services, and other industries where fraud detection, operational optimization, and predictive maintenance represent high-value AI applications.

Supply Chain Task Management AI Agent
Custom application that connects directly to supply chain data and gives team members granular, role-based control to take action on their specific responsibilities with full audit trail and accountability.
Benefits
When supply chain tasks are scattered across spreadsheets, email threads, and disconnected systems, accountability disappears. Nobody knows who owns what. Updates get lost. Deadlines slip because the person responsible never saw the assignment. This agent eliminates that chaos by providing a single, unified application where every supply chain task is visible, assigned, tracked, and auditable, with role-based controls that ensure each team member sees exactly what they need to act on and nothing more.
- Single source of truth for all tasks: Every supply chain task, from procurement actions to production adjustments to logistics coordination, lives in one application instead of being fragmented across spreadsheets, email chains, and verbal handoffs where things inevitably fall through the cracks
- Role-based visibility and control: Team members see only the tasks relevant to their role and can modify only the fields they are authorized to change, preventing accidental overwrites and ensuring that a production lead cannot alter procurement data or vice versa
- Complete audit trail: Every action taken on every task is logged with the user, timestamp, and specific change made, creating an unbroken chain of accountability that supports compliance requirements and enables root-cause analysis when issues arise
- Faster task resolution: Because tasks are automatically routed to the right person with clear ownership and deadlines, the average time from task creation to completion drops significantly compared to the manual triage process of figuring out who should handle what
- Reduced coordination overhead: Managers who previously spent hours chasing status updates across multiple channels can now see real-time task status in a single dashboard, freeing their time for strategic decisions rather than administrative follow-up
- Scalable process enforcement: As supply chain operations grow in complexity, the role-based framework ensures that new team members, new task types, and new workflow stages can be added without breaking existing processes or requiring extensive retraining
Problem Addressed
A national food manufacturing company was managing its entire supply chain task workflow through a patchwork of spreadsheets and email threads. Production leads tracked their tasks in one spreadsheet. Procurement managed theirs in another. Logistics coordination happened primarily over email. There was no unified view of what was happening across the supply chain, no way to enforce consistent processes, and no audit trail to trace who did what and when.
The consequences were predictable and painful. Tasks fell through the cracks when emails were missed or spreadsheets were not updated. Multiple team members sometimes worked on the same issue without knowing it, while other critical tasks sat unassigned. When problems occurred, there was no way to trace the chain of decisions that led to the breakdown. Management spent disproportionate time in status meetings trying to reconstruct a picture of operations that should have been visible at a glance. The company needed a purpose-built application that connected directly to their supply chain data, enforced role-based access, and provided the accountability layer that spreadsheets and email could never deliver.
What the Agent Does
The agent provides a comprehensive supply chain task management application built directly on top of operational data:
- Direct data connectivity: The application connects directly to supply chain datasets, pulling in real-time information about orders, inventory levels, production schedules, and logistics status so that tasks are always grounded in current operational reality rather than stale snapshots
- Role-based task assignment: Tasks are automatically routed to team members based on their role, department, and area of responsibility, with configurable rules that ensure the right person receives the right task without manual triage or managerial intervention
- Controlled field modifications: Each role has specific permissions defining which task fields they can view and edit, preventing unauthorized changes while enabling team members to update the information within their scope of responsibility without bottlenecks
- Stage-based workflow tracking: Tasks progress through defined stages from creation through assignment, action, review, and completion, with status transitions enforced by the application so that steps cannot be skipped and progress is always visible
- Real-time status dashboard: Managers and directors see a live view of all active tasks across the supply chain, filterable by status, assignee, priority, and category, eliminating the need for status meetings and manual progress compilation
- Automated notifications: The application sends targeted alerts when tasks are assigned, when deadlines approach, when status changes occur, and when escalation thresholds are reached, keeping the right people informed without flooding everyone with irrelevant updates
Standout Features
- Granular permission architecture: The role-based access system goes beyond simple read/write permissions to control visibility and editability at the individual field level, meaning a logistics coordinator can update shipping status without being able to modify the procurement details on the same task record
- Live data integration: Unlike standalone task management tools that require manual data entry, this application pulls directly from operational supply chain datasets, ensuring that task context always reflects current inventory levels, order statuses, and production schedules
- Configurable workflow stages: The task progression framework supports custom stage definitions per task type, so procurement tasks can follow a different approval flow than production tasks while both are managed within the same unified application
- Built-in escalation logic: Tasks that exceed defined time thresholds or miss deadlines automatically escalate to the next management level with full context, ensuring that stuck items receive attention before they impact downstream operations
- Comprehensive action logging: Every interaction with every task is recorded in an immutable audit log that supports compliance audits, dispute resolution, and process improvement analysis with complete traceability from task creation to closure
Who This Agent Is For
This agent is purpose-built for supply chain organizations that have outgrown spreadsheet-based task management and need a structured, accountable, role-aware system to coordinate work across teams.
- Supply chain managers overseeing cross-functional operations who need unified visibility into task status across procurement, production, logistics, and quality teams
- Production leads and floor supervisors who need a clear, filtered view of their team's active tasks with the ability to update status and log actions without accessing irrelevant data
- Procurement teams coordinating vendor interactions, purchase orders, and material tracking who need task accountability tied directly to operational data
- Operations directors requiring audit trail capabilities for compliance, process improvement, and root-cause analysis when supply chain disruptions occur
- Quality assurance teams that need to track inspection tasks, corrective actions, and compliance items within the same unified workflow as the broader supply chain operation
Ideal for: Food manufacturing, consumer packaged goods, industrial supply chains, and any organization where multi-team supply chain coordination requires structured task management with role-based access controls and complete audit accountability.

Embedded Analytics Intelligence AI Agent
AI-driven embedded analytics agent that integrates live dashboards with AI-generated narrative insights directly into client-facing workflows, powered by Cloud Amplifier for native Snowflake connectivity.
Benefits
The promise of embedded analytics has always been straightforward: put the data where the decisions happen. But embedded dashboards alone only solve half the problem. Users still need to interpret what the data means, identify what changed, and determine what to do next. This agent closes that gap by pairing embedded visualizations with AI-generated narrative insights that explain the data in plain language, delivered directly within the workflows where client-facing teams already operate.
- Insights where work happens: Rather than requiring users to switch between their primary application and a separate analytics platform, this agent embeds live dashboards and AI-generated narratives directly into existing client workflows, eliminating context-switching and accelerating time-to-insight
- AI narratives that explain the numbers: Every embedded dashboard is accompanied by automatically generated written insights that translate complex data patterns into clear, actionable language, helping users who are not data analysts understand what the metrics mean for their specific portfolio or account
- Zero data movement: By leveraging Cloud Amplifier for native Snowflake connectivity, client data remains in its source warehouse without requiring ETL pipelines, data copies, or staging tables, reducing latency and eliminating the security risks associated with data duplication
- Scalable client experience: The embedded analytics framework supports multi-tenant deployment where each client sees only their own data with appropriate governance controls, enabling the same analytical experience to scale across hundreds of client relationships without custom development per account
- Always-current reporting: Because the dashboards connect directly to the live data warehouse through Cloud Amplifier, every view reflects the most recent data available without manual refresh cycles or stale reporting windows that plague traditional embedded solutions
- Reduced support burden: AI-generated narratives proactively answer the questions that users would otherwise submit as support tickets, such as why a metric changed, what is driving a trend, or how current performance compares to benchmarks, deflecting routine analytical inquiries before they reach human analysts
Problem Addressed
A global asset management firm needed to deliver analytics directly within the workflows of wealth managers, client advisors, and portfolio analysts without forcing them into a separate business intelligence platform. The existing approach required client-facing teams to log into a standalone BI tool, navigate to the relevant dashboard, interpret the data on their own, and then return to their primary application to take action. This context-switching created friction, reduced adoption, and meant that the analytical insights the firm invested heavily in producing were significantly underutilized.
The deeper problem was that even when users did access the dashboards, they often lacked the analytical fluency to extract the right conclusions. A portfolio performance chart might show a decline, but without contextual narrative explaining the contributing factors, benchmark comparisons, and suggested next steps, the dashboard became a visualization without interpretation. The firm needed embedded analytics that combined live data visualization with AI-driven explanation, all delivered without moving sensitive client data out of its Snowflake warehouse.
What the Agent Does
The agent delivers a complete embedded analytics experience with AI-powered narrative intelligence layered on top of live dashboard visualizations:
- Embedded dashboard delivery: Live analytical dashboards are embedded directly into client-facing applications using Domo Everywhere, presenting portfolio performance, risk metrics, allocation breakdowns, and trend analyses within the interface where advisors and analysts already work
- Cloud Amplifier connectivity: Rather than copying data into a separate analytics layer, Cloud Amplifier establishes a secure native connection to the Snowflake data warehouse, enabling dashboards to query live data directly with sub-second response times and zero data movement
- AI narrative generation: For each embedded dashboard view, the AI agent analyzes the underlying data and generates written narratives that explain key trends, highlight notable changes, compare performance against relevant benchmarks, and surface anomalies that warrant attention
- Contextual personalization: Narratives are tailored to the specific user context, so a wealth manager viewing a client portfolio receives insights framed around that client's objectives and risk profile, while a regional director sees aggregate commentary relevant to their oversight responsibilities
- Multi-tenant governance: The embedded experience enforces data-level security so each user sees only the data they are authorized to access, with governance rules applied automatically based on user identity and role without requiring custom filtering logic per deployment
- Continuous refresh: Both the visual dashboards and AI narratives update automatically as new data flows into Snowflake, ensuring that every interaction reflects the latest available information without manual refresh or scheduled report distribution
Standout Features
- Cloud Amplifier architecture: The native Snowflake connection through Cloud Amplifier eliminates the traditional embedded analytics bottleneck of data synchronization, enabling real-time queries against production data without ETL pipelines, staging databases, or scheduled data loads that introduce latency and maintenance overhead
- Narrative-visual pairing: Unlike traditional embedded analytics that deliver charts without context, this agent pairs every visualization with an AI-generated narrative that explains the data in domain-specific language, creating an experience where users receive both the what and the why in a single view
- White-label embedding: The embedded experience integrates seamlessly into the host application's design language, appearing as a native feature rather than a third-party widget, which drives adoption by eliminating the perception that users are leaving their primary workflow
- Dynamic insight prioritization: The AI narrative engine does not simply describe every metric; it prioritizes insights based on significance, surfacing the most important changes and trends first while providing drill-down access to supporting details for users who want deeper analysis
- Governance-aware scaling: Adding new client tenants requires only permission configuration rather than dashboard duplication, enabling rapid scaling of the embedded analytics program without proportional increases in development and maintenance effort
Who This Agent Is For
This agent delivers immediate value to any organization that needs to embed analytical experiences into client-facing or partner-facing applications while maintaining the intelligence layer that transforms raw data into actionable understanding.
- Financial services firms delivering portfolio analytics, risk reporting, or performance summaries to wealth managers and client advisors who need insights within their primary workflow
- SaaS platforms seeking to embed analytical dashboards with AI-generated insights as a value-added feature for their end users without building a custom analytics engine
- Organizations with Snowflake data warehouses that want to expose analytical views to external stakeholders without moving data out of the warehouse or managing complex ETL synchronization
- Client services teams that currently distribute static reports and want to upgrade to interactive, AI-enhanced embedded experiences that reduce analytical support requests
- Product teams building data-rich applications where the analytical layer needs to feel native to the product rather than an obvious third-party integration
Ideal for: Any organization delivering analytical experiences to external users, whether clients, partners, or customers, that needs embedded dashboards paired with AI-generated contextual insights and native cloud data warehouse connectivity.

Financial Performance Briefing AI Agent
Agent Catalyst-powered financial intelligence that transforms complex P&L data into plain-language performance summaries, enabling General Managers across multiple locations to understand and act on their financial results without navigating complex dashboards or requiring BI expertise.
General Managers run the business. They should not need to become dashboard analysts to understand how it is performing.
A national fitness and wellness company with locations across the country faced a practical problem that will be familiar to any multi-location operator: General Managers are responsible for the financial performance of their locations, but the P&L data they needed to manage that performance was locked inside complex dashboards that required significant BI expertise to navigate and interpret. These were not casual reports. P&L statements for individual locations involve dozens of line items across revenue categories, cost centers, labor metrics, and margin calculations, all with period-over-period comparisons and budget variance analysis.
The GMs who needed this information most were the least likely to have the time or technical background to extract it from a traditional analytics interface. They needed to understand their financial performance at a glance, in plain language, with the key variances and action items called out explicitly. Instead, they were spending time navigating filters, cross-referencing charts, and trying to translate what the data was telling them into operational decisions.
The Financial Performance Briefing AI Agent was built by practitioners who understood this workflow gap. It uses Agent Catalyst paired with Snowflake Cortex to generate AI-powered financial summaries that meet managers where they are, delivering the insight without requiring the analytical journey.
Benefits
This agent closes the gap between financial data availability and financial data comprehension for the people who need to act on it every day.
Problem Addressed
Multi-location businesses invest heavily in financial reporting infrastructure. They build dashboards, create standard reports, and deploy BI tools that provide access to P&L data at every level of the organization. The technology works. The data is accurate. The dashboards are well-designed. And yet, a meaningful percentage of the operational leaders who are supposed to use this data to run their locations do not engage with it effectively.
This is not a technology problem. It is a translation problem. P&L data in its native form is a structured financial document. Reading it requires understanding accounting conventions, interpreting variance calculations, distinguishing between controllable and non-controllable line items, and mentally constructing the narrative of what happened and why. For a General Manager whose primary expertise is in operations, member experience, and team leadership, this translation step is a significant barrier.
The typical organizational response is training: teach the GMs to read dashboards better. But training addresses the symptom, not the root cause. The root cause is that the data is not being presented in the format that operational leaders can most efficiently consume and act upon. They do not need more data access. They need interpreted intelligence delivered in the language they think in.
What the Agent Does
The agent operates as an automated financial intelligence layer that sits between the raw data infrastructure and the people who need to act on the insights:
Standout Features
Who This Agent Is For
This agent is built for multi-location businesses where the people responsible for P&L performance at the site level are operational leaders rather than financial analysts, and where the organization needs to democratize financial intelligence without requiring every manager to become a dashboard expert.
Ideal for: General Managers, regional directors, finance leaders, and operations executives in multi-location businesses who need to put financial intelligence into the hands of every site leader without requiring BI expertise or dashboard fluency.

Hash Rate Anomaly Mitigation AI Agent
Intelligent monitoring workflow that continuously tracks server facility performance metrics, detects low hash rate anomalies in real-time, and automatically executes predefined mitigation protocols to reduce response time from hours to seconds and minimize operational downtime.
Intelligent workflows that detect and respond to server performance anomalies before they become extended outages
A large-scale data center operator managing extensive server infrastructure faced a persistent operational challenge: hash rate drops across their facilities required rapid identification and response, but the detection-to-mitigation cycle relied heavily on manual monitoring and human-initiated intervention. When a facility experienced a low hash rate event, the operations team needed to first detect the anomaly through dashboard monitoring, then diagnose the probable cause, and finally execute the appropriate mitigation steps. This sequence, when performed manually, introduced response latencies measured in hours rather than seconds, and each hour of degraded performance translated directly into lost computational output and revenue.
The Hash Rate Anomaly Mitigation AI Agent was engineered to compress this entire detection-diagnosis-response cycle into an automated workflow that operates continuously across all monitored facilities. By implementing intelligent threshold monitoring with automated first-response protocols, the system transforms hash rate anomaly management from a reactive, staff-dependent process into a proactive, automated operational capability.
Benefits
This agent delivers measurable operational improvements by eliminating the manual bottlenecks in anomaly detection and initial response.
- Dramatically reduced response latency: Automated detection and mitigation execute within seconds of anomaly identification, eliminating the multi-hour gap between event occurrence and human-initiated response that characterizes manual monitoring workflows
- Continuous monitoring coverage: The workflow operates across all facilities without interruption, removing the dependency on shift schedules, staff availability, and the attentional limitations inherent in human dashboard monitoring
- Consistent first-response execution: Automated mitigation protocols execute identically every time, eliminating the variability that occurs when different operators apply different diagnostic and response procedures to similar events
- Operations team reallocation: With automated first-response handling the initial mitigation steps, operations personnel are freed from constant monitoring duties and can focus on root cause analysis, infrastructure improvements, and complex issues that genuinely require human judgment
- Reduced cascading failures: Rapid automated response to initial anomalies prevents the escalation patterns where an unaddressed performance degradation in one system propagates to adjacent infrastructure and compounds the operational impact
- Comprehensive event logging: Every detection, diagnosis, and mitigation action is automatically logged with precise timestamps and parameter values, creating a detailed operational record for post-incident analysis and process optimization
Problem Addressed
Server facility operations at scale present a fundamental monitoring challenge: the volume of telemetry data generated by large server deployments exceeds what human operators can effectively process in real-time. Hash rate metrics fluctuate continuously across individual machines, racks, and facility zones. Distinguishing between normal operational variance and genuine anomalies that require intervention demands constant attention to statistical baselines, threshold boundaries, and cross-correlated facility metrics.
When a genuine low hash rate event occurs, the clock starts immediately. Every minute of degraded performance represents lost computational throughput. The manual response workflow introduces multiple delay points: the time between event occurrence and operator awareness (detection latency), the time required for the operator to assess the situation and determine the appropriate response (diagnostic latency), and the time to execute the mitigation steps (response latency). In a manual workflow, these cumulative delays routinely stretch into hours, particularly during off-hours when staffing is reduced.
Beyond the direct performance impact, manual monitoring creates an operational culture of constant vigilance that is both unsustainable and error-prone. Operators monitoring dashboards for extended periods experience attention degradation. Shift handoffs create information gaps. And the reliance on individual operator expertise means that response quality varies depending on who happens to be on duty when an event occurs.
What the Agent Does
The agent implements a closed-loop monitoring and response system that operates continuously across all instrumented server facilities:
- Real-time telemetry ingestion: Server metrics including hash rates, temperatures, power consumption, and network throughput are continuously streamed into the monitoring framework, establishing a live operational picture across all facilities
- Baseline computation and threshold management: The system maintains dynamic performance baselines for each facility, rack, and individual server, adjusting thresholds based on historical performance patterns, environmental conditions, and known operational cycles
- Anomaly detection engine: Statistical anomaly detection algorithms continuously evaluate incoming metrics against established baselines, identifying deviations that exceed configured significance thresholds while filtering out normal operational variance to minimize false positive alerts
- Automated diagnostic classification: When an anomaly is confirmed, the workflow classifies the probable cause category based on the pattern of affected metrics, distinguishing between thermal events, power issues, network degradation, and hardware failures to select the appropriate mitigation protocol
- Immediate mitigation execution: Predefined response protocols execute automatically upon anomaly confirmation, applying the appropriate first-response actions such as workload redistribution, cooling system adjustments, or targeted restart sequences without waiting for human authorization
- Escalation and notification: Events that exceed automated mitigation capabilities or that persist after initial response are escalated to operations personnel with full diagnostic context, enabling informed human intervention rather than cold-start troubleshooting
Standout Features
- Sub-second detection-to-action pipeline: The entire cycle from anomaly detection through diagnostic classification to mitigation execution operates within the same workflow engine, eliminating the inter-system handoff delays that plague architectures where monitoring, alerting, and response are handled by separate tools
- Adaptive threshold calibration: Performance baselines are not static configuration values. The system continuously recalibrates expected performance ranges based on observed patterns, seasonal trends, and facility-specific characteristics, reducing both false positives and missed detections over time
- Multi-signal correlation: Anomaly detection evaluates hash rate metrics in conjunction with correlated signals including temperature, power draw, and network latency, enabling more accurate root cause classification than single-metric threshold monitoring can achieve
- Graduated response protocols: Mitigation actions are organized in escalating severity tiers. Initial response applies the least disruptive intervention first, with more aggressive measures triggered only if the initial response does not resolve the anomaly within defined time windows
- Facility-wide impact assessment: When an anomaly is detected in one zone, the system automatically evaluates adjacent zones and shared infrastructure for early indicators of related degradation, enabling preemptive action before cascading failures develop
Who This Agent Is For
This agent is designed for organizations operating server infrastructure at scale where computational throughput is a direct revenue driver and where the cost of performance degradation justifies investment in automated monitoring and response capabilities.
- Data center operations teams responsible for maintaining uptime and throughput targets across large server deployments who need to reduce their dependency on manual monitoring
- Facility managers overseeing distributed server installations who need consistent, automated first-response capabilities across all locations regardless of local staffing levels
- Infrastructure engineering leads seeking to formalize and automate their incident response procedures to eliminate the variability and delay inherent in manual response workflows
- Operations directors managing 24/7 facilities who need to optimize staff allocation by automating routine anomaly detection and initial mitigation
- Technical leadership evaluating operational efficiency improvements for compute-intensive infrastructure where response time directly impacts business outcomes
Ideal for: Data center operators, infrastructure engineering teams, facility managers, and operations directors running large-scale compute environments where every minute of degraded performance has a measurable cost and where automated monitoring and response can deliver immediate operational ROI.

Patient Survey Intelligence AI Agent
AI-powered survey analysis workflow that ingests patient satisfaction data, applies data science to isolate the specific topics driving score declines, and generates targeted improvement recommendations routed through a structured manager and director approval chain before implementation.
Patient satisfaction scores are declining, and the team responsible for improving them cannot pinpoint exactly why
A regional healthcare system faced a problem that is painfully common across hospitals and health networks: patient satisfaction survey scores were trending downward, but the raw survey data offered no clear explanation. The surveys themselves generate massive volumes of structured and unstructured feedback, and the clinical and administrative teams tasked with improving those scores had no automated way to isolate the specific topics, departments, or interaction types that were actually dragging performance down. The result was a familiar pattern: leadership knew something was wrong, improvement committees met to discuss it, but the recommendations that emerged were based on anecdotal impressions rather than systematic, data-driven root cause analysis.
Making this worse, whatever recommendations did surface had no structured path from identification to action. A quality improvement lead might identify a potential issue, but getting that recommendation reviewed by the right department manager, approved by a director, and tracked through implementation required a manual chain of emails and meetings that often stalled or lost context along the way.
The Patient Survey Intelligence AI Agent was built to close both gaps simultaneously: automated root cause identification powered by data science and a structured approval workflow that ensures every improvement recommendation moves from insight to action with accountability at every step.
Benefits
This agent transforms patient satisfaction improvement from a reactive, committee-driven process into a systematic, evidence-based workflow with built-in accountability.
- Root cause clarity: Instead of debating what might be causing score declines, clinical and administrative leaders receive data-driven identification of the exact topics and interaction points that are suppressing satisfaction scores, supported by statistical evidence rather than anecdotal impressions
- Faster time to intervention: Automated analysis replaces weeks of manual data review, compressing the gap between when a score decline appears and when the organization begins responding to it
- Structured accountability: Every improvement recommendation flows through a defined manager and director approval chain, ensuring that identified issues do not languish in committee discussions but move through a concrete decision process with clear ownership
- Consistent methodology: The same analytical framework applies across every survey cycle, eliminating the inconsistency that arises when different analysts or departments use different approaches to interpret the same data
- Reduced improvement fatigue: Teams receive focused, prioritized recommendations rather than long lists of potential issues, concentrating improvement energy on the changes most likely to move satisfaction scores
- Longitudinal impact tracking: As the agent runs across successive survey periods, the organization accumulates a clear record of which interventions correlated with score improvements, building an institutional knowledge base for continuous quality improvement
Problem Addressed
Patient satisfaction surveys generate data. That part has never been the problem. The problem is what happens after the data is collected. In most healthcare organizations, survey results arrive as aggregate scores broken down by department, question category, and time period. When scores decline, the question is always the same: what specifically is causing this? And the answer is almost never straightforward.
Survey data contains dozens of dimensions. A declining overall score could be driven by discharge communication in one unit, medication explanation quality in another, or responsiveness to call buttons across the entire facility. Isolating the actual drivers requires statistical analysis that most quality improvement teams do not have the time, tools, or analytical bandwidth to perform rigorously on every survey cycle. Instead, they rely on high-level category comparisons and anecdotal feedback from patient advocates to form hypotheses about where to focus.
Even when a team correctly identifies a root cause, the path from insight to action is often disconnected. The quality improvement team identifies an issue, but the department manager who needs to approve and implement a change may not receive the recommendation with sufficient context. The director who needs to authorize resources may see it weeks later in a different format. The result is that valid insights lose momentum in the organizational workflow, and improvement cycles stretch from weeks into months.
What the Agent Does
The agent operates as an end-to-end survey intelligence pipeline that connects raw patient feedback data to structured improvement actions:
- Survey data ingestion: The workflow automatically imports patient satisfaction survey data including both structured Likert-scale responses and open-ended comment fields, normalizing the data into an analytical framework
- Data science topic analysis: Advanced statistical methods including topic modeling and regression analysis identify which specific survey dimensions are statistically correlated with overall score declines, separating signal from noise across potentially hundreds of question-response combinations
- Root cause prioritization: The agent ranks identified topics by their estimated impact on overall satisfaction scores, ensuring that the organization focuses on the drivers with the largest potential improvement effect rather than the most obvious surface-level complaints
- AI recommendation generation: For each identified root cause, the AI service layer generates specific, contextual improvement recommendations that reference the underlying data patterns and suggest concrete interventions appropriate to the clinical or operational domain
- Approval chain routing: Each recommendation is automatically routed to the appropriate department manager for initial review, then escalated to the relevant director for final approval, with full context and supporting data attached at each step
- Implementation tracking: Approved recommendations enter a tracked workflow that maintains visibility into implementation status, creating a closed-loop system from survey data to organizational action
Standout Features
- Statistical root cause isolation: Unlike dashboard-based analysis that shows what scores changed, this agent identifies why they changed by applying regression and topic modeling techniques that isolate the specific survey dimensions with the strongest statistical relationship to overall score movement
- Dual-layer approval workflow: The manager-then-director approval chain is not just a notification system. Each approver receives the full analytical context including the statistical evidence, the AI-generated recommendation, and the estimated impact, enabling informed decisions rather than rubber-stamp approvals
- Comment and score integration: The agent analyzes both structured scores and unstructured patient comments together, using natural language processing on comment data to enrich and validate the patterns identified in numerical scores
- Adaptive recommendation specificity: Recommendations are calibrated to the type of issue identified. A communication-related finding generates training-focused recommendations. A process-related finding generates workflow modification recommendations. The agent matches the intervention type to the problem category.
- Cross-cycle trend detection: The agent maintains awareness of previous survey cycles, flagging persistent issues that have not responded to prior interventions and escalating them with additional urgency in the approval workflow
Who This Agent Is For
This agent is built for healthcare organizations where patient satisfaction scores carry real operational, financial, and reputational weight, and where the current process for translating survey data into improvement actions is too slow, too manual, or too disconnected from the people who need to act on it.
- Quality improvement directors who need systematic, data-driven identification of satisfaction drivers rather than anecdotal hypothesis generation
- Hospital administrators responsible for maintaining or improving publicly reported satisfaction metrics with limited analytical bandwidth
- Department managers who receive improvement mandates but need specific, evidence-based guidance on where to focus their team's effort
- Chief experience officers tracking satisfaction trends across multi-facility health systems who need consistent analytical methodology across all locations
- Nursing directors and clinical leads who want their improvement initiatives grounded in statistical evidence rather than committee consensus
Ideal for: Hospital quality improvement leaders, department directors, patient experience officers, and clinical administrators who need to move faster from survey data to targeted improvement actions with organizational accountability built into every step.

Paid Media Performance AI Agent
Acts as a copilot for the paid media team with complete access to all campaign data across platforms. Identifies trends, analyzes performance, generates optimization recommendations, and drives measurable pipeline growth with reduced acquisition costs.
The paid media manager had six browser tabs open: Google Ads, LinkedIn Campaign Manager, Meta Ads Manager, the CRM pipeline, a conversion spreadsheet, and a stale dashboard. She was trying to answer one question: which campaigns should get more budget this week? The data existed across all six systems. She had been synthesizing it manually every Monday for two years.
A SaaS marketing platform faced this bottleneck. Their team managed campaigns across multiple ad platforms, each with its own reporting. Cross-platform evaluation required manual aggregation, and optimization decisions were based on whatever could be pieced together from disconnected dashboards. Cost per MQL and SAL exceeded targets, and by the time underperformers were identified, days of spend had been wasted. They needed an AI copilot that could see all data and generate recommendations faster than any analyst.
Benefits
This agent gives paid media teams the analytical firepower of a data science team, compressing optimization cycles from days to minutes.
- Unified cross-platform visibility: All campaign data aggregated into a single view, eliminating tab-switching and manual reconciliation that consumes hours weekly
- Faster optimization cycles: AI recommendations surface daily rather than waiting for weekly reviews, enabling reallocation before underperformers waste additional spend
- Reduced cost per acquisition: Systematic identification of inefficient spend drives measurable reductions, with one deployment achieving approximately 20% lower cost per MQL and 15% lower cost per SAL
- Pipeline-aware optimization: Unlike platform-native tools optimizing for clicks, this agent connects ad performance to pipeline metrics, ensuring spend is optimized for revenue
- Institutional knowledge preservation: Optimization patterns are captured systematically, ensuring best practices persist through team transitions
Problem Addressed
Paid media teams operate in a fragmented environment. Every platform provides its own dashboard and recommendations. Each optimizes for its own ecosystem, and none see how campaigns contribute to actual revenue.
The media manager sits in the middle, manually pulling data and normalizing metrics across attribution models. A team managing dozens of campaigns across four platforms cannot analyze every data point daily. They resort to heuristics and gut-feel decisions. The cost compounds silently. An underperforming campaign running three extra days wastes thousands. A high-performing segment sits budget-capped because nobody has reviewed its metrics.
What the Agent Does
The agent functions as an always-on copilot, ingesting data from all platforms and generating actionable recommendations:
- Cross-platform aggregation: Campaign data from Google Ads, LinkedIn, Meta, and others normalized into a unified model for direct cross-channel comparison
- Performance trend analysis: AI monitors cost efficiency, engagement, conversion rates, and pipeline contribution, identifying trends that would take hours to detect manually
- Optimization recommendations: Specific suggestions for budget reallocation, audience adjustments, bid changes, and creative rotation, ranked by expected pipeline impact
- Pipeline attribution mapping: Ad data connected to CRM, tracing impression to MQL to revenue, grounding recommendations in business outcomes
- Anomaly detection: Sudden CPA changes or conversion drops trigger immediate alerts with diagnostic context for same-day response
Standout Features
- Natural language copilot: Managers ask "which LinkedIn campaigns should I pause?" and receive specific, data-backed answers rather than generic dashboards
- Revenue-optimized recommendations: Optimizes for downstream MQL and SAL volume correlated with revenue, not platform-level vanity metrics
- Historical pattern recognition: Analyzes seasonal trends, audience fatigue, and creative decay to enable proactive optimization before performance degrades
- Budget scenario modeling: Teams model reallocation impacts before committing, comparing projected outcomes with AI confidence intervals
- Multi-touch attribution: Cross-platform paths reveal campaign synergies and redundancies invisible to single-platform analysis
Who This Agent Is For
This agent is designed for paid media teams managing campaigns across multiple platforms who need to optimize for pipeline outcomes.
- Paid media managers spending hours weekly on manual cross-platform aggregation who want unified visibility and specific recommendations
- Demand generation directors needing data-backed evidence for budget allocation across channels
- Marketing operations teams connecting ad platform data to CRM pipeline at scale
Ideal for: Paid media managers, demand generation leaders, and any marketing organization where cross-platform optimization is constrained by manual processes.

Sentiment & Credit Optimization AI Agent
Utilizes AI to perform sentiment analysis on incoming customer support tickets while also automating credit usage optimization to identify and retire low-value datasets consuming resources without generating business value.
The support queue was growing, the platform bill was climbing, and nobody could explain why either number was moving in the wrong direction. Hundreds of tickets arrived each week with no systematic way to extract patterns. Meanwhile, datasets accumulated across the environment like unused furniture, each consuming credits whether it delivered value or not.
A capital management firm encountered this dual challenge at scale. Their support operation generated high ticket volume, but trends in customer frustration and recurring complaints were invisible because nobody had bandwidth to synthesize patterns manually. Simultaneously, the data environment had grown organically over years, accumulating datasets that consumed credits without clear justification. Without automated analysis, the team was flying blind on sentiment and hemorrhaging credits on data nobody accessed.
Benefits
This agent addresses two costly blind spots in a single deployment: unanalyzed customer sentiment and unmanaged resource consumption.
- Automated sentiment intelligence: Every support ticket is analyzed for emotional tone, urgency, and topic classification, surfacing patterns that would require a dedicated analyst team to identify manually
- Proactive cost management: Credit consumption is monitored against actual business value, identifying datasets consuming resources disproportionate to usage and flagging them for retirement
- Trend detection at scale: Sentiment trends reveal emerging product issues and satisfaction shifts weeks before they surface through traditional feedback channels
- Resource reallocation precision: Quantifying which datasets deliver value enables retirement decisions based on evidence rather than guesswork or institutional inertia
- Unified operational visibility: Customer experience and resource efficiency metrics in a single interface give leadership a holistic view without cross-referencing disconnected reports
Problem Addressed
Organizations at scale face paired blind spots that grow more expensive over time. Support tickets contain rich signal about customer experiences and product shortfalls, but extracting it requires reading every ticket and tracking sentiment patterns. At volume, this is impractical. Tickets get resolved individually, but aggregate intelligence is lost.
The second blind spot is resource consumption. Data platforms accumulate datasets over years as teams create them for projects and one-time analyses. Many continue consuming credits long after their purpose is fulfilled. Without systematic auditing, cost grows invisibly. Both problems share a root cause: absent automated analysis at scale. Manual approaches require dedicated headcount and still produce incomplete results.
What the Agent Does
The agent operates as a dual-function intelligence system, analyzing customer sentiment and platform resource efficiency in parallel:
- Ticket sentiment classification: NLP models classify emotional tone on a granular spectrum, detecting frustration intensity, urgency signals, and satisfaction indicators beyond simple positive/negative binaries
- Topic extraction and clustering: AI identifies specific product features and service areas referenced in tickets, clustering related issues to reveal which areas generate the most negative sentiment
- Trend monitoring and alerting: Sentiment scores tracked over time with anomaly detection flag sudden shifts, enabling investigation before complaints become widespread
- Dataset value scoring: Every dataset is scored against query frequency, downstream dependencies, last access date, and cost, producing a clear value-to-cost ratio
- Retirement recommendations: Low-value datasets are surfaced with impact analysis on downstream reports and processes before recommending removal
Standout Features
- Dual-mode architecture: A single deployment addresses two distinct challenges through shared AI infrastructure, reducing overhead versus deploying separate sentiment and optimization tools
- Granular sentiment modeling: The NLP pipeline distinguishes between mild inconvenience and acute frustration, between routine inquiries and escalation-worthy situations, enabling proportional response
- Cost attribution at the dataset level: Credit consumption mapped to individual datasets replaces opaque aggregate billing, making specific cost drivers visible
- Automated impact analysis: Before recommending retirement, the agent traces all downstream dependencies to ensure decisions do not break active workflows
- Combined dashboard: Sentiment trends and efficiency metrics in one interface enable correlation of customer experience quality with operational spending patterns
Who This Agent Is For
This agent serves organizations needing systematic intelligence from two data-rich domains typically analyzed manually or not at all.
- Support operations managers extracting patterns from high-volume ticket queues without dedicated analysts
- Data governance teams managing platform consumption who lack automated tools to identify which datasets justify their cost
- Finance leaders controlling rising platform costs who need granular spend visibility
Ideal for: Support operations directors, data governance managers, platform administrators, and finance teams where ticket volume and dataset proliferation have outgrown manual management.

Web Lead Triage AI Agent
Automatically identifies and filters spam web inquiries from incoming datasets, ensuring qualified leads are prioritized and routed to the sales team without delay. Eliminates manual triage and accelerates lead response time.
Every morning, the sales ops lead opened the web lead queue and started the same tedious routine: scrolling through dozens of form submissions, flagging the obvious spam, and forwarding whatever looked real to the reps. By the time a qualified lead actually reached a salesperson, hours had passed. The leads that mattered were buried under noise.
A financial services holding company faced exactly this problem. Their web intake forms generated a steady stream of inquiries, but the signal-to-noise ratio was brutal. Spam bots and junk data overwhelmed the pipeline. Sales reps either wasted time manually sorting through garbage or ignored the web channel entirely. The company needed a way to separate real prospects from noise at machine speed, without adding headcount.
Benefits
This agent transforms the web lead pipeline from a manual sorting exercise into an automated qualification engine that delivers only real prospects to the sales floor.
- Near-zero spam in the sales queue: AI classification catches junk submissions before they ever reach a human, eliminating the daily triage burden that delayed follow-up on legitimate inquiries
- Faster speed-to-lead: Qualified prospects are identified and routed within seconds of submission rather than waiting hours for manual review, improving the window for outreach while buyer intent is fresh
- Sales team focus on selling: Reps no longer waste productive hours sorting through form submissions, reclaiming time that translates directly to more pipeline and closed revenue
- Consistent qualification criteria: AI applies the same scoring logic to every submission without fatigue or bias, ensuring borderline leads are evaluated with equal rigor regardless of time or day
- Restored trust in the web channel: When sales teams know web leads have been pre-qualified, they engage with the channel instead of ignoring it, unlocking pipeline previously lost to skepticism
Problem Addressed
Web lead forms are one of the highest-volume inbound channels for B2B organizations, but also the noisiest. For every legitimate inquiry, there are multiple spam submissions, bot-generated entries, and irrelevant requests. The challenge is not generating leads. The challenge is finding the real ones.
Manual triage fails predictably. A coordinator opens the queue each morning and starts sorting. Some submissions are obviously spam, others borderline, and a few clearly qualified but sitting unreviewed for hours. Experienced reps learn to distrust the web channel and stop checking it. The channel withers not from lack of volume, but because qualified leads are invisible under noise. The cost compounds: a lead uncontacted for 24 hours is dramatically less likely to convert. Every hour of triage delay is a measurable hit to conversion rates.
What the Agent Does
The agent sits between the web form and the sales team, classifying every incoming submission and routing only qualified leads forward:
- Real-time intake processing: Every submission is ingested immediately with no batching delays, ensuring classification begins the moment a prospect hits submit
- Multi-signal spam detection: AI analyzes content, form field patterns, email domain reputation, and behavioral signals to identify spam with high precision, catching sophisticated bots that rule-based filters miss
- Lead qualification scoring: Submissions passing the spam filter are scored against criteria including company info, role indicators, and engagement signals to prioritize highest-value prospects
- Automated routing: Qualified leads are pushed directly to the appropriate rep or team queue with original form data and AI confidence score attached
- Continuous learning loop: Sales feedback flows back into the model, improving accuracy as the agent learns which patterns predict genuine buyer intent in your market
Standout Features
- Sub-second classification: Leads classified and routed within seconds rather than sitting in a queue for hours, compressing speed-to-lead from hours to near-instantaneous
- Adaptive spam models: The classification engine evolves as spam tactics change, detecting new bot patterns without requiring manual rule updates from the operations team
- Confidence-based escalation: Borderline submissions are flagged for human review rather than auto-rejected, ensuring ambiguous leads get attention without flooding the queue with spam
- Full audit trail: Every classification decision is logged with reasoning and confidence score, giving complete visibility into what was filtered and how the model performs
- CRM-native integration: Qualified leads flow directly into the existing CRM workflow with enriched metadata, requiring no change to how reps work their pipeline
Who This Agent Is For
This agent is built for sales and marketing teams that generate significant web lead volume but struggle with noise in their inbound pipeline.
- Sales operations leaders who spend hours weekly triaging web submissions and want to eliminate that manual burden without sacrificing lead quality
- Demand generation managers who need to prove the web channel delivers qualified pipeline, not just raw form fills inflated by spam
- Revenue operations teams tracking speed-to-lead as a KPI who need to compress time between submission and first contact
Ideal for: Sales operations managers, demand generation directors, and any B2B organization where web form spam undermines the inbound lead channel.

Metadata Extraction AI Agent
AI agents that automatically extract metadata from data flows and populate structured documentation, with self-service refresh capabilities ensuring documentation stays current as pipelines evolve without manual intervention.
Benefits
The most expensive documentation is documentation that exists but is wrong. When metadata drifts out of sync with the pipelines it describes, every downstream consumer makes decisions on stale information. This agent ensures metadata is always current because it is always generated from the source.
- Zero manual documentation effort: Engineering teams that spent hours documenting pipeline metadata eliminate that work entirely as the agent extracts and populates documentation automatically
- Always-current metadata: Documentation updates automatically as pipelines evolve, eliminating the decay pattern where records become outdated within weeks of a manual pass
- Self-service refresh: Teams trigger documentation refresh on demand without filing tickets, ensuring current metadata is available whenever consumers need it
- Accelerated onboarding: New team members understand pipeline architecture through auto-generated documentation rather than tribal knowledge from senior engineers
- Governance-ready output: Extracted metadata meets structural requirements for governance programs, compliance audits, and catalog integrations without additional formatting
- Reduced knowledge gap risk: When key engineers leave, pipeline knowledge is preserved in auto-generated documentation rather than leaving with them
Problem Addressed
A leading real estate technology company confronted a universal data engineering problem: the gap between how fast pipelines change and how fast documentation keeps up. Their teams maintained hundreds of data flows, each with metadata downstream consumers needed: field definitions, transformation logic, source mappings, and dependency chains. Engineers documented manually and updated when changes occurred.
Pipeline evolution is continuous. Fields are added, transformations modified, and sources swapped faster than documentation cycles. Within weeks, significant portions of the catalog were stale. Analysts made incorrect assumptions from outdated definitions. Governance teams found documentation that no longer matched reality. The records existed but could not be trusted, creating false confidence in inaccurate information.
What the Agent Does
The agent connects directly to data flow definitions and automatically extracts, structures, and maintains metadata documentation:
- Pipeline metadata extraction: AI agents parse data flow configurations to extract field-level metadata including column names, data types, transformation logic, and source connections from actual definitions
- Structured document population: Extracted metadata populates standardized templates following governance format with field descriptions, lineage maps, and transformation summaries
- Change detection and refresh: Monitors pipeline definitions for modifications and triggers documentation refresh automatically, ensuring records reflect current state
- Self-service refresh interface: Team members initiate on-demand refresh for any pipeline, receiving updated metadata within minutes
- Cross-pipeline dependency mapping: Traces data flow connections across pipelines to generate dependency maps showing how upstream changes propagate
Standout Features
- Source-of-truth extraction: Metadata derived from pipeline definitions rather than human records, ensuring accuracy is bounded by extraction fidelity rather than manual diligence
- Intelligent change detection: Distinguishes significant modifications from minor operational changes, avoiding churn while capturing meaningful updates
- Template-driven output: Configurable templates adapt to organizational standards for data catalogs, governance submissions, and compliance documentation
- Lineage visualization: Dependency maps generated as visual diagrams alongside structured data, providing both detail and architectural overview
- Incremental extraction: After initial full pass, refreshes process only modified pipelines, keeping documentation current with minimal overhead
Who This Agent Is For
This agent delivers immediate value to any organization where pipeline documentation is a known liability and engineering time on manual docs displaces higher-value work.
- Data engineering teams maintaining dozens or hundreds of pipelines who need automated documentation that stays current
- Data governance teams responsible for accurate metadata catalogs for compliance and audit
- Analytics teams depending on reliable field definitions and lineage to build accurate reports
- Platform teams managing shared infrastructure where clear documentation enables cross-team self-service
- Organizations undergoing data modernization that need comprehensive documentation of existing pipelines
Ideal for: Data engineering organizations, analytics platforms, governance programs, real estate technology companies, and any enterprise where pipeline volume has exceeded manual metadata maintenance capacity.

Asset Governance & Tagging AI Agent
AI-driven governance agent that automatically tags, classifies, and identifies digital assets for cleanup or archival, enforcing consistent taxonomy across the organization and maintaining ongoing data hygiene without manual intervention.
Benefits
Digital asset ecosystems accumulate entropy over time. Naming conventions drift, metadata goes unpopulated, and deprecated assets remain active. This agent applies continuous AI-driven governance to reverse that entropy and maintain data hygiene at scale.
- Automated taxonomy enforcement: Every asset receives consistent metadata tags via AI classification, eliminating inconsistency from manual contributor tagging
- Continuous cleanup identification: The agent surfaces outdated, duplicated, or miscategorized assets automatically, replacing quarterly manual audits
- Reduced governance overhead: Teams redirect hours previously spent reviewing and organizing assets toward content creation while the agent handles classification
- Improved asset discoverability: Consistent AI-applied metadata ensures search returns complete, accurate results rather than missing items tagged differently by different people
- Proactive archival recommendations: Continuously identifies archival candidates based on age, usage patterns, relevance, and metadata completeness
Problem Addressed
A major tourism and destination marketing organization faced a governance challenge that scales with every digital footprint: their growing asset library lacked consistent metadata and tagging. Creative teams, regional partners, and agencies all contributed assets with their own naming conventions. Finding the right asset required institutional knowledge rather than systematic search.
Technical debt compounded over time. Assets that should have been archived stayed active. Duplicates proliferated. Critical metadata fields went unpopulated. Manual cleanup identification was time-consuming and unreliable. The organization needed a governance layer that could classify, tag, and maintain the entire asset ecosystem continuously rather than through periodic manual intervention.
What the Agent Does
The agent implements AI-driven governance workflows across the digital asset ecosystem to enforce classification standards and maintain hygiene:
- Automated asset classification: AI models analyze each asset based on content type, visual characteristics, and contextual signals to assign standardized taxonomy categories
- Metadata tag application: The agent populates required fields including content category, usage rights, campaign association, and regional relevance based on classification
- Cleanup candidate identification: A rules engine evaluates every asset against quality criteria including completeness, age, usage frequency, and duplicate detection
- Archival routing: Assets meeting archival criteria are flagged with recommended actions, providing governance teams with prioritized cleanup queues
- Reclassification detection: As taxonomy evolves, the agent identifies assets under deprecated categories and recommends updated classifications
Standout Features
- Content-aware classification: AI examines actual asset content rather than filenames, enabling accurate categorization even when files arrive with non-descriptive names
- Adaptive taxonomy mapping: Supports evolving schemas, detecting when changes create orphaned categories and recommending migration paths for affected assets
- Multi-signal quality scoring: Asset health evaluated across metadata completeness, format currency, usage recency, and duplicate proximity simultaneously
- Continuous versus batch operation: Evaluates every asset as it enters or changes rather than waiting for quarterly audit cycles
- Configurable governance rules: Classification criteria, metadata requirements, and archival thresholds adjust through a rules interface without engineering involvement
Who This Agent Is For
This agent is engineered for organizations whose digital asset libraries have grown beyond the point where manual governance is sustainable.
- Marketing operations teams managing creative asset libraries across campaigns, channels, and partner networks
- Digital asset managers responsible for repositories where contributor volume makes manual tagging impractical
- IT governance teams tasked with data hygiene across shared storage where accumulation outpaces cleanup
- Brand compliance officers who need assurance that assets are correctly categorized and retrievable
- Tourism, hospitality, and destination marketing organizations managing visual content libraries spanning thousands of assets
Ideal for: Marketing organizations, destination marketing companies, media libraries, brand management teams, and any enterprise where digital asset volume has created a governance gap.

Contract Lifecycle Intelligence AI Agent
AI agent that automates ingestion, storage, and extraction of critical contract data into structured datasets, tracks expiration dates with automated stakeholder notifications, and provides a conversational AI interface for instant, context-aware answers about contract terms, obligations, and timelines.
Benefits
When an organization manages hundreds of complex agreements spanning dozens of pages each, the risk of a missed renewal or overlooked obligation is not hypothetical. This agent eliminates that risk by converting every contract into structured, queryable, actively monitored data.
- Elimination of manual review labor: Staff who spent days extracting data from 80-page agreements can redirect expertise toward negotiation and strategy while the agent handles ingestion and extraction automatically
- Proactive expiration management: Every contract is tracked against its expiration timeline with automated stakeholder notifications, ensuring renewal conversations begin months before deadlines
- Reduced oversight risk: Obligation clauses, compliance requirements, and benchmarks buried deep within agreements are extracted and surfaced systematically
- Instant contract answers: A conversational AI interface enables team members to ask natural-language questions about terms, timelines, and obligations without opening a single document
- Consistent data accuracy: Automated extraction applies the same methodology to every agreement, removing variability from manual interpretation
Problem Addressed
A national behavioral health organization managing hundreds of complex provider agreements faced a challenge familiar to any legal or operations team: contracts contained critical intelligence, but extracting it required a fully manual process. Each agreement spanned 80-plus pages covering reimbursement terms, compliance obligations, and renewal conditions. Staff transcribed key data into spreadsheets, consuming significant labor with inherent risk of error.
Missed expiration dates meant agreements auto-renewed on unfavorable terms. Overlooked clauses created compliance exposure. When a stakeholder needed to verify whether a term existed across the portfolio, the answer required opening dozens of documents manually. The organization had the contracts but lacked a system to transform them into structured, searchable intelligence.
What the Agent Does
The agent implements a complete contract intelligence pipeline from ingestion through conversational query access:
- Automated document ingestion: Contracts uploaded to a centralized repository are automatically detected, queued for processing, and version-tracked as amendments arrive
- AI-powered clause extraction: NLP models parse each agreement to extract key provisions including dates, renewal terms, payment schedules, and obligation clauses
- Structured data population: Extracted data flows into standardized datasets enabling cross-contract querying, portfolio reporting, and downstream integration
- Expiration tracking and alerting: Automated timeline monitoring generates stakeholder notifications at configurable intervals before expiration
- Conversational contract Q&A: An AI chat interface lets users ask questions about any contract and receive precise answers with document citations
Standout Features
- Deep document understanding: Handles nested clauses, cross-references, amendment overlays, and multi-party formats without document-specific configuration
- Context-aware Q&A: Asking about payment terms returns the full compensation structure including base rates, incentives, and escalation schedules rather than keyword matches
- Portfolio-level analytics: Enables portfolio-wide analysis such as identifying all agreements expiring within a quarter or flagging non-standard clause language
- Automated stakeholder routing: Alerts route to specific stakeholders responsible for each contract, ensuring the right people receive actionable notifications
Who This Agent Is For
This agent delivers transformative value to organizations managing complex agreement portfolios where manual review creates risk and leaves intelligence locked inside static documents.
- Legal departments managing vendor or partner agreements who need automated extraction to replace manual review
- Compliance teams monitoring obligations across hundreds of active agreements with varying timelines
- Operations leaders who need instant access to contract terms without waiting for legal review cycles
- Procurement teams managing renewal pipelines who need proactive visibility into upcoming expirations
- Healthcare organizations with complex provider agreements containing reimbursement structures and compliance mandates
Ideal for: Healthcare systems, behavioral health organizations, legal departments, compliance teams, and any organization where contractual volume has outgrown manual review capacity.

Data Export AI Agent
AI-generated self-service data extraction app that lets users choose any dataset, select specific fields, apply filters, and export results to Excel or CSV format without technical skills or developer assistance.
The analyst needed 12 columns from a 90-column dataset, filtered to the last quarter, in a spreadsheet. It should have taken 30 seconds. Instead, it took a support ticket, a three-day wait, and a full data dump she had to clean up herself.
The Data Export AI Agent was built to eliminate the last-mile friction in data access: getting data out of the platform and into the format users actually need. Every data platform stores data well. Most make it visible through dashboards and reports. But when a user needs raw data in a spreadsheet, filtered to specific criteria and limited to specific columns, the process breaks down. Either the platform offers a bulk export that dumps everything, requiring the user to manually clean and filter, or it requires technical skills to build a custom extraction query. A business intelligence team recognized this gap and used AI-powered app generation to create a self-service extraction tool in minutes. Users select a dataset, choose their fields, apply filters, and export to Excel or CSV. The entire experience was auto-generated by an AI app builder, demonstrating that functional business tools can be created without traditional development cycles.
Benefits
This agent provides the missing self-service layer between data visibility in dashboards and raw data access in spreadsheets, giving users exactly the data they need in exactly the format they want.
- Zero-wait data access: Users export filtered, field-specific data immediately through a self-service interface rather than submitting requests to the analytics team and waiting days for a custom extraction
- Precise data selection: Field-level selection and filtering ensure that users receive exactly the columns and rows they need rather than a full data dump that requires additional cleanup in the spreadsheet
- No technical skills required: The visual interface handles dataset browsing, field selection, and filter application without requiring SQL knowledge, API familiarity, or any technical expertise
- Reduced analytics team burden: Routine data extraction requests that previously consumed analyst time are handled entirely through self-service, freeing the analytics team for higher-value work
- AI-generated in minutes: The app itself was created by an AI app builder, demonstrating that organizations can produce functional internal tools without developer resources or multi-sprint development cycles
Problem Addressed
Data platforms have become excellent at storing, transforming, and visualizing data. But when users need to get data out of the platform, the experience degrades sharply. An analyst needs to combine platform data with information in a spreadsheet. A manager needs to send a filtered data extract to an external partner. A finance team needs specific columns from a large dataset for their own modeling. In each case, the user needs raw data in a specific format, and the path to getting it is surprisingly difficult.
Most platforms offer export functionality, but it is either all-or-nothing or requires technical sophistication. A full export gives the user every column and every row, generating a massive file that requires significant cleanup before it is usable. A filtered export requires writing query logic or using an API, which most business users cannot do. The result is a steady stream of data extraction requests flowing to the analytics team, each one straightforward but collectively consuming hours of skilled-worker time every week. The analyst who receives these requests knows that each one takes five minutes to fulfill. She also knows that she has 30 of them in her queue. The requesting users know that their five-minute task will take three days because of the queue. Everyone is frustrated. The data is right there. Getting it out should not require a ticket.
What the Agent Does
The agent delivers a complete self-service data extraction application that was auto-generated by an AI app builder:
- Dataset browsing: Presents available datasets in a searchable, browsable interface where users can identify the data source they need without knowing system names or navigating folder structures
- Field selection: Displays all available columns for the selected dataset and lets users choose exactly which fields to include in their export, preventing the unnecessary data bloat of full-table exports
- Filter application: Provides intuitive filter controls for each selected field, supporting date ranges, value lists, text matching, and numeric thresholds that narrow the export to precisely the rows the user needs
- Format selection: Offers export to Excel (.xlsx) or CSV format, accommodating users who need spreadsheet functionality and those who need flat files for import into other systems
- Export execution: Processes the extraction request and delivers the filtered, field-specific file for immediate download, completing the entire workflow within the self-service interface
Standout Features
- AI-generated application: The entire app was created by an AI app builder rather than being manually coded, demonstrating that functional data tools can be produced in minutes rather than sprints, and suggesting a new paradigm for how organizations build internal utilities
- Dynamic field discovery: Field lists update automatically when datasets change, ensuring that newly added columns are immediately available for export without requiring app updates or maintenance
- Composable filter logic: Users can apply multiple filters across different fields simultaneously, creating complex extraction criteria through a visual interface without writing query syntax
- Dual-format export: Support for both Excel and CSV covers the two dominant use cases: users who need to work with the data in spreadsheets and users who need to import it into other systems that accept delimited files
Who This Agent Is For
This agent is designed for organizations where routine data extraction requests consume analytics team bandwidth and where business users need direct access to filtered, formatted data without technical intermediation.
- Business analysts who regularly need specific columns from large datasets for offline analysis, modeling, or combination with data from other sources
- Operations teams that share filtered data extracts with external partners, vendors, or customers who cannot access the platform directly
- Finance teams that pull platform data into their own spreadsheets and models on recurring schedules
- Analytics managers looking to eliminate routine extraction requests from their team's workload and redirect that capacity toward higher-value analysis
Ideal for: BI administrators, analytics directors, operations managers, and any organization where "can you pull this data for me?" is one of the most common requests the analytics team receives.

Metadata Builder AI Agent
AI agent that auto-generates comprehensive dataset descriptions and column-level tags by analyzing schema and sample data, triggered by a simple dataset selection in a self-service app, improving data discovery and governance consistency.
The data catalog listed 2,000 datasets. Fewer than 200 had descriptions. Column-level documentation existed for maybe 50. Data stewards had been asked to fix this for three years. The backlog only grew.
The Metadata Builder AI Agent was built to solve a governance problem that manual processes have consistently failed to address: the metadata gap. Every data organization knows that datasets need descriptions, columns need documentation, and tags need to be applied for discoverability. And every data organization has a backlog of undocumented datasets that grows faster than the team can annotate. A data platform team managing several thousand datasets found that fewer than 10 percent had meaningful metadata. The rest had system-generated names, undocumented columns, and no tags. Users searching for data either asked someone who knew where things were or browsed aimlessly until they found something that looked right. The agent eliminates the manual annotation bottleneck by allowing any user to select a dataset and trigger automated generation of descriptions and tags for every column, using AI analysis of the schema and sample data.
Benefits
This agent transforms metadata management from a perpetual backlog into a scalable, one-click operation that produces consistent documentation across the entire data catalog.
- Instant metadata generation: What previously took a data steward 30 to 60 minutes per dataset, reviewing schemas, writing descriptions, and applying tags, is completed in seconds with a single dataset selection
- Catalog-wide coverage: The agent makes it practical to document every dataset in the catalog rather than only the ones that receive manual attention, eliminating the documentation gap between frequently-used and rarely-accessed datasets
- Consistent classification: Tags and descriptions follow the same vocabulary, structure, and level of detail across all documented datasets, removing the inconsistency that occurs when different stewards document datasets in their own style
- Improved data discovery: Rich metadata with meaningful descriptions and accurate tags makes datasets findable through search, reducing the time users spend hunting for the right data source
- Governance compliance: Automated metadata generation helps organizations meet governance requirements for dataset documentation without requiring proportional growth in the data stewardship team
Problem Addressed
Metadata is the infrastructure that makes data usable. Without descriptions, users cannot determine what a dataset contains without opening it. Without column documentation, analysts cannot distinguish between similarly named fields across different tables. Without tags, search returns noise instead of signal. Every data governance framework includes metadata management as a foundational requirement. And every data team has a metadata backlog that never shrinks.
The reason is simple arithmetic. Documenting a dataset properly, writing a description, reviewing each column's contents, assigning meaningful descriptions, and applying classification tags, takes 30 to 60 minutes of focused work by someone who understands both the data and the governance taxonomy. A data platform with 2,000 datasets requires 1,000 to 2,000 hours of annotation work. Even if the data stewardship team could dedicate half their time to metadata (they cannot, because they have governance reviews, access requests, and quality investigations), the backlog would take over a year to clear. And during that year, new datasets would be created without metadata, adding to the backlog at roughly the same rate it was being reduced. The problem is structural: manual metadata creation does not scale with data proliferation.
What the Agent Does
The agent operates as a one-click metadata generation pipeline triggered from a self-service application interface:
- Dataset selection: Users select any dataset from the catalog through a simple application interface, requiring no technical knowledge of schemas, APIs, or metadata systems
- Schema analysis: The agent examines the dataset's column names, data types, cardinality, and relationships to build an initial understanding of the dataset's structure and content
- Sample data inspection: Analyzes a representative sample of the dataset's actual values to understand the semantic content of each column beyond what schema metadata reveals
- Description generation: Produces a human-readable description for the dataset and each individual column, explaining what the data represents, its likely source, and its intended use in terms that both technical and business users can understand
- Tag application: Applies classification tags from the governance taxonomy to each column and the dataset as a whole, categorizing data by domain, sensitivity, data type, and business function
- Metadata publication: Writes the generated metadata back to the data catalog, making descriptions and tags immediately available to all users searching for or browsing datasets
Standout Features
- Schema plus sample intelligence: The agent combines structural schema analysis with actual data value inspection, producing descriptions that reflect what the data actually contains rather than just what the column names suggest, catching cases where column names are abbreviated, misleading, or generic
- Taxonomy-aligned tagging: Tags are not free-form labels. They are selected from the organization's governance taxonomy, ensuring that AI-generated metadata is compatible with existing classification systems and governance workflows
- One-click operation: The entire workflow is triggered by selecting a dataset in the app. There are no configuration screens, parameter settings, or multi-step wizards. A user selects a dataset, clicks generate, and metadata appears
- Incremental enrichment: The agent can be run on datasets that already have partial metadata, filling in gaps without overwriting existing human-authored descriptions, making it useful for both initial documentation and ongoing maintenance
Who This Agent Is For
This agent is designed for data organizations where the metadata backlog has become a governance liability and where manual annotation cannot scale to match the rate of dataset proliferation.
- Data stewards responsible for maintaining metadata quality across a data catalog that is growing faster than their team can document
- BI administrators who manage data platforms where users struggle to find the right datasets due to missing or inconsistent metadata
- Data governance leaders who need to demonstrate compliance with documentation requirements without proportional growth in stewardship headcount
- Analysts who want to self-serve metadata generation for the datasets they use most frequently rather than waiting for the stewardship queue
Ideal for: Chief Data Officers, data governance managers, BI platform administrators, and any organization where the data catalog contains hundreds or thousands of datasets and the metadata coverage rate is a known deficiency.

Investment Analysis AI Agent
AI agent that applies machine learning to market data using multiple modeling approaches for side-by-side comparison, then connects to trading APIs to execute orders based on model output, creating an end-to-end automated investment pipeline.
Two modeling approaches. The same market data. One is faster to build. The other is more customizable. Which one actually performs better? Until you run them side by side on the same data, you are guessing.
The Investment Analysis AI Agent was built for quantitative teams that need to move from market data to trade execution without the manual handoffs that slow down every step of the pipeline. A financial services team was evaluating machine learning approaches for stock analysis but faced two challenges simultaneously: selecting the right modeling methodology and automating the execution of model-driven signals. Traditional approaches required building models in one environment, evaluating results in another, and executing trades through a third. Each handoff introduced latency, manual error risk, and the possibility that market conditions changed between signal generation and execution. The agent solves both challenges by providing a unified environment where multiple ML approaches run against the same data for direct comparison, and an AI-driven execution layer that translates model output into API-based trade orders.
Benefits
This agent collapses the investment analysis pipeline from a multi-tool, multi-handoff process into an integrated environment where modeling, evaluation, and execution happen within the same system.
- Objective model comparison: Running multiple ML approaches against identical data with identical evaluation criteria removes the subjective bias that affects model selection when approaches are evaluated in isolation or across different time periods
- Reduced signal-to-execution latency: Automated trade execution based on model output eliminates the manual handoff between analysis and trading, ensuring that signals are acted upon before market conditions shift
- Methodology transparency: Side-by-side comparison makes the performance differences between modeling approaches visible and quantifiable, supporting informed decisions about which approach to deploy for production trading
- Reproducible research: The integrated environment maintains a complete record of data inputs, model configurations, predictions, and execution results, creating an auditable trail that supports regulatory compliance and strategy refinement
- Scalable signal processing: The agent processes market data across the full investment universe without manual screening, identifying opportunities that human analysts might miss when constrained to a watchlist
Problem Addressed
Quantitative investment teams operate at the intersection of data science and execution, and most of their tooling was not designed for that intersection. Model development happens in notebooks or ML platforms. Backtesting happens in separate environments with separate data pipelines. Signal evaluation happens in spreadsheets or custom dashboards. And trade execution happens through broker interfaces or order management systems. Each step is optimized for its own domain but disconnected from the others. A data scientist builds a model that shows promising backtest results. She hands the model parameters to a trader, who implements the signals manually. By the time the trades are placed, the model's predictions are hours old and the edge may have decayed.
The methodology selection problem compounds this. A team evaluating whether to use automated ML platforms versus custom notebook-based models faces an evaluation challenge that is itself time-consuming. Building the same strategy in both environments, running both against the same data, and comparing results fairly requires significant effort. Most teams pick one approach based on familiarity or ease of deployment rather than empirical performance comparison. The result is either suboptimal model selection or duplicated effort maintaining parallel approaches without a clean comparison framework.
What the Agent Does
The agent operates as an integrated investment research and execution platform:
- Market data ingestion: Connects to market data feeds and ingests price, volume, fundamental, and alternative data across the target investment universe, maintaining a current and historical data repository for model training and signal generation
- Dual-methodology modeling: Runs machine learning models using both automated ML platforms and custom notebook-based approaches against the same data, enabling direct performance comparison under identical conditions
- Model evaluation framework: Provides standardized evaluation metrics including accuracy, precision, recall, Sharpe ratio, maximum drawdown, and signal decay analysis across both modeling approaches for objective comparison
- Signal generation: Produces ranked investment signals from the selected model or ensemble of models, identifying opportunities and risk events across the investment universe with confidence scores and time horizon estimates
- API-based trade execution: An AI agent layer translates model signals into trade orders and executes them through connected broker APIs, handling order sizing, timing, and confirmation without manual intervention
- Performance attribution: Tracks the real-world performance of executed trades against model predictions, providing feedback data that informs model refinement and methodology selection over time
Standout Features
- Head-to-head model comparison: The system does not just run two models. It provides a structured comparison framework with identical data splits, evaluation windows, and performance metrics that make the differences between approaches quantifiable and defensible
- AI-mediated execution: The execution layer is not a simple order router. An AI agent interprets model signals in the context of current market conditions, position sizing rules, and risk limits before generating orders
- Methodology-agnostic architecture: The platform supports both code-free automated ML and fully custom model development, allowing teams to start with automated approaches and graduate to custom models as their quantitative capabilities mature
- Closed-loop performance tracking: Every prediction, signal, order, and trade outcome is tracked in a unified data model that connects model output to real-world results, creating the feedback loop necessary for continuous model improvement
Who This Agent Is For
This agent is designed for investment teams that want to apply machine learning to market data and need a unified environment that handles modeling, evaluation, and execution without the fragmentation of multi-tool workflows.
- Quantitative analysts evaluating ML approaches for systematic investment strategies who need a clean comparison framework
- Portfolio managers seeking to automate the signal-to-execution pipeline to reduce latency and manual intervention
- Data science teams in financial services exploring the application of ML to investment decision-making with a focus on practical deployment
- Research teams that need reproducible, auditable investment experiments for regulatory compliance and strategy documentation
Ideal for: Quantitative portfolio managers, algorithmic trading teams, financial data scientists, and any investment operation where the gap between model output and trade execution represents both a performance drag and an operational risk.
Support Knowledge AI Agent
AI agent that analyzes incoming support inquiries, searches document repositories for relevant evidence, and returns accurate answers with direct citations to source materials, reducing resolution time and ensuring verifiable responses.
The answer existed. It was on page 34 of a configuration guide uploaded last quarter. The support agent did not know that document existed. The customer waited three hours for an answer that was already written.
The Support Knowledge AI Agent was built to bridge the gap between organizational knowledge and support response speed. A technology support organization maintained a substantial library of documentation: configuration guides, troubleshooting procedures, release notes, known issue databases, and best practice documents. The knowledge was comprehensive and well-maintained. But when a support agent received an inquiry, finding the relevant information within that library was the bottleneck. Agents relied on memory, keyword searches, and colleague recommendations to locate answers. Senior agents with years of experience could find the right document quickly. Junior agents often could not. The result was inconsistent response times, variable answer quality, and a systematic disadvantage for customers whose tickets happened to be assigned to less experienced agents. The agent eliminates that variance by searching the entire document library for every inquiry and returning answers with direct citations to source materials.
Benefits
This agent transforms the support experience by ensuring that every inquiry benefits from the full depth of organizational knowledge, regardless of which agent handles the ticket.
- Dramatically faster resolution: Answers that previously required 20 to 60 minutes of document searching are returned in seconds, compressing the most time-consuming phase of support resolution into an automated step
- Verifiable, cited responses: Every answer includes direct citations to source documents, enabling both support agents and customers to verify the information and access additional context from the original material
- Consistent quality regardless of experience: A first-week support agent receives the same quality of document-backed answers as a five-year veteran, eliminating the experience-dependent quality variance that previously created uneven customer experiences
- Full knowledge utilization: The agent searches the entire document repository for every inquiry, surfacing relevant information from documents that individual agents might not know existed, ensuring that the organization's full knowledge investment is leveraged
- Reduced escalation volume: Inquiries that were previously escalated because the assigned agent could not locate the answer are now resolvable at the first tier, reducing the escalation load on senior engineers and specialists
Problem Addressed
Support organizations invest heavily in documentation. They write guides, maintain knowledge bases, publish best practices, document known issues, and create troubleshooting flowcharts. The investment makes sense: well-documented solutions should enable faster, more consistent support. But documentation is only valuable if the person who needs it can find it at the moment they need it. And that is where the system breaks down.
A support agent receives a customer inquiry about a configuration issue. She opens the knowledge base and types in a keyword. The search returns 47 results, most of them tangentially related. She refines the search, tries different terms, and eventually finds a document that seems relevant. She reads through it, determines that it addresses a similar but not identical scenario, and tries again. Thirty minutes have passed. The customer is waiting. A senior agent sitting two desks away could have pointed her to the right document in 30 seconds, but he is handling his own tickets and did not see the question. The problem is not that the answer does not exist. The problem is that the cost of finding it scales with the size of the knowledge base and inversely with the experience of the searcher. The more documentation the organization creates, the harder it becomes for less experienced agents to navigate it effectively.
What the Agent Does
The agent operates as an intelligent knowledge retrieval system that stands between incoming inquiries and the document repository:
- Inquiry analysis: Processes incoming support inquiries to understand the core question, the product or feature context, the customer's environment details, and the level of specificity needed in the response
- Document repository search: Searches across the full document library including configuration guides, troubleshooting procedures, release notes, known issue databases, and best practice documents to identify all potentially relevant materials
- Evidence extraction: Identifies the specific sections, paragraphs, and procedures within matched documents that directly address the inquiry, extracting the relevant content rather than returning entire documents
- Answer synthesis: Combines evidence from one or more source documents into a coherent, direct answer to the inquiry, resolving any conflicts between sources and presenting the most current and relevant information
- Citation attachment: Associates every factual claim in the answer with a specific citation to the source document, section, and page, enabling verification and providing a path to additional context
- Confidence signaling: Indicates the confidence level of each answer based on the relevance and recency of the matched source materials, flagging cases where the available documentation may not fully address the inquiry
Standout Features
- Full-library search on every inquiry: Unlike keyword-based search that depends on the query terms matching document language, the agent performs semantic search across the entire repository, finding relevant answers even when the inquiry uses different terminology than the documentation
- Multi-document synthesis: When an answer requires information from multiple sources, the agent synthesizes across documents and presents a unified response with citations to each source, handling the cross-referencing that is most time-consuming for human agents
- Citation-first architecture: Citations are not an afterthought. The agent is designed around the principle that every answer must be traceable to source material, ensuring that generated responses are grounded in documented knowledge rather than general language model output
- Confidence-calibrated responses: The agent distinguishes between well-documented scenarios where it can provide definitive answers and edge cases where the documentation provides partial coverage, helping support agents decide when to trust the automated answer and when to investigate further
Who This Agent Is For
This agent is designed for support organizations where the volume and diversity of inquiries have outgrown the capacity of individual agents to maintain encyclopedic knowledge of the documentation library.
- Technical support teams handling product inquiries across a broad documentation library where finding the right answer is more time-consuming than communicating it
- Customer success organizations that need to maintain consistent response quality across agents with varying levels of experience and product knowledge
- Internal IT helpdesks where employees submit inquiries about procedures, policies, and configurations documented across multiple knowledge repositories
- Support managers looking to reduce escalation rates by ensuring that first-tier agents have immediate access to the full depth of organizational knowledge
Ideal for: Support directors, knowledge management leads, customer success VPs, and any organization where the cost of searching for answers exceeds the cost of communicating them, and where citation-backed responses are essential for customer trust and regulatory compliance.

Store P&L Insights AI Agent
AI agent that analyzes store-level profit and loss data on a monthly cadence, generates plain-language HTML summaries explaining performance drivers, and publishes them to a self-service app where regional managers access insights without waiting for finance.
Fifty stores. Twelve months of data. Every period-end, the same question from every regional director: "What happened at my stores?" And every period-end, the same answer: "We will get back to you when we finish the analysis."
The Store P&L Insights AI Agent was built for retail organizations where the gap between data availability and data interpretation creates a recurring bottleneck at every reporting cycle. A multi-location retail company tracked profit and loss at the store level with clean, monthly data feeds. The numbers were there: revenue, cost of goods, labor, occupancy, marketing spend, and net contribution for every store in every period. But the numbers alone did not tell the story. Store managers needed to understand why their margin dropped three points. Regional directors needed to know which locations were driving or dragging portfolio performance. Finance needed to communicate performance narratives without writing 50 individual analysis reports. The agent closes that gap by automatically analyzing each store's P&L data, generating plain-language summaries that explain performance drivers, and publishing those summaries to a self-service application where anyone with the right access can read their store's story immediately.
Benefits
This agent eliminates the delay between P&L data landing and performance narratives being available, giving every level of the retail organization instant access to store-level intelligence.
- Instant period-end insights: Store performance summaries are available as soon as the monthly data loads, eliminating the days or weeks of waiting that previously separated data availability from analytical interpretation
- Consistent analysis quality: Every store receives the same depth of analysis regardless of whether it is a top performer or a struggling location, removing the triage that previously caused underperforming stores to receive deeper scrutiny while stable stores received none
- Self-service access: Regional directors and store managers access their performance summaries directly through the app without requesting reports from finance, reducing email volume and eliminating the queue that formed around period-end analysis
- Scalable across locations: Adding new stores to the portfolio requires no additional analysis capacity because the agent processes every store automatically, making the approach viable whether the organization operates 10 locations or 500
- Narrative-driven understanding: HTML summaries explain performance in plain language rather than presenting raw numbers, helping operational managers who are not financial analysts understand what drove their results and what requires attention
Problem Addressed
Retail finance teams live in a permanent tension between data completeness and analysis speed. The monthly P&L data arrives, and the clock starts. Regional directors want to know how their territory performed. Store managers want to understand their numbers. The CFO wants a portfolio view with commentary. And the finance team, which spent the first week closing the books, now has to spend the second week analyzing them. For a 50-store chain, that means 50 individual P&L packages to review, interpret, and communicate. Most teams triage, analyzing the best and worst performers in detail and providing thin coverage for the middle majority.
The stores that most need analytical attention are often the ones that get the least. A store that is slowly declining does not trigger the "worst performer" threshold, so it receives a standard-format report with numbers but no narrative. The store manager looks at the numbers, sees a small margin decline, and assumes it is within normal variance. Three months later, the decline has compounded and now it is a problem that required earlier intervention. The issue is not data availability. The P&L data is complete, accurate, and timely. The issue is interpretation capacity. There are not enough analysts to write thoughtful performance narratives for every store every month. So the narratives are reserved for the exceptions, and the routine performance of most stores goes unexamined until it becomes exceptional.
What the Agent Does
The agent operates as an automated P&L analysis and communication pipeline for multi-location retail organizations:
- Monthly data ingestion: Monitors the P&L data pipeline and triggers automatically when new monthly data arrives for any store, beginning analysis as soon as the numbers are available without waiting for manual initiation
- Store-level performance analysis: Analyzes each store's P&L across all major categories including revenue trends, margin changes, cost structure shifts, labor efficiency, and contribution variance against both prior period and budget targets
- Driver identification: Determines the primary factors driving each store's performance, distinguishing between revenue-driven changes, cost-driven changes, and structural shifts that require different management responses
- HTML summary generation: Produces formatted, readable HTML summaries for each store that present the analysis in plain language with appropriate highlighting of key metrics, trends, and action items
- Automated storage: Saves each generated summary to the application database with store and period metadata, making summaries instantly retrievable through the self-service interface
- App-based distribution: Publishes summaries to a custom application where authorized users can access their store or regional summaries, browse historical periods, and compare performance across locations
Standout Features
- Workflow-triggered automation: The entire pipeline from data arrival to published summary runs without human initiation, using workflow triggers that detect new data and orchestrate the analysis, generation, and storage sequence automatically
- Contextual narrative generation: Summaries do not just report numbers. They explain them, identifying whether a margin decline was driven by revenue softness, cost increases, or mix shifts, and framing the explanation in terms that operational managers can act on
- Historical pattern recognition: The agent compares current performance against multi-period trends, flagging accelerating declines, seasonal anomalies, and sustained improvements that single-period analysis would miss
- Universal coverage with zero triage: Every store receives the same analytical treatment regardless of performance status, ensuring that gradually declining locations receive the same attention as dramatic outliers
Who This Agent Is For
This agent is designed for retail organizations where the volume of locations makes manual P&L analysis a bottleneck and where operational managers need narrative context to understand and act on their performance data.
- Retail finance teams responsible for producing store-level performance analysis across multi-location portfolios
- Regional and district directors who need timely, interpretive summaries of their territory's performance without waiting for finance team analysis
- Store managers who need to understand the drivers behind their P&L results in plain language rather than raw financial data
- CFOs and finance leadership seeking consistent, scalable performance communication across growing store portfolios
Ideal for: Retail finance directors, regional VPs, operations leaders, and any multi-location business where the combination of location count and reporting frequency creates more analytical demand than the finance team can serve manually.

Product Idea Analyzer AI Agent
AI agent that processes user-submitted product ideas at scale, analyzing submissions for trends and feasibility, prioritizing based on community engagement signals, and drafting personalized responses to keep the feedback loop active.
The ideas forum had 400 open submissions. Every one of them represented a customer who took the time to write down what they needed. Six months later, most had no response. Not because the product team did not care, but because there was no scalable way to process them.
The Product Idea Analyzer AI Agent was built to solve the scaling problem inherent in community-driven product feedback. A product organization maintained an ideas exchange forum where users submitted feature requests, enhancement suggestions, and workflow improvement proposals. The forum worked exactly as intended: it generated a rich stream of user feedback with community voting to signal demand. But processing that feedback at the rate it arrived was impossible with manual review. Each submission required reading, categorization, comparison against the existing roadmap, assessment of technical feasibility, and ideally a response acknowledging the idea and communicating its status. Product managers could handle perhaps 10 to 15 thorough reviews per week. The forum generated 30 to 50 new submissions in the same period. The backlog grew, response rates dropped, and engaged users began to question whether the forum was monitored at all.
Benefits
This agent transforms the ideas exchange from a growing backlog into an actively managed feedback pipeline where every submission is analyzed, categorized, and responded to at the speed of submission.
- Scale-matched processing: The agent processes submissions at the rate they arrive, eliminating the backlog growth that occurs when manual review capacity falls behind submission volume
- Trend identification across submissions: AI analysis surfaces patterns across hundreds of submissions that no individual reviewer could detect, identifying clusters of related requests that signal broad demand for specific capabilities
- Consistent categorization: Every idea is classified against the same criteria and mapped to the same roadmap categories, removing the inconsistency that occurs when different product managers interpret and tag submissions differently
- Faster community engagement: Automated response drafting ensures that every submitter receives a thoughtful, contextual acknowledgment rather than silence, maintaining community trust in the feedback process
- Priority-informed roadmap input: Upvote patterns, submission clusters, and engagement metrics feed directly into prioritization views that help product leadership allocate resources based on validated community demand
Problem Addressed
User feedback forums create a paradox for product teams: the more successful the forum, the harder it becomes to manage. When a forum is working well, users submit detailed, thoughtful proposals because they believe their input matters. Community members vote on submissions, creating a signal layer that indicates demand. The forum becomes a valuable source of product intelligence. And then it breaks, not from technical failure, but from operational overwhelm.
Product managers cannot read, categorize, assess, and respond to submissions at the rate they arrive. The backlog grows. Response times extend from days to weeks to months. Users who submitted ideas see no acknowledgment and no status updates. Voters who upvoted popular ideas see no movement. The community signal that made the forum valuable begins to degrade as engaged users conclude that the feedback loop is broken. The irony is acute: the organization built a system to listen to its users and then could not process what it heard. The problem is not willingness but capacity. Each submission requires genuine analytical attention, and that attention does not scale with headcount growth in the product team.
What the Agent Does
The agent operates as an intelligent triage and engagement system for user-submitted product ideas:
- Submission ingestion: Monitors the ideas forum for new submissions and processes each one immediately upon arrival, extracting the core request, proposed solution, use case context, and any technical specifications included by the submitter
- Intelligent categorization: Classifies each idea against the product taxonomy including feature area, product module, user persona, and roadmap theme, applying consistent criteria that align with how the product team organizes its planning
- Duplicate and cluster detection: Identifies when new submissions are related to existing ideas, duplicates of previous requests, or part of emerging clusters that signal growing demand for specific capabilities
- Trend analysis: Aggregates submission patterns, voting activity, and engagement metrics to surface the themes and capabilities generating the most community interest over configurable time windows
- Response drafting: Generates personalized, contextual responses for each submission that acknowledge the idea, reference any related submissions or roadmap alignment, and communicate the appropriate status, ready for PM review and posting
- Priority scoring: Combines submission frequency, vote counts, engagement velocity, and strategic alignment to produce priority scores that inform roadmap planning discussions
Standout Features
- Cluster intelligence: The agent goes beyond simple duplicate detection to identify thematic clusters across submissions that use different language to describe related needs, surfacing demand signals that keyword matching would miss
- Contextual response generation: Draft responses are not templates. They reference the specific content of each submission, acknowledge related ideas from other community members, and provide status information relevant to the specific feature area
- Engagement velocity tracking: Beyond static vote counts, the agent monitors how quickly submissions accumulate engagement, distinguishing between ideas that generated brief interest and those that show sustained community momentum
- Roadmap alignment scoring: Each idea receives an alignment score against the current product roadmap, helping PMs quickly identify submissions that complement planned work versus those that represent new strategic directions
Who This Agent Is For
This agent is designed for product organizations where user feedback volume has outgrown the capacity of manual review, and where community engagement depends on responsive acknowledgment of submitted ideas.
- Product managers responsible for monitoring and responding to user feedback forums, idea exchanges, or feature request systems
- User research teams that need to synthesize community feedback into structured insights without manual classification of every submission
- Community managers who need to maintain engagement and trust by ensuring that every submission receives timely acknowledgment
- Product leadership that needs aggregated demand signals from user feedback to inform roadmap prioritization discussions
Ideal for: VP of Product, product managers, community managers, and user research leads in organizations where the ideas exchange or feedback forum receives 30 or more submissions per week and the response backlog is growing faster than the team can process it.

Enterprise Data Chat AI Agent
AI agent that connects conversational AI interfaces to any enterprise dataset via MCP server integration, enabling natural-language data queries and automated document generation including PRDs and pricing proposals stored as downloadable files.
The data was there. Hundreds of datasets, perfectly maintained. But every question still required someone who knew which dataset to query, how to write the filter, and where to export the result. The bottleneck was never the data. It was the interface.
The Enterprise Data Chat AI Agent was built to dissolve the barrier between business questions and data answers. A technology organization had invested heavily in data infrastructure, building a comprehensive library of datasets covering product usage, customer telemetry, pipeline metrics, and operational KPIs. The data was clean, current, and well-structured. But accessing it still required either technical query skills or a request to someone who had them. Product managers waited for analysts to pull numbers. Sales engineers spent time building custom queries for customer demos. Executives asked questions in meetings that could not be answered until someone ran a report afterward. The agent eliminates that translation layer entirely, providing a conversational interface that can reach into any dataset, answer questions in natural language, and generate formal documents like PRDs and pricing proposals that are stored as downloadable files.
Benefits
This agent makes every dataset in the organization accessible through natural conversation, while extending beyond simple queries into automated document generation that serves multiple business functions.
Problem Addressed
Data democratization has been an organizational aspiration for a decade, and most companies have made real progress on the infrastructure side. Datasets are clean, pipelines are reliable, and dashboards are plentiful. But the last mile, the gap between a business user having a question and getting an answer, remains stubbornly wide. A product manager wants to know how many customers used a specific feature last quarter. The data exists. But accessing it requires knowing which dataset contains the usage metrics, what the field names are, how the customer segments are defined, and how to write the query. So the product manager messages an analyst, waits for a slot in their queue, and gets the answer tomorrow. The analyst, meanwhile, spent 20 minutes on a query that took 10 seconds to run.
The document generation gap is equally persistent. A solutions consultant needs a pricing proposal customized to a prospect's usage profile. The data to build that proposal is available, but assembling it into a professional document requires manual extraction, formatting, and review. An engineering lead needs a PRD that incorporates current product metrics. The metrics exist in dashboards, but transferring them into a structured document is a manual process. In both cases, the data is available but the path from data to deliverable requires human assembly work that could be automated.
What the Agent Does
The agent operates as a conversational data interface with integrated document generation capabilities:
Standout Features
Who This Agent Is For
This agent is designed for organizations where data infrastructure is mature but the interface between business users and data remains a bottleneck that limits the speed and frequency of data-informed decisions.
Ideal for: Product leaders, sales engineering teams, solutions consultants, and any function where the gap between "the data exists" and "I have the answer" costs hours of analyst time and days of decision latency.

Deal Intelligence AI Agent
AI agent that extracts action items and risk signals from opportunity transcripts, scores deal health, and provides a conversational coaching interface with full deal context for sales teams to accelerate pipeline velocity.
The transcript from last Tuesday's discovery call is 47 minutes long. Somewhere in it, the prospect mentioned a competitor, flagged a budget concern, and asked for a timeline. The rep remembers two of those three. The deal progresses without the third.
The Deal Intelligence AI Agent was built because sales organizations lose winnable deals not from lack of effort but from lack of signal extraction. Every customer conversation generates valuable intelligence: buying signals, competitive mentions, objections, technical requirements, and implicit deadlines. But that intelligence is trapped in call recordings and transcript files that no one has time to re-read. A sales organization with a growing pipeline found that reps consistently missed follow-up items buried in lengthy transcripts, and managers had no scalable way to coach deals without sitting through every recording. The agent solves both problems simultaneously, extracting structured intelligence from unstructured conversations and making that intelligence available through a coaching interface that understands the full context of every deal.
Benefits
This agent transforms raw conversation data into structured deal intelligence and actionable coaching, closing the gap between what was said in meetings and what gets executed in the sales process.
- Complete action item capture: Every task, commitment, and follow-up mentioned in any call is automatically extracted and surfaced, eliminating the reliance on rep memory and incomplete notes that previously caused dropped commitments
- Early risk detection: Competitive mentions, budget objections, timeline concerns, and stakeholder hesitations are flagged automatically from transcript content, surfacing deal risks that would otherwise remain buried until they became blockers
- Scalable deal coaching: Managers can coach any deal in the pipeline through a conversational interface that has full transcript context, making informed coaching possible without the time investment of listening to every call recording
- Consistent opportunity hygiene: Structured extraction ensures that every opportunity record stays current with the latest conversation intelligence, reducing the CRM data decay that undermines forecasting accuracy
- Faster ramp for new reps: New team members can use the coaching interface to understand deal history, context, and recommended next steps without requiring extensive one-on-one time with managers or tenured reps
Problem Addressed
Sales conversations are where deals are won or lost, but the intelligence generated in those conversations evaporates almost immediately. A rep finishes a 45-minute discovery call and jots down three bullet points in the CRM. Those three bullets represent maybe 10 percent of the actionable information from the conversation. The other 90 percent, the competitive mention at minute 12, the budget concern expressed as a question at minute 28, the implicit deadline tied to the prospect's board meeting at minute 39, all of that lives only in the recording that no one will listen to again.
Sales managers face the same problem from the coaching side. To provide meaningful deal coaching, a manager needs to understand what happened in the conversation. But with 15 reps running three to five calls each per day, there is no way to listen to even a fraction of the recordings. Managers end up coaching based on what the rep tells them happened, which is filtered through the rep's own biases, memory limitations, and blind spots. The result is a systematic intelligence leak across the entire pipeline. Deals stall because follow-up items were forgotten. Risks compound because warning signals were not extracted. Coaching misses the mark because it is based on incomplete information. The problem is not the quality of the conversations. It is that the intelligence in those conversations is not being systematically captured and made actionable.
What the Agent Does
The agent operates as a comprehensive conversation intelligence pipeline that transforms raw transcripts into structured deal data and coaching insights:
- Transcript ingestion: Processes opportunity transcripts from call recordings, extracting the full conversational content and associating it with the relevant deal record and stage in the pipeline
- Action item extraction: Identifies every commitment, follow-up task, and next step mentioned by either party during the conversation, structuring them as assignable to-do items with context about when and why they were discussed
- Risk signal detection: Flags competitive mentions, budget concerns, timeline pressures, stakeholder objections, and other risk indicators with severity scoring based on conversational context and deal stage
- Deal health scoring: Aggregates extracted signals across all conversations for a given opportunity to produce a composite deal health score that reflects both momentum indicators and risk factors
- Conversational coaching interface: Provides a chat-based interface where managers and reps can ask questions about any deal and receive contextual answers drawn from the full transcript history, enabling informed coaching without listening to recordings
Standout Features
- Full-context conversational coaching: The chat interface does not just retrieve transcript snippets. It understands the full arc of the deal across all conversations, enabling questions like "What concerns has the prospect raised about implementation?" that synthesize across multiple calls
- Multi-signal risk scoring: Risk detection goes beyond keyword matching to assess severity based on conversational dynamics, deal stage, and historical patterns, distinguishing between a casual competitor mention and an active evaluation
- Bi-directional action tracking: The agent extracts commitments made by both the sales team and the prospect, tracking not just what the rep promised to deliver but also what the prospect agreed to do, providing a complete picture of deal momentum
- Pipeline-level pattern recognition: Aggregated analysis across all active deals surfaces organizational patterns such as recurring objections, common competitive threats, and stage-specific risks that inform strategy beyond individual deal coaching
Who This Agent Is For
This agent is designed for sales organizations where the volume of customer conversations has outgrown the capacity of manual review and note-taking to capture the intelligence those conversations contain.
- Sales managers responsible for coaching teams of five or more reps across active pipeline deals who cannot listen to every call recording
- Account executives managing complex, multi-stakeholder deals where missed signals and dropped follow-ups directly impact win rates
- Revenue operations teams seeking to improve forecast accuracy by grounding CRM data in actual conversation intelligence rather than rep-entered summaries
- Sales enablement leaders looking for scalable coaching tools that provide deal-specific guidance without requiring manager availability
Ideal for: VP of Sales, revenue leaders, sales managers, and frontline reps in B2B organizations where deal cycles are measured in weeks or months and the intelligence from customer conversations is a critical competitive advantage.

Ticket Resolution AI Agent
AI agent that analyzes incoming development tickets, identifies information gaps to request clarification, generates fix hypotheses for well-documented issues, and orchestrates iterative resolution workflows with engineering teams.
Every ticket that lands in the backlog starts the same way: someone reads it, decides whether there is enough information to act, and either asks a question or starts investigating. That triage step happens hundreds of times a week, and it is almost entirely pattern-matchable.
The Ticket Resolution AI Agent was built for engineering organizations drowning in the overhead of initial ticket triage. At a mid-sized technology company, the development team received a steady flow of issue tickets that varied wildly in quality. Some contained detailed reproduction steps, stack traces, and environment specifications. Others contained a single sentence and a screenshot. Regardless of quality, each ticket required a senior developer to read it, assess its completeness, decide on an initial approach, and either respond with questions or begin debugging. That triage step consumed between 15 and 45 minutes per ticket and scaled linearly with ticket volume. The agent automates that entire first pass, handling the read-assess-respond cycle so developers engage only when the ticket is ready for resolution work.
Benefits
This agent removes the initial triage bottleneck from engineering workflows, ensuring that developers spend their time solving problems rather than reading incomplete tickets and asking for more information.
- Elimination of triage overhead: Developers no longer spend 15 to 45 minutes per ticket on the initial read-and-assess cycle, reclaiming hours each week that were consumed by pattern-matchable evaluation work
- Faster time to clarity: Incomplete tickets receive automated clarification requests within minutes of submission rather than sitting in queue until a developer has time to read them, compressing the information-gathering phase from days to hours
- Higher-quality first responses: The agent applies consistent evaluation criteria to every ticket, ensuring that no required detail is overlooked and that clarification requests are specific and actionable rather than generic
- Accelerated resolution through hypothesis generation: Well-documented tickets receive an initial fix hypothesis immediately, giving developers a starting point that reduces the investigation phase and gets them into solution mode faster
- Iterative refinement loop: The second-stage workflow maintains context across multiple exchanges with the developer, building on the initial hypothesis rather than starting fresh with each interaction
Problem Addressed
The ticket queue is the universal bottleneck of software development. Not because the issues are too hard to solve, but because the process of reading, evaluating, and responding to each ticket is slow, repetitive, and unevenly distributed. A developer opens a ticket expecting a clear problem statement and finds three words and a partial screenshot. She asks for more details. Two days pass before the reporter responds. She reads the update, realizes she needs one more piece of information, and asks again. Another day passes. The actual debugging work has not started, but the ticket is already five days old.
Now consider the other side: a well-documented ticket with complete reproduction steps, logs, and environment details sits in the queue for three days because the same developer is busy triaging the incomplete ones. The paradox is that the best tickets wait the longest because the worst tickets consume the most triage time. Engineering organizations have tried templates, required fields, and submission guidelines. These help at the margins but do not solve the fundamental problem: every ticket still requires a human to read it, evaluate it against a mental model of what a good ticket contains, and decide what to do next. That evaluation is the bottleneck, and it is the step this agent automates.
What the Agent Does
The agent operates as a two-stage automated triage and resolution pipeline that sits between ticket submission and developer engagement:
- Ticket intake analysis: Monitors the ticket queue for new submissions and performs immediate analysis of each ticket's content, evaluating completeness against configurable criteria including reproduction steps, environment details, error messages, expected behavior, and actual behavior
- Intelligent clarification: When a ticket lacks sufficient information for resolution, the agent posts a specific, actionable comment requesting exactly what is missing, using context from the ticket content to ask targeted questions rather than generic templates
- Fix hypothesis generation: For tickets that contain sufficient information, the agent generates an initial hypothesis about the root cause and potential fix approach, drawing on patterns from historical ticket data and codebase context
- Developer iteration workflow: A second-stage workflow takes the fix hypothesis and facilitates iterative exchanges with the assigned developer, maintaining full context across interactions so each response builds on previous analysis
- Resolution tracking: Monitors the outcome of each interaction cycle, tracking which hypotheses led to successful fixes and feeding that information back to improve future analysis accuracy
Standout Features
- Two-stage workflow architecture: Unlike simple auto-responders, the agent uses a deliberate two-stage design where the first workflow handles triage and the second handles resolution iteration, allowing each stage to be tuned and monitored independently
- Context-aware clarification: Clarification requests are generated based on what the ticket actually contains rather than what it is missing from a static checklist, producing questions that feel relevant and specific rather than boilerplate
- Hypothesis confidence scoring: Each fix hypothesis includes a confidence level based on how closely the ticket matches known patterns, helping developers prioritize which suggestions to pursue and which to treat as starting points for deeper investigation
- Continuous learning loop: The agent tracks resolution outcomes to refine its triage criteria and hypothesis generation over time, becoming more accurate as it processes more tickets within the specific codebase and team context
Who This Agent Is For
This agent is designed for engineering organizations where ticket triage consumes developer time that should be spent on resolution, and where ticket quality variance creates unpredictable workloads.
- Development teams managing high-volume ticket queues where initial triage is a recognized bottleneck in the resolution pipeline
- Engineering managers looking to reduce the time between ticket submission and meaningful developer engagement
- DevOps and platform teams handling operational tickets that follow recognizable patterns amenable to automated hypothesis generation
- QA and support escalation teams that need faster turnaround on bug reports without adding developer headcount to triage rotations
Ideal for: Engineering directors, development leads, DevOps managers, and any engineering organization processing 50 or more tickets per week where the triage-to-resolution pipeline has become the primary constraint on throughput.

Executive Report AI Agent
AI agent that synthesizes multiple data sources including dashboards, strategic documents, and calendars into comprehensive weekly executive summaries with branded presentation slides ready for leadership review.
Executive reporting consumed hours every week. The same dashboards, documents, and calendars had to be manually stitched together into a coherent narrative, then formatted into branded slides. It was a high-skill task that added no strategic value.
The Executive Report AI Agent was built to eliminate the mechanical overhead of weekly leadership communication. A marketing organization needed to consolidate performance dashboards, leadership update documents, and campaign calendars into a single executive-ready deliverable every week. The process required someone to log into the analytics platform, extract the relevant metrics, cross-reference them against strategic priorities documented elsewhere, overlay the upcoming calendar, and then manually compose both a written summary and a branded presentation slide. The entire workflow took two to three hours, and the output quality varied depending on who performed it and how much time they had. The agent replaces that entire chain with a single automated pipeline that produces consistent, comprehensive, and presentation-ready output.
Benefits
This agent transforms weekly executive reporting from a manual synthesis exercise into an automated pipeline that delivers consistent, branded output without human compilation effort.
- Zero manual compilation: The agent pulls data from dashboards, documents, and calendars automatically, eliminating the two to three hours previously spent gathering and cross-referencing information from multiple sources each week
- Consistent branded output: Every weekly deliverable follows the same format and brand standards, removing the quality variance that occurred when different team members handled the task on rotating schedules
- Faster leadership alignment: Summaries are available at the start of the week rather than mid-morning after manual preparation, giving executives earlier access to the information they need for Monday decisions
- Dual-format delivery: The agent produces both a detailed written summary for thorough review and a branded presentation slide for quick visual reference, serving different consumption preferences without doubling the work
- Reduced context-switching: Marketing team members no longer need to interrupt strategic work to perform data gathering and formatting tasks, preserving focus for higher-value activities
Problem Addressed
Every Monday morning looked the same. Someone on the marketing team opened three browser tabs: the performance dashboard, the leadership update document, and the campaign calendar. They spent the next two hours copying numbers, interpreting trends, cross-referencing planned activities against actual results, and writing a narrative that tied it all together. Then they opened a slide template and condensed that narrative into a single branded presentation page. By the time the summary reached leadership, the morning was gone.
The problem was not complexity. Each individual source was straightforward. The problem was repetition and synthesis. The same person or a rotating designee performed the same extraction, the same cross-referencing, and the same formatting every single week. When the task fell to someone less familiar with the data, the summary missed nuances. When it fell to someone short on time, the branded slide was rushed. The output was never bad enough to trigger a redesign but never reliable enough to stop requiring human oversight. Organizations that depend on regular leadership communication face this pattern constantly: a task that is too important to skip, too routine to justify senior attention, and too multi-source to automate with simple scheduling.
What the Agent Does
The agent operates as an end-to-end reporting pipeline that ingests multiple data sources and produces executive-ready deliverables:
- Dashboard data extraction: Connects to the marketing performance dashboard and pulls current-week metrics including campaign performance, pipeline contribution, engagement rates, and budget utilization without manual login or screenshot capture
- Document synthesis: Reads the leadership update document to extract strategic context, priority shifts, wins, and blockers that provide the narrative framework around the raw numbers
- Calendar integration: Pulls upcoming events, campaign launches, and milestone dates from the marketing calendar to contextualize the data within the forward-looking schedule
- Summary generation: Combines all three sources into a structured written summary that presents metrics in the context of strategic priorities and upcoming activities
- Branded slide creation: Produces a presentation-ready slide following organizational brand guidelines, condensing the key takeaways into a visual format suitable for executive meetings
Standout Features
- Multi-source fusion engine: Unlike simple report schedulers that pull from a single dashboard, this agent synthesizes three distinct information types: quantitative metrics, qualitative narrative, and temporal calendar data into a unified deliverable that reflects how executives actually consume information
- Brand-compliant slide generation: The presentation output adheres to organizational design standards automatically, including color palettes, typography, logo placement, and layout structure, so the slide is meeting-ready without manual formatting passes
- Narrative intelligence: The agent does not simply concatenate data points. It structures the written summary to lead with the most significant developments, contextualize metrics against strategic priorities, and highlight upcoming activities that require leadership attention
- Configurable cadence and recipients: While designed for weekly execution, the agent supports custom scheduling and distribution lists, adapting to organizations that report on different cycles or need summaries routed to different stakeholder groups
Who This Agent Is For
This agent is designed for organizations where executive reporting is a regular obligation that consumes skilled-worker time without generating strategic value from the compilation process itself.
- Marketing teams responsible for producing weekly or biweekly leadership summaries that combine performance data with strategic narrative
- Chiefs of staff and executive assistants who compile multi-source briefings for senior leaders on recurring schedules
- Operations managers who synthesize cross-functional dashboards into unified status reports for leadership review
- Any team where the reporting deliverable requires merging quantitative data with qualitative context and calendar awareness
Ideal for: CMOs, VPs of Marketing, Chiefs of Staff, and any leadership support function where the weekly reporting ritual consumes hours that could be spent on analysis and strategy rather than compilation and formatting.

Survey Sentiment Analysis AI Agent
No-code survey analysis agent that ingests employee feedback, auto-translates non-English responses, classifies comments across thematic categories using AI, and delivers interactive dashboards where leaders can slice sentiment data by department, location, and topic.
The surveys went out six months ago. The responses came back weeks later. And here you are, three months into the analysis, still manually reading and coding individual comments while the workforce waits for the results.
Employee surveys are supposed to be a listening tool. The organization asks, employees answer, and leadership acts on what they hear. That is the theory. In practice, the bottleneck is not collecting the responses. It is making sense of them. When a large organization surveys thousands of employees, the resulting dataset contains thousands of free-text comments in addition to the quantitative ratings. Those comments are where the real intelligence lives: the specific frustrations, the concrete suggestions, the emotional signals that a five-point scale cannot capture. But extracting that intelligence from thousands of individual responses written in different styles, languages, and levels of detail is a massive manual effort that most organizations drastically underestimate when they design their survey programs.
A national memorial services organization with locations across North America experienced this directly. They administered comprehensive employee surveys every six months, and every cycle the same pattern repeated. The quantitative data was tabulated quickly. The free-text responses landed on someone's desk. And then months of manual reading, coding, and categorization began. By the time the analysis was complete and dashboards were built, nearly half the survey cycle had elapsed. Employees who had shared their feedback months earlier saw no evidence that anyone had listened. The Survey Sentiment Analysis AI Agent was built to collapse that timeline from months to hours.
Benefits
This agent transforms employee survey analysis from a months-long manual project into an automated pipeline that delivers actionable insights within hours of survey close.
- Months of analysis compressed to hours: Free-text responses that previously required weeks of manual reading and coding are processed, categorized, and visualized automatically, delivering complete thematic analysis the same day the survey closes
- Every response analyzed, not sampled: Manual analysis often resorts to sampling when volume is overwhelming. The agent processes every single response, ensuring that minority perspectives, emerging concerns, and location-specific issues are captured regardless of their frequency
- Language barriers removed: Non-English responses are automatically translated before analysis, ensuring that employees who respond in their preferred language are included in the thematic analysis rather than being set aside for separate manual translation
- Interactive exploration by leadership: Instead of receiving a static PDF report, leaders get filterable dashboards where they can slice sentiment data by department, location, tenure, theme, and time period, enabling the specific comparisons that drive targeted action
- Consistent categorization across cycles: The agent applies the same thematic classification to every survey cycle, enabling true period-over-period comparison that shows whether specific concerns are improving, stable, or worsening over time
- Credibility with the workforce: When employees see that their feedback is analyzed and presented quickly after submission, it reinforces the message that leadership takes the survey seriously, increasing participation and candor in future cycles
Problem Addressed
The survey analysis problem is a time-value problem. Employee feedback has a half-life. The insights contained in survey responses are most valuable immediately after collection, when the experiences that prompted them are fresh and the organizational conditions that produced them are still current. Every week that passes between survey close and insight delivery reduces the relevance of the findings. Conditions change. Staff turns over. Initiatives launch. By the time a three-month analysis cycle produces its final report, the organization the report describes may not fully match the organization that exists today.
Manual analysis is slow because the task is genuinely difficult. Reading a free-text survey response, understanding its meaning, assigning it to one or more thematic categories, and recording the sentiment requires human judgment that cannot be shortcut without sacrificing quality. A skilled analyst might process 50 to 100 responses per hour at full concentration. An organization with 5,000 responses is looking at 50 to 100 hours of analyst time just for the coding phase, before any dashboard creation, cross-tabulation, or report writing begins. And that analyst time must be sustained at a quality level that ensures consistent categorization from the first response to the five-thousandth. Fatigue, interpretation drift, and the sheer monotony of the task all degrade quality over time. The result is that organizations either accept a months-long analysis timeline or compromise on analysis quality by sampling, abbreviating, or skipping the free-text responses entirely. Both options undermine the purpose of conducting the survey.
What the Agent Does
The agent implements a no-code survey analysis pipeline that processes raw responses through translation, categorization, and visualization stages:
- Response ingestion: Survey response data is ingested from the survey platform, with free-text comments separated from quantitative ratings and associated with respondent metadata including department, location, tenure bracket, and role category
- Automatic language detection and translation: Non-English responses are detected, identified by language, and translated into the analysis language before entering the categorization pipeline, ensuring multilingual workforces are fully represented in the analysis
- AI-powered thematic classification: Each free-text response is analyzed and assigned to one or more thematic categories from a configurable taxonomy of workplace topics such as management quality, compensation, work-life balance, career development, communication, safety, recognition, and culture
- Sentiment scoring: Responses are scored for sentiment polarity and intensity, distinguishing between mildly positive comments and strongly positive ones, and between constructive criticism and frustrated venting, adding emotional dimension to the thematic analysis
- Cross-dimensional aggregation: Categorized and scored responses are aggregated across all available dimensions, respondent metadata, theme, sentiment, and survey cycle, creating the multi-dimensional dataset that powers interactive dashboard exploration
- Interactive dashboard delivery: Results are presented through filterable dashboards where leaders can examine thematic distributions, sentiment trends, departmental comparisons, and period-over-period changes at whatever level of granularity their decisions require
Standout Features
- No-code pipeline architecture: The entire analysis pipeline runs within a visual ETL environment, making it maintainable by HR analytics teams without requiring data engineering or machine learning expertise to operate or modify
- Multi-theme assignment: Unlike simple classification that assigns each response to a single category, the agent recognizes that a single comment often addresses multiple topics and assigns it to every relevant theme, preventing the information loss that single-label classification creates
- Configurable theme taxonomy: The thematic categories used for classification can be customized per survey cycle or survey type, allowing the agent to adapt its analysis focus as organizational priorities and survey instruments evolve
- Period-over-period trending: Because the agent applies consistent classification logic across survey cycles, the resulting dashboards can show genuine longitudinal trends that reveal whether interventions are working, concerns are growing, or new themes are emerging
- Drill-down to source responses: Dashboard users can navigate from aggregate theme-level metrics down to the individual responses that comprise them, preserving the connection between statistical patterns and the human voices that created them
Who This Agent Is For
This agent is designed for organizations that conduct employee surveys at a scale where manual analysis of free-text responses creates an unacceptable delay between data collection and insight delivery.
- HR leaders at organizations with 1,000+ employees who survey their workforce regularly and need results fast enough to act on while the feedback is still current
- People analytics teams responsible for turning raw survey data into actionable intelligence for department heads, site managers, and executive leadership
- Organizations with multilingual workforces where non-English responses are currently excluded from analysis or processed separately at significant additional cost
- Employee experience teams managing survey programs where previous analysis cycles took so long that results lost relevance before they reached decision-makers
- Any organization where the gap between asking employees for feedback and acting on that feedback has undermined workforce trust in the survey process
Ideal for: CHROs, HR analytics directors, employee experience managers, and people operations leaders at organizations with 500+ employees where survey analysis bottlenecks have created a credibility gap between the promise of listening and the reality of acting on what employees say.

Call Transcription & QA AI Agent
AI-powered call analysis agent that transcribes and evaluates 100% of member service interactions, automatically flags key moments for quality review, generates composite QA scores, and delivers scalable insights that replace manual sampling with comprehensive coverage.
A scalable speech-to-text and quality analysis pipeline that processes 100% of customer interactions, replacing statistical sampling with comprehensive automated evaluation
Quality assurance in contact center operations has traditionally operated under a fundamental constraint: manual review cannot scale to cover the full interaction volume. The standard approach, randomly sampling 2-5% of calls and having QA analysts listen, score, and document their evaluations, produces a statistically limited view of service quality that misses the vast majority of interactions where coaching opportunities, compliance risks, and exceptional performance occur. A financial services organization serving a large membership base recognized that this sampling limitation was not just an efficiency problem but an intelligence gap. The interactions their QA program never reviewed contained patterns, risks, and opportunities that their quality metrics could not reflect because the data was never collected.
The Call Transcription and QA AI Agent implements an automated speech-to-text and interaction analysis pipeline that processes every recorded call, generates structured transcripts, applies multi-dimensional quality scoring, and flags specific interaction moments for targeted human review, transforming QA from a sampling exercise into a comprehensive evaluation system.
Benefits
This agent fundamentally changes the QA operating model from probabilistic sampling to deterministic full-coverage analysis, with corresponding improvements in quality insight depth and coaching precision.
- 100% interaction coverage: Every call is transcribed and analyzed regardless of volume, eliminating the coverage gap that causes manual QA to miss significant interaction patterns, compliance events, and performance outliers that fall outside the random sample
- Consistent scoring methodology: The automated QA model applies identical evaluation criteria to every interaction, removing the inter-rater variability that causes the same call to receive different quality scores depending on which analyst reviews it
- Targeted human review: Rather than asking QA analysts to listen to randomly selected calls, the agent surfaces the specific interactions and moments that warrant human attention, directing expert review time toward the highest-value coaching and compliance opportunities
- Real-time quality visibility: Quality metrics update continuously as calls are processed rather than accumulating over monthly review cycles, enabling team leads to identify and address performance trends before they become entrenched patterns
- Scalable without proportional QA headcount: As call volume grows, the agent processes additional interactions without requiring additional QA analyst hours, maintaining full coverage at any volume level
- Searchable interaction intelligence: Full transcripts create a searchable corpus of customer interactions that can be queried for specific topics, competitor mentions, product feedback, and complaint patterns that structured QA scores alone would not capture
Problem Addressed
The mathematical constraint of manual QA is well understood but rarely addressed directly. An organization processing 50,000 member calls per month with a QA team that can review 200 calls per month is evaluating 0.4% of its interactions. The quality scores generated from that 0.4% are treated as representative of the full population, but they are not. They are a random sample with a confidence interval so wide that meaningful conclusions about individual agent performance, specific interaction types, or emerging quality trends are statistically unreliable. An agent who handles 500 calls per month may have two or three reviewed. The probability that those specific calls represent that agent's typical performance is low. The probability that the sample captures their worst interaction, their best coaching opportunity, or the compliance lapse that happened on a Tuesday afternoon is lower still.
Beyond the statistical limitation, manual QA introduces temporal latency that diminishes its impact. A call reviewed three weeks after it occurred generates a coaching recommendation for a behavior the agent may have already changed or repeated dozens of times in the interim. The feedback loop between interaction and improvement is measured in weeks rather than the days or hours that would make coaching interventions most effective. The combination of low coverage, reviewer variability, and delayed feedback means that manual QA programs produce metrics that feel authoritative but reflect a narrow, temporally displaced, and inconsistently evaluated fraction of actual service quality.
What the Agent Does
The agent implements a multi-stage pipeline that converts raw call recordings into structured, scored, and searchable interaction intelligence:
- Audio ingestion and preprocessing: Call recordings are ingested from the telephony platform, with audio normalization, noise reduction, and channel separation applied to optimize transcription accuracy across varying recording quality levels
- Speech-to-text transcription: Preprocessed audio is transcribed using speech recognition models tuned for the organization's domain vocabulary, member terminology, and product language, with speaker diarization separating agent and member contributions
- Interaction segmentation: Transcripts are segmented into functional phases such as greeting, identification, issue statement, resolution, and closing, creating a structured interaction map that supports phase-specific quality evaluation
- Multi-dimensional QA scoring: Each interaction is evaluated across configurable quality dimensions including compliance adherence, issue resolution effectiveness, communication clarity, empathy indicators, and process following, producing a composite score with dimension-level detail
- Key moment flagging: The agent identifies and timestamps specific interaction moments that warrant human attention, including potential compliance events, escalation triggers, exceptional service delivery, coaching opportunities, and member sentiment inflection points
- Searchable transcript repository: All transcripts are indexed in a searchable repository with metadata tagging for agent, date, topic, quality score, and flagged moments, enabling both individual interaction review and corpus-level pattern analysis
Standout Features
- Domain-adapted speech recognition: The transcription model is tuned for the organization's specific vocabulary, including financial product terminology, membership categories, and common abbreviations, producing higher accuracy transcripts than generic speech-to-text services
- Configurable quality rubric: QA scoring dimensions, weights, and thresholds are fully configurable, allowing the organization to evolve its quality standards and have those changes reflected immediately across all future interaction evaluations without model retraining
- Sentiment trajectory mapping: Beyond static sentiment classification, the agent tracks how member sentiment evolves throughout each interaction, identifying calls where sentiment improved, deteriorated, or remained flat, and correlating those trajectories with specific agent behaviors
- Comparative agent analytics: Full-coverage scoring enables statistically valid performance comparisons across agents, teams, shifts, and time periods, replacing the unreliable agent-to-agent comparisons that small-sample manual QA produces
- Topic extraction and trending: The agent identifies recurring topics, product mentions, and complaint categories across the interaction corpus, surfacing trends that individual QA reviews would not detect because they operate at the single-call level rather than the population level
Who This Agent Is For
This agent is engineered for contact center operations where the gap between manual QA coverage and total interaction volume represents an unacceptable quality intelligence deficit.
- QA managers responsible for maintaining service quality standards across high-volume contact centers who need comprehensive evaluation coverage that manual review cannot provide
- Contact center operations leaders seeking to reduce QA program costs while simultaneously increasing coverage, consistency, and the speed of quality feedback loops
- Compliance teams in regulated industries that need provable evidence of interaction-level compliance adherence across 100% of customer contacts rather than sample-based estimates
- Training and development teams who need data-driven identification of coaching opportunities based on actual interaction patterns rather than anecdotal observation
- Customer experience executives who need corpus-level interaction intelligence, including topic trends, sentiment patterns, and service quality trajectories, to inform strategic CX decisions
Ideal for: QA program managers, contact center directors, compliance officers, and CX executives at financial services organizations, insurance companies, healthcare providers, and any high-volume service operation where comprehensive interaction analysis is a competitive and regulatory necessity.

PII Compliance Scrubbing AI Agent
Automated compliance agent that continuously scans CRM contact records, identifies entries exceeding data retention thresholds with populated sensitive PII fields, and automatically replaces those values with empty strings to maintain ongoing compliance with student data privacy regulations.
100% of sensitive student records scrubbed within retention limits. Zero compliance violations since deployment. Fully automated with no manual monitoring required.
Those compliance metrics represent the difference between an organization that hopes its data practices are compliant and one that knows they are. An education technology company working with school districts across the country faced a non-negotiable requirement: student personally identifiable information stored in their CRM could not be retained beyond a strict 21-day threshold. The regulation was clear. The enforcement was real. And the previous approach, manual compliance monitoring across thousands of contact records, was neither scalable nor reliable enough to guarantee that every record was handled correctly every time.
The PII Compliance Scrubbing AI Agent replaced that manual monitoring with continuous, automated enforcement. It scans CRM records against retention rules, identifies records that have exceeded the allowed retention period, and automatically removes sensitive field values, ensuring that the organization maintains provable, auditable compliance without dedicating staff time to record-by-record review.
Benefits
This agent delivers continuous compliance assurance that scales with record volume and eliminates the risk exposure inherent in manual data retention monitoring.
- Guaranteed retention compliance: Every contact record in the CRM is evaluated against retention rules on a continuous basis, ensuring that no sensitive PII persists beyond the allowed period regardless of record volume or system activity
- Zero-touch operation: Once configured, the agent runs without manual intervention, monitoring, or scheduling. Compliance happens automatically, eliminating the staff hours previously spent on manual record review and the risk of human oversight
- Eliminated regulatory exposure: The gap between when a record exceeds its retention limit and when its PII is scrubbed shrinks from days or weeks under manual monitoring to hours under automated enforcement, dramatically reducing the window of non-compliance
- Auditable compliance trail: Every scrubbing action is logged with the record identifier, the fields that were cleared, the timestamp, and the retention rule that triggered the action, creating documentation that proves compliance to regulators on demand
- Scalable across any record volume: Whether the CRM contains five thousand records or five hundred thousand, the agent processes all of them with the same thoroughness and speed, making compliance sustainable as the organization grows its district partnerships
- Preserved non-sensitive data: The agent targets only the specific PII fields that fall under retention requirements, leaving non-sensitive contact information intact for ongoing business operations and relationship management
Problem Addressed
Student data privacy regulations exist because the stakes are real. The information these organizations handle, student names, addresses, demographic details, assessment results, belongs to minors. Retaining it beyond allowed periods is not a procedural inconvenience. It is a violation that can result in lost contracts, regulatory penalties, and reputational damage that undermines trust with the school districts these organizations serve. The organizations subject to these regulations understand the requirements. The challenge is execution at scale.
Manual compliance monitoring fails for a mathematical reason: the number of records that need to be checked grows continuously while the staff available to check them does not. A CRM that adds hundreds of new contacts per week generates hundreds of records that will cross the 21-day retention threshold three weeks later. Someone needs to identify those records, verify which fields contain sensitive PII, and clear those values. Every day. For every record. The probability that a manual process catches every single record, every single day, without exception, is effectively zero at any meaningful scale. One missed record is one potential compliance violation. One hundred missed records during a busy week is a systemic failure waiting to be discovered during an audit. Automation is not a convenience for this use case. It is a regulatory necessity.
What the Agent Does
The agent implements a continuous compliance enforcement loop that monitors, identifies, and remediates PII retention violations automatically:
- CRM record scanning: The agent continuously queries the CRM system to identify contact records where the creation or last-modification date exceeds the configured retention threshold, evaluating the full record population on each scan cycle
- Sensitive field identification: For each record that exceeds the retention threshold, the agent evaluates a configured list of PII fields to determine which ones contain values that must be scrubbed, distinguishing between sensitive fields that require clearing and non-sensitive fields that should be preserved
- Automated value replacement: Identified PII field values are replaced with empty strings through CRM API operations, ensuring that the sensitive data is removed from the live record while the contact shell and non-sensitive data remain intact for business continuity
- Batch processing with rate limiting: Scrubbing operations are executed in controlled batches with appropriate API rate limiting to prevent CRM performance degradation, ensuring that compliance enforcement does not impact system availability for other users
- Compliance logging: Every scrubbing action is recorded in a dedicated compliance log with the record ID, field names cleared, timestamp, and the retention rule that triggered the action, creating the audit documentation needed to demonstrate systematic compliance
- Exception reporting: Records that cannot be processed due to API errors, permission issues, or unexpected data states are flagged for manual review and tracked until resolution, ensuring that no record falls through the cracks due to technical issues
Standout Features
- Configurable retention rules: The retention threshold, target PII fields, and scrubbing behavior are all configurable, allowing the agent to be adapted to different regulatory requirements without code changes as privacy regulations evolve or new field-level requirements are introduced
- Selective field targeting: Rather than deleting entire records, the agent precisely targets only the specific fields that contain regulated PII, preserving the contact relationship structure and non-sensitive data that the sales and success teams need for ongoing operations
- Continuous versus batch operation: The agent runs on a continuous monitoring cycle rather than a scheduled batch job, reducing the maximum possible retention overage from the batch interval length to the scan cycle duration
- CRM-native integration: Scrubbing operations execute through the CRM platform's native API, ensuring that all standard field-level security, audit logging, and workflow triggers within the CRM are respected during the remediation process
- Compliance dashboard: A monitoring interface displays real-time metrics including total records scanned, records scrubbed, fields cleared, current compliance percentage, and any exceptions requiring attention, giving compliance officers instant visibility into the program's effectiveness
Who This Agent Is For
This agent is designed for organizations operating under data retention regulations where the volume of records makes manual compliance monitoring unreliable and the consequences of non-compliance are severe.
- Education technology companies handling student PII under FERPA, state student privacy laws, and district-specific data retention agreements that mandate strict timeline enforcement
- Compliance and data privacy teams responsible for demonstrating ongoing adherence to retention requirements during regulatory audits and district compliance reviews
- CRM administrators managing large contact databases where PII fields must be systematically managed according to retention policies that vary by data type or regulatory context
- Healthcare organizations subject to data retention and disposal requirements for patient information stored in CRM or customer management systems
- Any organization that stores regulated personal information in CRM systems and needs automated enforcement to guarantee that retention limits are never exceeded
Ideal for: Compliance officers, data privacy managers, CRM administrators, and legal counsel at organizations where regulated PII retention limits are a contractual or regulatory requirement and the record volume makes manual enforcement an unacceptable compliance risk.

Employee Recognition Automation AI Agent
Workflow automation agent that identifies employees with upcoming work anniversaries, initiates congratulatory letter preparation and plaque ordering, determines the correct delivery method for each recipient, and ensures recognition arrives on the right day without any manual tracking.
Somewhere in the building, an employee just hit their five-year anniversary. Nobody noticed. The letter was never printed. The plaque was never ordered. And by the time someone realizes the date passed, the moment is gone.
Recognition matters. Every HR professional knows this. Every leadership team knows this. And yet the mechanics of actually delivering recognition, the letters, the plaques, the timing, the delivery logistics, collapse with remarkable consistency in organizations where the process is manual. It is not because people do not care. It is because remembering every anniversary date, coordinating with vendors, determining whether the recipient works in the office or remotely, and ensuring that everything arrives on the correct day is a logistical challenge that no one's primary job description includes. The task falls to whoever volunteers, gets added to someone's already-full task list, and gradually deteriorates from a meaningful employee experience into a sporadic, inconsistent afterthought.
A defense-focused organization with distributed teams across multiple locations lived this problem every quarter. The HR team would pull anniversary reports, identify who was approaching a milestone, and then begin the manual work of coordinating letters, ordering plaques, and figuring out whether each employee should receive their recognition at the office or at home. With remote and hybrid employees mixed in, the delivery logistics alone consumed hours. The Employee Recognition Automation AI Agent was built to make this entire process invisible to the people running it and meaningful to the people receiving it.
Benefits
This agent ensures that every employee milestone is acknowledged on time, every time, without any human being needing to remember, track, or coordinate a single detail.
- Zero missed milestones: Every work anniversary in the organization is automatically identified and scheduled for recognition, eliminating the human memory failures and spreadsheet oversights that cause some employees to be celebrated while others are forgotten
- End-to-end automation: From identifying the anniversary to printing the letter to ordering the plaque to routing the delivery, every step happens without manual intervention, freeing HR staff from a repetitive logistics process that consumed hours each quarter
- Correct delivery, every time: The agent determines whether each employee works on-site or remotely and routes recognition materials to the office or mailing address accordingly, handling the delivery logic that is the most error-prone part of manual recognition programs
- Timely, not late: Recognition arrives on the actual anniversary date rather than days or weeks after, because the agent calculates lead times for printing, ordering, and shipping and initiates each step early enough to meet the deadline
- Consistent employee experience: Every employee receives the same quality of recognition regardless of their location, team, or whether the person who usually handles recognition was on vacation the week their anniversary fell
- Scalable without additional headcount: Whether the organization has 200 employees or 2,000, the agent processes every milestone with the same reliability, making recognition programs sustainable as the organization grows
Problem Addressed
The failure mode for employee recognition programs is not dramatic. It is quiet. An anniversary passes unacknowledged. An employee mentions it to a colleague. Word gets around. Meanwhile, another employee in a different department received a beautifully timed letter and plaque because their manager happened to be more organized. The inconsistency is worse than having no program at all, because it creates visible evidence that some people's milestones matter more than others. The damage is to trust, to engagement, to the belief that the organization means what it says about valuing its people.
The operational root cause is straightforward: manual processes cannot reliably track, coordinate, and execute logistics across dozens or hundreds of employees distributed across multiple locations with different delivery requirements. The data exists in the HR system. The anniversaries are calculable. The vendors are available. The addresses are on file. What is missing is the orchestration layer that connects all of those data points into an automated execution pipeline. Without that layer, the process depends on someone remembering to pull the report, someone remembering to cross-reference it with office locations, someone remembering to order the plaques early enough, and someone remembering to check that everything was delivered. Each "someone remembering" is a failure point, and the probability that all of them execute correctly every quarter approaches zero as the employee count grows.
What the Agent Does
The agent operates as a fully automated recognition workflow that connects HR data to vendor fulfillment and delivery logistics:
- Anniversary detection: The agent scans employee records on a configurable schedule to identify all work anniversaries falling within the upcoming quarter, generating a recognition queue that accounts for lead times required for each fulfillment step
- Letter generation and preparation: Congratulatory letters are automatically generated using employee-specific details including name, anniversary year, and role, formatted according to organizational templates, and queued for printing or digital delivery
- Plaque ordering and fulfillment: Recognition plaques are ordered from designated vendors with appropriate personalization details, order timing calculated backward from the delivery date to ensure on-time arrival
- Delivery method determination: The agent evaluates each employee's work arrangement, primary office location, and mailing address to determine whether recognition materials should be delivered to the office or mailed to their home
- Delivery routing and tracking: Materials are routed to the correct destination with delivery scheduled for the anniversary date, with tracking notifications sent to designated coordinators for confirmation
- Completion logging and reporting: Every recognition event is logged with delivery confirmation status, enabling HR to report on program completion rates and identify any items that require manual follow-up
Standout Features
- Lead time intelligence: The agent understands that a plaque ordered on Monday does not arrive on Tuesday. It calculates backward from each anniversary date to determine when each fulfillment step needs to start, ensuring nothing is ordered too late to arrive on time
- Hybrid workforce handling: With employees split between on-site, remote, and hybrid arrangements, the agent dynamically determines the correct delivery method for each individual rather than applying a one-size-fits-all delivery assumption
- Configurable milestone tiers: Different anniversary milestones can trigger different recognition packages, with five-year anniversaries receiving different materials than one-year or ten-year milestones, all configured once and executed automatically
- Manager notification loop: Managers are notified in advance of their direct reports' upcoming anniversaries, enabling them to add personal recognition alongside the automated fulfillment without bearing the logistical burden
- Exception escalation: When delivery failures occur, address issues are detected, or vendor fulfillment is delayed, the agent escalates to a human coordinator with full context so the issue can be resolved before the anniversary date passes
Who This Agent Is For
This agent is for organizations that believe employee recognition matters but have found that manual execution of recognition programs produces inconsistent, unreliable results.
- HR departments managing recognition programs across distributed workforces where tracking anniversaries and coordinating logistics exceeds what manual processes can handle reliably
- Office managers and executive assistants who have inherited recognition coordination responsibilities on top of their primary roles and need a system that runs itself
- People operations teams at growing organizations where the employee count has outpaced the ability to manually track and fulfill every milestone
- Government and defense organizations with strict recognition program requirements and distributed teams where delivery logistics are particularly complex
- Any organization that has experienced the reputational cost of inconsistent recognition and wants to ensure every employee's milestone is acknowledged on time
Ideal for: HR directors, people operations managers, office administrators, and organizational leaders at companies with 100+ employees where manual recognition processes have become unreliable and the employee experience cost of missed milestones is no longer acceptable.

Entity Formation Automation AI Agent
System integration agent that automates entity formation workflows by synchronizing entity records, registered agent data, and compliance information across multiple internal and external platforms whenever new entities are created or existing records are updated.
An integration architecture that synchronizes entity formation data across compliance, legal, and administration platforms in real time as records are created or modified
Entity formation at scale is a multi-system orchestration problem. When a new business entity is formed, the resulting record does not live in a single system. It is simultaneously relevant to legal compliance databases, registered agent management platforms, corporate administration tools, and regulatory filing systems. Each of these systems requires specific data fields populated in specific formats on specific timelines. A global provider of business administration and legal compliance services managing entity formations across multiple jurisdictions recognized that the manual coordination required to keep all of these systems synchronized was consuming operational capacity that should have been directed at client service delivery. Every new entity created a cascade of manual update tasks across platforms, and every manual update introduced the possibility of data inconsistency that could compromise compliance posture.
The Entity Formation Automation AI Agent implements a cross-platform integration layer that automatically propagates entity data between core business systems whenever a formation event occurs or an existing record is modified, ensuring referential consistency across the entire system landscape without manual intervention.
Benefits
This agent eliminates the manual data synchronization overhead that scales linearly with entity formation volume, replacing it with an automated integration layer that maintains consistency regardless of throughput.
- Referential integrity across all platforms: Entity data is propagated to every relevant system within seconds of creation or modification, eliminating the temporal gaps during which systems contain inconsistent versions of the same record
- Compliance confidence at scale: Regulatory filing systems receive entity data automatically and in the required format, removing the manual formatting and data entry steps where compliance errors are most likely to be introduced
- Administrative overhead reduced by 80%+: Staff who previously spent significant portions of their day copying entity data between platforms can redirect that time toward client advisory work, complex formation processing, and exception handling
- Scalable high-volume processing: The integration layer maintains consistent synchronization speed and accuracy whether the daily formation volume is ten entities or ten thousand, supporting business growth without proportional administrative headcount increases
- Eliminated data drift: In manual synchronization environments, records gradually diverge across platforms as updates are applied inconsistently. Automated bidirectional sync eliminates this drift entirely, ensuring every system reflects the current state of every entity
- Reduced client impact from processing delays: Faster end-to-end entity processing means clients receive formation confirmations, registered agent assignments, and compliance filings sooner, directly improving service delivery timelines
Problem Addressed
The architectural challenge in entity formation automation is not connecting two systems. It is maintaining bidirectional referential consistency across a heterogeneous platform landscape where each system has its own data model, validation rules, and update cadence. When a new entity is formed, the legal compliance database needs the entity name, jurisdiction, formation date, registered agent assignment, and officer/director details in its specific schema. The registered agent platform needs a subset of that data in a different format. The corporate administration tool requires additional fields that the compliance database does not track. And the regulatory filing system needs the data transformed into jurisdiction-specific formatting before submission.
Manual coordination of this data flow introduces three categories of risk. First, latency: the time between when data is entered in the primary system and when it is replicated in downstream systems creates windows during which platforms contain inconsistent information. Second, transformation errors: reformatting data between system-specific schemas during manual data entry introduces typos, field mapping mistakes, and formatting inconsistencies. Third, completeness gaps: when synchronization depends on human memory and checklist adherence, some downstream updates are inevitably missed, particularly during high-volume periods. These risks compound as entity volume increases, creating a governance problem that manual processes cannot solve at scale.
What the Agent Does
The agent operates as an event-driven integration middleware layer between core business platforms involved in entity formation and administration:
- Formation event detection: The agent monitors primary entity management systems for creation events and record modifications, capturing the full entity data payload including all fields relevant to downstream system synchronization
- Schema transformation engine: Captured entity data is transformed into the specific field formats, naming conventions, and data structures required by each target platform, applying jurisdiction-specific formatting rules where applicable
- Bidirectional propagation: Data flows in both directions across the platform landscape, ensuring that updates originating in any connected system are reflected in all others rather than requiring a single master record source
- Validation and conflict resolution: Before propagating data to target systems, the agent validates field completeness and format compliance, flagging conflicts where the same entity has been modified differently in multiple systems simultaneously
- Registered agent data synchronization: Registered agent assignments, address changes, and service of process records are synchronized across all platforms that track agent relationships, maintaining consistent agent-entity associations across the entire system landscape
- Synchronization monitoring and alerting: A monitoring layer tracks synchronization status across all platform pairs, alerting operations staff when propagation failures occur, retrying failed synchronizations automatically, and logging all sync events for audit purposes
Standout Features
- Event-driven architecture: Rather than running on batch synchronization schedules, the agent responds to entity events in real time, reducing the consistency gap from hours or days to seconds and ensuring that downstream systems are updated before any user queries them
- Jurisdiction-aware transformation: The schema transformation engine applies jurisdiction-specific formatting rules automatically, handling the state-by-state and country-by-country variations in entity data requirements without requiring manual configuration per jurisdiction
- Conflict resolution with audit trail: When concurrent modifications create data conflicts, the agent applies configurable resolution rules, logs the conflict and its resolution, and optionally alerts an administrator for review, maintaining data integrity without blocking synchronization
- Incremental sync with full reconciliation: Normal operations use efficient incremental synchronization, while a periodic full reconciliation pass identifies and corrects any drift that may have accumulated from edge cases, network issues, or system-specific processing delays
- Platform-agnostic connector framework: The integration layer uses a configurable connector architecture that supports adding new platform integrations without modifying the core synchronization engine, enabling the system to expand as the organization's platform landscape evolves
Who This Agent Is For
This agent is engineered for organizations that manage entity formation and corporate administration across multiple interconnected platforms where manual data synchronization creates operational risk and compliance exposure.
- Corporate services firms managing high-volume entity formations across multiple jurisdictions with data flowing between legal, compliance, and administration platforms
- Registered agent companies synchronizing entity assignments, address changes, and service records across client-facing and regulatory systems
- Legal compliance teams responsible for ensuring that entity data is consistently represented across all systems that feed into regulatory filings and audit documentation
- IT operations teams maintaining integrations between business-critical platforms where manual synchronization has become an unsustainable operational burden
- Business process automation teams evaluating opportunities to eliminate manual data propagation tasks that scale linearly with transaction volume
Ideal for: Integration architects, compliance operations managers, corporate services directors, and IT leaders at organizations where entity data consistency across multiple platforms is a regulatory requirement and manual synchronization is no longer viable at current formation volumes.

Contract Lifecycle Automation AI Agent
End-to-end contract automation agent that ingests multi-page agreements, extracts critical terms into structured datasets, tracks expiration dates with automated stakeholder notifications, and provides a conversational AI interface for instant natural-language queries about contract obligations and timelines.
Before this agent, finding one expiration date meant opening an 80-page contract and scrolling until you found it. Now it takes about three seconds and a question typed in plain English.
If you have ever managed contracts, you know the drill. The agreements live in a shared drive. Each one is dozens or hundreds of pages. When someone asks about a specific term, rate, or deadline, you open the document and start reading. When a renewal date approaches, you hope someone flagged it in a calendar. When compliance needs to know what obligations apply in a particular state, they send you an email and wait while you hunt through folder after folder. This is not a technology problem. It is a human bandwidth problem. The information exists. Finding it fast enough to be useful is where things fall apart.
A national behavioral health organization hit this wall hard. They managed hundreds of active contracts governing care delivery across multiple states. Every contract ran 80 pages or more. Every one contained critical information: rates, renewal dates, compliance requirements, termination clauses, performance metrics. And every time someone needed a specific data point, someone else had to go find it by hand. The Contract Lifecycle Automation AI Agent was built for exactly this situation: too many contracts, too many pages, too many deadlines, and not enough hours in the day to manage them manually.
Benefits
This agent turns your contract portfolio from a filing cabinet you dread opening into an intelligent system that works for you around the clock.
- No more manual contract review: The days of reading through 80-page agreements to find a single clause are over. The agent extracts every critical term and makes them instantly searchable, which means the answer to any contract question is seconds away instead of hours
- Deadlines that manage themselves: Expiration dates, renewal windows, and compliance deadlines trigger automatic notifications to the right stakeholders at the right time, so you stop discovering missed renewals after the fact and start addressing them proactively
- Ask questions in plain English: Instead of opening documents and ctrl-F searching through legal text, you type a question like a normal human being and get an answer with the exact clause and page number cited. Your team will actually use this, which is the whole point
- Compliance visibility without the spreadsheet: Contract obligations, approaching deadlines, and risk exposure are visible on a dashboard that updates itself. No more quarterly scrambles to compile compliance status from scattered documents
- Every new contract automatically processed: When a new agreement is added, the agent ingests it, extracts the terms, sets up the milestone tracking, and makes it queryable without anyone configuring anything. The system gets smarter as the portfolio grows
- Faster answers for everyone who asks: When executives, regulators, or partners want to know about specific contract terms, your team can respond in minutes with accurate, sourced information instead of requesting days to locate and review the right document
Problem Addressed
Contract management at scale is deceptively dangerous because the consequences of what you miss are usually worse than the consequences of what you get wrong. A renewal window that expires unnoticed can lock your organization into unfavorable terms for another full contract period. A compliance obligation buried on page 71 of a document last reviewed eighteen months ago can surface as a regulatory finding with real financial consequences. A rate change in an amendment that was filed but never extracted means your organization is operating on outdated financial assumptions.
The root cause is not negligence. It is architecture. When critical business data lives exclusively inside PDF documents stored in folder hierarchies, the organization's access to that data is limited to someone's willingness and ability to open the right document and find the right page. There is no search. There is no monitoring. There is no alerting. There is just a shared drive and the institutional hope that someone remembers to check it. Every additional contract added to the portfolio increases the surface area for something to be missed, and the consequences of missing it grow more expensive as the portfolio grows larger.
What the Agent Does
The agent runs an end-to-end pipeline that transforms static contract documents into a dynamic, queryable intelligence system:
- Multi-format document ingestion: Contracts in PDF, Word, and scanned formats are ingested from document repositories, with the agent processing documents of any length including the 80+ page agreements that create the most extraction value
- AI term extraction: Trained models analyze each document to identify and extract effective dates, expiration dates, renewal terms, rate schedules, performance obligations, termination conditions, and amendment provisions into structured data fields
- Structured dataset creation: Extracted terms are normalized into datasets that integrate with existing business intelligence tools, compliance dashboards, and reporting workflows so contract data is accessible wherever your team already works
- Milestone tracking with notifications: Every extracted deadline is monitored, with automated alerts sent to designated stakeholders at configurable intervals before renewals, compliance deadlines, and termination notice periods arrive
- Conversational query interface: A natural-language chat interface lets authorized users ask questions about any contract and receive immediate answers that cite specific clauses, page numbers, and document sections
- Portfolio analytics: Aggregated contract data surfaces organizational-level insights including total obligation exposure, upcoming renewal volume, rate variance across similar agreements, and compliance risk concentration
Standout Features
- Works with what you have: The agent handles PDFs, Word docs, and even scanned paper contracts with OCR, so you do not need to reformat or re-digitize your existing contract portfolio before getting value from the system
- Answers you can verify: Every conversational response includes document references, page numbers, and clause identifiers so that the person asking the question can verify the answer against the source material in seconds if needed
- Escalating notification cascades: Alerts start with the contract owner at 90 days, add management at 60 days, and escalate to leadership at 30 days, ensuring that critical deadlines get attention proportional to how close they are
- Cross-contract inconsistency detection: The agent flags situations where similar agreements contain materially different terms, helping your team identify renegotiation opportunities and standardization targets across the portfolio
- Always-current single source of truth: As new contracts are added and existing ones are amended, the structured dataset updates automatically. No more wondering whether the spreadsheet reflects the latest version of a document
Who This Agent Is For
This agent is for any team managing a contract portfolio large enough that keeping track of everything manually has become a liability rather than a process.
- Legal teams juggling multi-page agreements across states, jurisdictions, or service areas who need faster access to specific terms without full document review
- Compliance officers who must maintain visibility into contractual obligations and regulatory deadlines across a growing portfolio without manual tracking
- Contract administrators who manage hundreds of renewal dates, rate changes, and performance milestones and need proactive alerts instead of reactive discovery
- Healthcare and behavioral health organizations managing state-by-state service agreements with varying terms that are too numerous and complex for spreadsheet-based tracking
- Procurement and vendor management teams overseeing supplier agreements where missed renewal windows or overlooked terms create financial and operational exposure
Ideal for: General counsel, contract managers, compliance directors, procurement leads, and any organization managing 50+ active agreements where the cost of a missed deadline or an unanswered question represents real financial and regulatory risk.

Data Governance Automation AI Agent
Automated data governance agent that executes company-wide dataset certification, manages intelligent access controls for sensitive HR information, and streamlines administrative workflows while maintaining strict security compliance across the organization.
93% reduction in manual access review cycles. Full dataset certification across the organization. Zero sensitive data exposure incidents since deployment.
Those numbers represent the operational transformation that happens when data governance stops being a manual administrative burden and becomes an automated, continuously enforced system. A global legal services organization managing sensitive HR data across multiple jurisdictions deployed this agent to solve a problem that was consuming disproportionate administrative resources: ensuring that the right people had access to the right data at the right time, and that every dataset in the organization met certification standards, without requiring a team of administrators to manually review and approve every access request and certification renewal.
The Data Governance Automation AI Agent replaces manual governance workflows with intelligent, policy-driven automation that certifies datasets, manages access controls for sensitive information, and maintains continuous compliance visibility without the administrative overhead that makes manual governance unsustainable at scale.
Benefits
This agent delivers measurable governance outcomes that scale with organizational complexity rather than requiring proportional administrative headcount.
- Automated dataset certification: Every dataset in the organization is evaluated against governance policies on a continuous basis, with certification status maintained automatically rather than through periodic manual review cycles that consume weeks of administrator time
- Sensitive data protected by policy, not people: Access controls for HR data and other sensitive information are enforced by automated rules that apply consistently across every request, eliminating the human judgment variability that creates access control gaps during high-volume periods
- Administrative workload reduction of 90%+: Governance administrators who previously spent the majority of their time processing routine access requests and certification paperwork are freed to focus on policy development, risk assessment, and exception handling
- Real-time compliance posture visibility: Leadership has immediate access to the organization's governance status across all datasets, access controls, and certification metrics without waiting for quarterly reports compiled from manual audit data
- Consistent cross-jurisdictional enforcement: Governance policies are applied uniformly across all organizational units and geographies, ensuring that sensitive data protections meet the most stringent applicable requirement regardless of where the access request originates
- Audit-ready documentation at all times: Every governance action, from dataset certification to access grant or denial, is logged with policy justification and timestamps, creating a perpetual audit trail that eliminates the document assembly scramble before compliance reviews
Problem Addressed
Data governance at scale is fundamentally an automation problem masquerading as a people problem. Organizations respond to governance requirements by hiring administrators, creating review committees, and building approval workflows. These approaches work at small scale. At enterprise scale, they collapse under their own weight. Every new dataset requires certification. Every access change requires review. Every compliance audit requires documentation. The administrative burden grows linearly with data volume, and organizations that rely on manual governance processes eventually reach a point where the governance overhead consumes more resources than the activities it governs.
The risk is not just inefficiency. Manual governance creates gaps. When an administrator processes fifty access requests in a day, the quality of review on request number fifty is materially different from request number one. When dataset certification is a quarterly event, data quality issues discovered in week two persist for ten weeks until the next review cycle. When compliance documentation depends on manual compilation, the documentation reflects what was remembered and recorded, not necessarily what happened. Sensitive HR data demands better. Employee compensation records, performance reviews, medical information, and disciplinary histories require governance that is systematic, continuous, and verifiable. Manual processes can aspire to that standard. Automated governance achieves it.
What the Agent Does
The agent operates as a continuous governance enforcement layer across the organization's data infrastructure:
- Automated dataset discovery and classification: The agent continuously scans the data environment to identify new and modified datasets, automatically classifying them by sensitivity level based on content analysis and metadata evaluation
- Policy-driven certification workflows: Each dataset is evaluated against the applicable governance policies for its classification level, with certification granted automatically when all criteria are met and exceptions routed to designated reviewers when they are not
- Intelligent access control management: Access requests for sensitive data are evaluated against role-based policies, organizational hierarchy rules, and need-to-know criteria, with automatic provisioning for requests that meet all policy requirements
- Continuous compliance monitoring: The agent monitors all governed datasets for changes that affect their certification status, triggering re-evaluation when data schemas change, new fields are added, or content patterns shift in ways that may affect classification
- Exception escalation with context: Governance decisions that cannot be resolved by automated policy evaluation are escalated to human reviewers with full context including the specific policy criteria that were not met, the requestor's role and access history, and recommended actions
- Compliance reporting and audit trail: All governance actions are logged in a searchable audit system that generates compliance reports on demand, documenting every certification, access decision, and policy evaluation with timestamps and policy references
Standout Features
- Content-aware sensitivity detection: Beyond metadata-based classification, the agent analyzes actual data content to identify sensitive information patterns such as compensation figures, medical terms, and personally identifiable information, catching sensitivity that schema-level classification would miss
- Adaptive policy enforcement: Governance policies can be configured to vary by data classification, organizational unit, geography, and time period, allowing the agent to enforce jurisdiction-specific requirements without requiring separate governance instances per region
- Self-healing certification: When a dataset's certification lapses due to a detected change, the agent automatically evaluates whether the change affects governance requirements and can re-certify without human intervention if the change is within policy parameters
- Access pattern anomaly detection: The agent monitors data access patterns and flags unusual activity such as bulk downloads, access outside normal hours, or queries that span an abnormal breadth of sensitive records, adding a behavioral layer to static policy enforcement
- Governance posture dashboard: A real-time dashboard provides executives with organization-wide visibility into certification coverage, access control compliance, pending exceptions, and trend metrics that indicate whether governance health is improving or degrading over time
Who This Agent Is For
This agent is designed for organizations where data governance complexity has exceeded the capacity of manual administrative processes to maintain consistent, auditable compliance.
- Data governance teams responsible for certifying and monitoring datasets across enterprise-scale data environments with hundreds or thousands of active datasets
- HR and legal departments that manage sensitive employee data requiring strict access controls and continuous compliance with privacy regulations
- IT security teams tasked with enforcing data access policies across organizational units with varying sensitivity requirements and compliance obligations
- Compliance officers preparing for regulatory audits who need documented governance trails that cover every dataset and access decision in the organization
- Chief data officers building scalable governance frameworks that maintain rigor as data volume and organizational complexity increase
Ideal for: Chief data officers, governance program managers, HR data custodians, compliance directors, and IT security leaders at organizations where the volume of governed data has made manual governance processes a bottleneck to both operational efficiency and compliance assurance.

PDF Application Extraction AI Agent
AI-driven extraction agent that parses submitted PDF applications, automatically identifies and pulls structured data from unstructured form layouts, and routes extracted information through automated FileSet integration into downstream intake pipelines.
The applications arrive as PDFs. Dozens of them. And every single data point locked inside those forms has to be typed into the system by hand.
There is a particular kind of operational frustration that builds slowly and then suddenly becomes unbearable. It starts when an organization adopts a PDF-based application form because PDFs are universal, portable, and easy to distribute. Applicants fill them out. They submit them. And then someone on the receiving end has to open each one, read through every field, and manually transcribe the information into the intake system. One form takes five minutes. Ten forms take an hour. A hundred forms during peak intake season means someone is doing nothing but data entry for days at a stretch. The work is mind-numbing, the error rate climbs with every hour, and the bottleneck it creates ripples through every downstream process that depends on having that data available.
A children's services nonprofit experienced this pain at scale. Their intake process depended on PDF applications that families submitted for developmental and educational programs. Each application contained critical information, names, addresses, program selections, medical details, emergency contacts, that needed to be extracted and entered into their case management system before services could begin. The gap between when an application was received and when its data was actually usable in the system was entirely determined by how fast a staff member could type. The PDF Application Extraction AI Agent exists to close that gap permanently.
Benefits
This agent eliminates the manual data entry layer between receiving a PDF application and having its contents available in downstream systems.
- Intake bottleneck eliminated: Applications that previously sat in a queue waiting for manual transcription are processed within minutes of submission, removing the single biggest delay in the intake pipeline and getting services started faster for the families who need them
- Error rates drop dramatically: AI extraction reads every field with consistent precision regardless of volume, eliminating the transposition errors, missed fields, and misread handwriting that accumulate during manual data entry sessions
- Staff refocused on mission-critical work: Team members who previously spent hours on data entry can redirect that time toward case management, family engagement, and program delivery, the work they were actually hired to do
- Peak season scalability: During high-volume enrollment periods, the agent processes application surges without additional staffing, maintaining the same extraction speed and accuracy whether the queue contains ten forms or ten thousand
- Downstream system activation: Extracted data flows directly into intake pipelines through automated FileSet integration, triggering downstream workflows, case assignments, and eligibility checks without waiting for manual data handoffs
- Consistent data quality: Every extracted field passes through the same validation logic, ensuring that the data entering the intake system meets format and completeness requirements before it reaches a case manager's screen
Problem Addressed
The problem is deceptively simple on the surface: data is trapped inside PDF files. But the operational impact of that trapped data radiates outward through the entire organization. When an application arrives as a PDF, the information it contains does not exist in any system. It exists on a page. Someone has to convert that page into structured data before anything useful can happen with it. Until that conversion happens, the applicant is waiting. The case manager has nothing to work with. The eligibility system has no input. The enrollment report is incomplete. One bottleneck creates a cascade of delays that affect everyone downstream.
The organizations most affected by this problem are the ones where speed of intake directly impacts the people they serve. When a family submits an application for developmental services for their child, every day of delay between submission and processing is a day that child is not receiving support. When the delay is caused not by a complex eligibility determination but by the simple mechanical act of retyping information from a PDF into a database, the organizational cost is not just operational. It is mission-critical. And the problem scales linearly: twice the applications means twice the data entry, twice the delay, and twice the downstream impact. There is no efficiency gain from experience because the work is irreducibly manual without automation.
What the Agent Does
The agent operates as an automated extraction and routing pipeline that converts unstructured PDF applications into structured intake data:
- PDF intake monitoring: The agent monitors designated submission channels for incoming PDF applications, automatically queuing new submissions for processing as they arrive without manual triggering or batch scheduling
- AI-powered field extraction: Each PDF is analyzed using trained document understanding models that identify form fields, extract values, and map them to the corresponding data schema regardless of formatting variations, scan quality, or mixed handwritten and typed content
- Data validation and normalization: Extracted values pass through validation rules that check format compliance, required field completeness, and value range constraints, flagging incomplete or ambiguous extractions for review before they enter the intake pipeline
- Automated FileSet integration: Validated extraction results are packaged and routed through automated FileSet workflows that deliver structured data to downstream intake systems, case management platforms, and eligibility determination processes
- Exception handling and human routing: Applications with extraction confidence below threshold or validation failures are routed to designated staff with the partially extracted data pre-populated, so human reviewers complete only the fields that need attention rather than processing the entire form manually
- Processing metrics and status tracking: Every application's extraction status, confidence scores, validation results, and routing decisions are logged and accessible through a monitoring dashboard that provides real-time visibility into pipeline throughput and quality
Standout Features
- Layout-adaptive extraction: The agent handles PDF applications with varying layouts, field positions, and formatting conventions without requiring template configuration per form type, adapting its extraction strategy to the document structure it encounters
- Mixed-input recognition: Forms containing both typed and handwritten entries are processed with specialized recognition models for each input type, addressing the reality that many submitted applications contain a mix of digital and manual content
- Partial extraction with human assist: Rather than treating extraction as all-or-nothing, the agent extracts what it can confidently identify and presents uncertain fields to a human reviewer with the relevant PDF section highlighted, minimizing total human effort per application
- FileSet workflow orchestration: Integration with automated FileSet pipelines means extracted data triggers downstream processes immediately upon validation, collapsing the delay between extraction and action from hours or days to seconds
- Volume-independent processing speed: The agent maintains consistent per-document processing time regardless of queue depth, ensuring that peak intake periods do not create proportional processing delays
Who This Agent Is For
This agent is designed for organizations that receive structured information via PDF forms and need that information available in digital systems faster than manual data entry can deliver.
- Nonprofit organizations processing program applications where intake speed directly impacts service delivery timelines for vulnerable populations
- Government agencies handling permit applications, benefit enrollment forms, and licensing paperwork submitted as PDF documents
- Educational institutions managing admissions applications, financial aid forms, and enrollment paperwork across seasonal volume surges
- Healthcare organizations processing patient intake forms, referral documentation, and prior authorization requests submitted as PDFs
- Any operations team where PDF-based form processing consumes staff time that would be better spent on the work those forms are supposed to enable
Ideal for: Intake coordinators, operations managers, program administrators, and department heads at organizations where PDF-based applications create a measurable bottleneck between submission and action.

Clinical Notes Summarization AI Agent
NLP-driven summarization agent that ingests clinical notes from physicians, nurse practitioners, and medical assistants, applies domain-specific language models to condense patient assessments into structured summaries, and reduces administrative overhead so clinicians can focus on patient care.
A natural language processing pipeline that transforms verbose clinical documentation into structured, actionable patient summaries at the point of care
Clinical note summarization represents a well-defined NLP problem with outsized operational impact. Physicians, nurse practitioners, and medical assistants produce narrative clinical documentation during every patient encounter. These notes capture assessment findings, diagnostic reasoning, treatment plans, medication changes, and follow-up instructions in unstructured text that varies dramatically in length, format, and terminology across providers. A primary care network serving Medicare Advantage members and operating under a value-based care model recognized that the time clinicians spent reviewing and cross-referencing these notes was directly competing with time available for patient interaction. The documentation existed to support care continuity, but the documentation burden was undermining the care it was supposed to enable.
The Clinical Notes Summarization AI Agent implements a domain-specific text summarization pipeline that ingests raw clinical notes, identifies salient medical entities and assessment conclusions, and produces concise structured summaries that preserve clinical accuracy while dramatically reducing the cognitive load on reviewing providers.
Benefits
This agent addresses the structural inefficiency of requiring clinicians to process verbose narrative text when time-constrained clinical decisions demand concise, structured information.
- Reduced documentation review time: Clinicians reviewing patient histories before encounters spend significantly less time parsing lengthy narrative notes, with AI-generated summaries delivering the critical clinical facts in a fraction of the original text volume
- Preserved clinical nuance: The summarization model is trained on domain-specific medical terminology and assessment patterns, ensuring that abbreviated output retains the diagnostic context and reasoning that generic summarization tools would discard
- Standardized summary structure: Regardless of how individual providers write their notes, the agent produces summaries in a consistent format that downstream consumers can scan predictably, reducing the variability that slows cross-provider care coordination
- Scalable across provider types: The pipeline processes notes from physicians, NPs, and MAs with equal effectiveness, normalizing the significant style and detail-level differences that exist across clinical roles
- Direct patient care impact: Every minute saved on administrative documentation review is a minute that can be redirected to patient interaction, assessment, and care delivery, the activities that value-based care models are designed to optimize
- Audit-compatible output: Generated summaries maintain links to source note sections, allowing reviewers to trace any summarized conclusion back to the original clinical documentation for verification or regulatory compliance
Problem Addressed
The core technical challenge is information density reduction without clinical accuracy loss. A single patient encounter may generate between 500 and 3,000 words of clinical narrative. A provider reviewing that patient's history before their next appointment may need to process notes from multiple prior encounters across multiple providers. The cumulative text volume is substantial, and the relevant information is distributed unpredictably throughout the narrative. Assessment conclusions may appear mid-paragraph. Medication changes may be mentioned in passing. Follow-up instructions may reference earlier sections implicitly rather than restating the relevant context.
Generic text summarization models fail in this domain because they optimize for statistical salience rather than clinical relevance. A sentence that appears structurally unimportant to a general-purpose model may contain the single most critical piece of diagnostic information in the entire note. Medical abbreviations, assessment scoring conventions, and problem-oriented documentation patterns require domain-specific language understanding that cannot be approximated by general extractive or abstractive summarization approaches. The result without a specialized solution is that clinicians must read full notes regardless of length, because they cannot trust that a generic summary captured what matters.
What the Agent Does
The agent implements a multi-stage NLP pipeline optimized for clinical text comprehension and condensation:
- Clinical note ingestion: Raw notes from physicians, nurse practitioners, and medical assistants are ingested from the electronic health record system, with metadata tagging for provider type, encounter type, and documentation timestamp
- Medical entity recognition: The pipeline identifies and extracts clinical entities including diagnoses, medications, procedures, vital signs, lab results, and assessment scores using a domain-trained NER model tuned for medical terminology and abbreviation patterns
- Assessment-outcome linking: Extracted entities are mapped to assessment conclusions and treatment decisions within the note, preserving the diagnostic reasoning chain that connects observed findings to clinical actions
- Abstractive summary generation: A domain-specific language model generates concise narrative summaries that synthesize the extracted entities and their clinical relationships into readable text that a reviewing provider can scan in seconds
- Structured output formatting: Generated summaries are formatted into consistent sections covering chief complaint, key findings, active problems, medication changes, and follow-up plan, regardless of the original note's organizational structure
- Source provenance mapping: Each section of the generated summary maintains a reference link to the specific passage in the original note from which the information was derived, supporting verification and audit workflows
Standout Features
- Domain-specific language model: The summarization engine is trained on clinical documentation patterns, medical terminology, and assessment conventions rather than general-purpose text, producing output that reflects how clinicians actually think about and communicate patient information
- Multi-provider normalization: Notes from physicians, NPs, and MAs follow different documentation conventions and detail levels. The agent normalizes across these variations to produce summaries with consistent depth and structure regardless of the authoring provider type
- Configurable summary depth: Summary verbosity can be configured per use case, from brief headline summaries for triage review to detailed clinical abstracts for complex care coordination, with the same underlying extraction pipeline serving both
- Medication change highlighting: Changes to medication regimens are automatically flagged and surfaced in a dedicated summary section, addressing one of the highest-risk information transfer points in clinical documentation review
- Longitudinal patient timeline: When multiple notes exist for the same patient, the agent can generate a longitudinal summary that tracks assessment progression, treatment responses, and care plan evolution across encounters rather than summarizing each note in isolation
Who This Agent Is For
This agent is engineered for healthcare organizations where clinical documentation volume creates a measurable drag on provider productivity and care delivery throughput.
- Primary care networks operating under value-based care models where documentation efficiency directly impacts care delivery capacity and reimbursement metrics
- Clinical informatics teams responsible for optimizing EHR workflows and reducing provider documentation burden across multi-site health systems
- Care coordination staff who review patient histories from multiple providers and need structured summaries that normalize documentation style differences
- Quality assurance teams monitoring clinical documentation completeness and consistency across provider types and practice locations
- Health system administrators evaluating the operational impact of documentation burden on provider satisfaction, patient throughput, and care quality metrics
Ideal for: Chief medical information officers, clinical informatics directors, care coordination managers, and health system operations leaders managing documentation workflows across multi-provider, multi-site healthcare organizations.

Vendor Document Verification AI Agent
AI-powered vendor onboarding agent that automatically extracts key data from uploaded W-9 forms, validates vendor information using fuzzy matching against internal records, verifies EIN accuracy and signatures, and routes exceptions for human approval with full audit traceability.
You know that sinking feeling when a new vendor submission lands in your inbox and you realize you're about to spend the next hour cross-referencing tax IDs by hand.
Every organization that works with outside vendors eventually hits the same wall. The W-9 forms pile up. Each one needs to be opened, read, validated against internal records, and either approved or flagged. The people doing this work are skilled professionals whose time would be better spent on strategic vendor relationships, not squinting at scanned PDFs trying to confirm whether a tax identification number matches what's already in the system. And the stakes are real: a missed discrepancy in vendor data can cascade into compliance issues, duplicate payments, or onboarding delays that frustrate everyone involved.
A national restaurant brand with locations across multiple states faced exactly this challenge. Their procurement team processed hundreds of vendor onboarding packets each quarter, and every single one required manual auditing. The Vendor Document Verification AI Agent was built to take that burden off their team's shoulders and put it where it belongs: in the hands of automation that never gets tired, never skips a field, and never forgets to log what it found.
Benefits
This agent transforms vendor onboarding from a manual audit bottleneck into a streamlined, governed process that runs itself.
- Hours reclaimed every week: Staff who previously spent full days reviewing W-9 submissions can redirect that time toward vendor relationship management, contract negotiations, and strategic sourcing work that actually moves the business forward
- Consistent validation every time: The agent applies the same extraction and verification logic to every document without variation, eliminating the human inconsistency that allows errors to slip through during high-volume processing periods
- Audit-ready from day one: Every decision the agent makes is logged with timestamps, confidence scores, and the specific data points that triggered approval or exception routing, creating a compliance trail that satisfies auditors without additional documentation effort
- Faster vendor activation: Vendors that pass automated validation are cleared for onboarding immediately rather than waiting in a queue for manual review, reducing time-to-activation from days to minutes for clean submissions
- Exception handling that works for humans: When the agent encounters ambiguous data or low-confidence matches, it routes the submission to the right person with all relevant context already assembled, so the reviewer can make a quick decision instead of starting the verification process from scratch
- Reduced duplicate vendor risk: Fuzzy matching against existing records catches near-duplicate entries that manual reviewers commonly miss, preventing the payment and compliance issues that arise when the same vendor exists under slightly different names in the system
Problem Addressed
Here is what vendor onboarding looks like without this agent. A new W-9 arrives as a PDF attachment. Someone on the team opens it, manually reads the vendor name, address, tax classification, and EIN. They check whether the EIN looks valid. They search the existing vendor database to see if this entity already exists under a similar name. They verify the form is signed. They enter the data into a spreadsheet or ERP system. Then they move on to the next one. If the volume is fifty forms a week, that is fifty repetitions of a process that is tedious, error-prone, and entirely predictable.
The risk is not just wasted time. Manual verification introduces human error at every step. An EIN transposition goes unnoticed. A vendor that already exists under a slightly different legal name gets created as a duplicate. A missing signature is overlooked because the reviewer was processing their thirtieth form of the day. These errors do not surface immediately. They surface weeks later as duplicate payments, compliance findings, or vendor disputes that take significantly more time to resolve than the original verification would have taken to do correctly. The problem is structural: asking humans to perform high-volume, rule-based validation work produces exactly the kind of inconsistency that creates downstream risk.
What the Agent Does
The agent runs an end-to-end verification pipeline that takes vendor documents from upload to decision without manual intervention on clean submissions:
- Document ingestion and OCR extraction: Uploaded W-9 forms are automatically scanned using AI-powered document extraction to pull vendor name, address, tax classification, EIN, and signature fields from the unstructured PDF layout regardless of formatting variations
- EIN format validation: Extracted employer identification numbers are verified against standard format rules to catch transposition errors, invalid check digits, and formatting inconsistencies before the record enters the vendor database
- Fuzzy matching against existing records: The agent compares extracted vendor data against the internal vendor database using similarity algorithms that catch near-matches, alternate legal names, and address variations that exact-match searches would miss
- Signature presence verification: AI-based document analysis confirms whether the required signature field has been completed, flagging unsigned submissions for follow-up before they enter the approval workflow
- Confidence-scored routing: Each verification check produces a confidence score, and the agent routes high-confidence submissions directly to approval while sending lower-confidence results to designated reviewers with full context on which checks triggered the exception
- Audit trail logging: Every extraction, validation, match attempt, and routing decision is logged with timestamps and supporting data, creating a complete compliance record for each vendor submission processed by the agent
Standout Features
- Format-agnostic document handling: The agent processes W-9 forms regardless of whether they are typed, handwritten, scanned at varying resolutions, or submitted as different PDF versions, applying adaptive extraction logic that handles real-world document quality
- Intelligent duplicate detection: Beyond simple name matching, the fuzzy matching engine cross-references multiple fields simultaneously, catching scenarios where a vendor submits under a DBA name, a parent company name, or a slightly misspelled variation of an existing entity
- Configurable approval thresholds: Administrators can adjust the confidence thresholds that determine which submissions auto-approve and which route to manual review, allowing the system to be tuned for risk tolerance as the team builds trust in the automation
- Exception context packaging: When a submission is routed for human review, the reviewer sees the extracted data alongside the specific verification checks that failed, the closest existing vendor matches, and a direct link to the source document, reducing review time from minutes to seconds
- Scalable batch processing: The agent handles single submissions and bulk upload batches with equal reliability, processing quarterly vendor onboarding surges without queuing delays or degraded verification quality
Who This Agent Is For
This agent is built for teams that process vendor onboarding paperwork at a volume where manual verification creates bottlenecks, errors, and compliance exposure.
- Procurement teams managing hundreds of vendor submissions per quarter across multi-location operations
- Finance departments responsible for maintaining clean, deduplicated vendor master data in ERP systems
- Compliance officers who need auditable verification trails for every vendor added to the approved supplier list
- Operations managers in restaurant, retail, and hospitality organizations where vendor volume scales with location count
- Accounts payable teams dealing with duplicate vendor entries that cause payment errors and reconciliation headaches
Ideal for: Procurement managers, AP supervisors, compliance leads, and operations directors at multi-location organizations where vendor onboarding volume has outgrown manual review capacity.

Executive Email Insights AI Agent
AI agent that scans dashboards to identify the most impactful metrics and notable changes, then compiles them into polished executive emails with relevant card visuals included.
Benefits
If you have ever built a dashboard that an executive glances at once a week, this agent solves the adoption problem by bringing the most important insights directly to their inbox in a format that respects their time and attention.
- Signal without noise: Executives receive only the metrics that actually changed or matter, rather than a link to a dashboard with 50 cards where they have to figure out what is important. The agent does the filtering and prioritization so they do not have to
- Visual context included: The email contains actual card visuals, not just numbers. An executive sees a trend line showing the dip, a bar chart showing the comparison, or a gauge showing where performance stands, without needing to click through to a dashboard
- Automated and consistent: The agent generates and sends briefings on a configurable schedule without requiring an analyst to manually compile the email each time. Monday morning briefings arrive reliably whether the analyst is on vacation or not
- Time savings for both sides: Analysts stop spending hours assembling executive update emails by hand, and executives stop missing insights because they did not have time to log into the dashboard. Both sides get what they need with less effort
- Narrative structure: The email is not just a grid of metrics. The agent constructs a narrative around the most significant changes, providing context for why a metric moved and what it means for the business, making the briefing immediately actionable
- Adaptable to any audience: While designed for executive consumers, the same mechanism can generate tailored briefings for any audience: operations leads getting daily operational metrics, sales managers getting weekly pipeline summaries, or board members getting monthly strategic overviews
Problem Addressed
There is a consistent gap between the analytics that organizations build and the analytics that executives actually consume. Dashboards contain comprehensive data, but executives have limited time and attention. They may check a dashboard briefly during a morning routine, but they are unlikely to methodically review every card, compare metrics against previous periods, and synthesize the important changes into a coherent picture. The data is available; the consumption model is wrong for the audience.
Many organizations attempt to bridge this gap with manual executive briefings: an analyst reviews the dashboards, identifies noteworthy changes, takes screenshots of relevant cards, writes context around the numbers, and emails the result to leadership. This works, but it does not scale. It consumes analyst time that could be spent on deeper analysis, it is inconsistent depending on who writes it and when, and it breaks down when the analyst is busy, out of office, or managing multiple briefing cadences for different stakeholders. The need is for a system that can do what a good analyst does when compiling an executive briefing, but do it automatically, consistently, and at any cadence.
What the Agent Does
The agent monitors dashboards, identifies what matters, and delivers curated briefings to executive inboxes:
- Dashboard scanning: The agent connects to configured dashboards and evaluates every card, pulling current values, historical comparisons, and trend data for each metric being tracked
- Impact scoring: Each metric is scored based on configurable criteria including magnitude of change from previous period, deviation from targets or benchmarks, trend direction and acceleration, and organizational priority weighting
- Card visual selection: For the highest-impact metrics, the agent captures visual representations of the relevant cards, including charts, trends, and gauges, selecting the visual format that best communicates the story behind the number
- Narrative generation: The agent constructs a written narrative around the selected metrics, explaining what changed, by how much, and providing context that helps the reader understand significance without needing to investigate further
- Email composition: Selected visuals and narrative text are composed into a polished, branded email template that presents information in a scannable hierarchy, from highest impact at the top to supporting details below
- Scheduled delivery: Briefings are generated and delivered on a configurable schedule, whether daily, weekly, or triggered by specific metric threshold crossings, ensuring executives receive timely intelligence without manual intervention
Standout Features
- Intelligent card selection: The agent does not include every card from the dashboard. It makes editorial decisions about which visuals provide the most information value, avoiding the common mistake of overwhelming executives with comprehensive data when they need curated insight
- Comparative context: Every highlighted metric includes comparison context, showing performance against the previous period, the same period last year, targets, or peer benchmarks, so the reader can immediately gauge whether a number is good, bad, or expected
- Anomaly highlighting: Metrics that exhibit unusual patterns, such as sudden spikes, trend reversals, or values crossing threshold boundaries, receive special callouts in the email, drawing the reader's eye to items that may require attention or decision
- Multi-stakeholder configuration: Different executives can receive different briefings from the same set of dashboards, with the agent selecting metrics and setting priority weights based on each recipient's role, responsibilities, and stated areas of interest
- Read tracking and feedback: The system tracks email open rates and can collect executive feedback on briefing relevance, enabling continuous improvement of metric selection and narrative quality over time
Who This Agent Is For
This agent is built for the intersection of two audiences: the executives who need curated intelligence delivered to them, and the analytics teams who currently spend time manually assembling those briefings.
- Executives and senior leaders who want regular data-driven updates delivered to their inbox without needing to log into dashboards or attend status meetings to stay informed
- Chiefs of staff and executive assistants who currently compile metric briefings manually and need an automated solution that frees their time for higher-judgment work
- Operations leads who manage daily or weekly operational cadences and need consistent, automated reporting that arrives on schedule without manual assembly
- Analytics teams that build dashboards but struggle with executive adoption, needing a delivery mechanism that meets executives where they already spend their time: in email
- Board reporting coordinators who need reliable, well-formatted metric briefings on a monthly cadence without depending on an individual analyst's availability
Ideal for: Any organization where executive dashboard adoption is lower than desired, where analysts spend significant time manually compiling metric briefings, or where leadership needs consistent data-driven intelligence delivered proactively.

Instance Governance AI Agent
AI agent that intelligently renames and reorganizes analytics instance content to follow a predefined taxonomy, automating weeks of manual cleanup into an immediate, governed result.
Benefits
Organizations that have accumulated years of organically grown analytics content can achieve in hours what would otherwise take weeks of manual effort: a fully organized, consistently named, taxonomy-compliant environment that every user can navigate intuitively.
- Weeks of cleanup compressed to hours: The agent processes the entire content inventory simultaneously, applying taxonomy rules and naming conventions across hundreds or thousands of assets in a single automated pass rather than requiring manual item-by-item review
- Consistent naming across every team: Every card, page, dataset, and dataflow follows the same naming convention after the agent processes it, eliminating the confusion caused by different teams using different naming styles for similar content
- Immediately navigable environment: After taxonomy enforcement, users can find content through logical hierarchy rather than relying on search or institutional knowledge of where things were placed by their original creators
- Analytics-ready metadata: Consistently categorized content enables governance reporting on usage patterns, content distribution, and adoption metrics that are impossible when content naming and organization are inconsistent
- Reduced duplication: The taxonomy enforcement process identifies functionally duplicate content that exists under different names or in different locations, enabling consolidation that reduces confusion and maintenance burden
- Sustainable governance posture: Once the initial cleanup is complete, the agent can run periodically to catch new content that does not conform to taxonomy standards, maintaining organizational discipline without ongoing manual enforcement effort
Problem Addressed
Analytics environments that have grown organically over months or years inevitably develop organizational debt. Content creators name cards, pages, and datasets according to their own preferences. Content is placed wherever it is convenient at the time of creation rather than according to a deliberate organizational structure. Over time, the environment becomes a maze of inconsistently named assets with no clear hierarchy, making content discovery unreliable and governance nearly impossible.
The challenge is not that organizations lack taxonomy standards. Most have defined naming conventions and organizational structures. The problem is enforcement: manually auditing and renaming hundreds or thousands of existing assets is so labor-intensive that it never reaches the top of anyone's priority list. The governance team knows the environment needs cleanup, but the effort required is measured in weeks of full-time work, which is difficult to justify against competing priorities. Meanwhile, the organizational debt compounds as new content continues to be created without consistent standards.
What the Agent Does
The agent performs a comprehensive content audit and taxonomy enforcement across the analytics environment:
- Content inventory scan: The agent catalogs every asset in the environment including cards, pages, datasets, dataflows, and other content types, capturing current names, locations, types, owners, and usage metrics
- Taxonomy mapping: Each asset is analyzed against the organization's predefined taxonomy using AI classification. The agent determines which taxonomy category each asset belongs to based on its content, data sources, and functional purpose rather than relying solely on its current name
- Name standardization: Assets are renamed according to the taxonomy's naming convention rules. The agent generates proposed names that follow the standard format while preserving enough of the original name to maintain recognizability for existing users
- Hierarchical reorganization: Content is reorganized into the taxonomy's page and folder structure, moving assets from their current ad-hoc locations into their proper category within the organizational hierarchy
- Duplication identification: The agent identifies assets that appear to serve the same purpose based on their data sources, transformation logic, or visual content, flagging potential duplicates for review and consolidation
- Change preview and approval: Before applying changes, the agent generates a complete change manifest showing every proposed rename, move, and categorization, allowing governance teams to review and approve the plan before execution
Standout Features
- AI-powered classification: The agent does not rely on keyword matching to categorize content. It analyzes the actual content, data sources, and usage patterns to determine the correct taxonomy category, correctly classifying even poorly named assets that a keyword-based approach would miss
- Non-destructive execution: All changes are reversible. The agent maintains a complete log of original names and locations, enabling rollback of any individual change or the entire enforcement pass if needed
- Owner notification: Content owners are automatically notified when their assets are renamed or reorganized, including the old name, new name, and the taxonomy rule that drove the change, ensuring transparency and reducing confusion
- Incremental enforcement mode: After the initial cleanup, the agent can run in incremental mode, processing only newly created or modified content and enforcing taxonomy compliance on an ongoing basis without re-processing the entire environment
- Custom taxonomy support: The agent works with any taxonomy structure the organization defines, from simple two-level hierarchies to complex multi-dimensional classification systems with cross-cutting categories
Who This Agent Is For
This agent delivers the highest value to organizations that have recognized their analytics environment needs organizational cleanup but have been unable to justify the manual effort required to achieve it.
- BI administrators responsible for maintaining an organized, navigable analytics environment across departments and user groups
- Governance teams that have defined taxonomy standards but lack the bandwidth to enforce them retroactively across existing content
- Data stewards managing content lifecycle and needing consistent categorization to support usage tracking, archival policies, and compliance reporting
- IT leaders preparing for platform migrations or consolidations who need the source environment organized and deduplicated before migration begins
- Any organization that has answered yes to the question: is our analytics environment harder to navigate than it should be?
Ideal for: Large enterprises with mature analytics deployments, organizations post-merger needing to consolidate analytics environments, and any organization where organic content growth has outpaced organizational governance capacity.

Receipt Validation AI Agent
AI agent that uses optical character recognition to automatically capture and validate receipt amounts from PDFs, ensuring accuracy in expense data without manual review.
Benefits
Finance teams processing hundreds or thousands of expense receipts per month face a bottleneck that this agent eliminates: the manual review cycle where someone must open each receipt, verify the amount, cross-reference it against the expense report, and flag discrepancies.
- Eliminated verification bottleneck: The agent processes receipts as fast as they are submitted, removing the queue that forms when a small team must manually verify a large volume of expense documentation. Processing time drops from days to minutes
- Consistent accuracy at scale: OCR-based extraction applies the same precision to every receipt regardless of volume, time of day, or reviewer fatigue. The agent does not skip fields, misread amounts, or lose focus after processing hundreds of receipts
- Exception-based human review: Instead of reviewing every receipt, finance teams only need to examine the exceptions the agent flags, such as amounts that do not match expense records, receipts with low OCR confidence, or documents that fail validation rules. This shifts human effort from routine verification to judgment-based exceptions
- Real-time expense data integrity: Validated receipt data flows directly into financial systems, ensuring that expense reports reflect verified amounts rather than self-reported figures that may contain errors or discrepancies
- Audit-ready documentation: Every receipt processing event is logged with the OCR extraction result, the validation decision, and any exception details, creating a complete audit trail that satisfies compliance requirements without additional record-keeping effort
- Reduced processing cost per receipt: By automating the labor-intensive verification step, the cost of processing each expense receipt drops significantly, making thorough validation economically feasible even for high-volume expense programs
Problem Addressed
Expense management workflows generate a persistent operational headache for finance teams: receipt verification. Every expense report submitted by an employee includes receipt documentation, typically in PDF or image format, that must be matched against the claimed expense amounts. In organizations processing hundreds or thousands of expense reports per month, this verification step becomes a significant bottleneck. Finance staff must open each receipt, locate the total amount, compare it to the expense line item, and flag any discrepancies for follow-up.
The manual nature of this process creates several problems simultaneously. First, it is slow: receipts pile up during peak travel periods or month-end closing, delaying reimbursements and financial reporting. Second, it is error-prone: reviewers working through large volumes inevitably miss discrepancies or misread amounts, especially on low-quality scans or receipts in unfamiliar formats. Third, it is expensive: dedicated staff time for receipt verification is a significant cost that scales linearly with expense volume. And fourth, it creates compliance risk: when the verification backlog grows, teams are tempted to spot-check rather than verify every receipt, which undermines the control that verification is supposed to provide.
What the Agent Does
The agent implements an end-to-end receipt validation pipeline from document ingestion through exception handling:
- Receipt ingestion: PDF and image receipts are collected from the expense management system, email submissions, or file upload channels. The agent handles multiple file formats and automatically rotates or enhances images where needed to improve OCR accuracy
- OCR amount extraction: Optical character recognition identifies and extracts the total amount from each receipt, handling diverse receipt formats including retail receipts, restaurant checks, hotel folios, airline itineraries, and professional service invoices
- Multi-field extraction: Beyond the total amount, the agent extracts vendor name, date, tax amounts, currency, and payment method where available, building a structured record from each unstructured receipt document
- Cross-reference validation: Extracted receipt data is compared against the corresponding expense report line items, checking for amount matches, date consistency, vendor alignment, and currency correctness
- Exception flagging: Receipts that fail any validation check are flagged with specific exception codes indicating the type of discrepancy, such as amount mismatch, missing receipt fields, duplicate submission, or low OCR confidence scores
- Dashboard reporting: Processing results feed into dashboards showing validation statistics, exception rates, processing volumes, and average time-to-validation, giving finance leadership visibility into the health of the expense verification process
Standout Features
- Format-adaptive OCR: The agent recognizes and adapts to different receipt formats automatically, handling the extreme variety of receipt layouts encountered in corporate expense programs without requiring format-specific configuration for each vendor or receipt type
- Confidence-tiered routing: Receipts are processed through a confidence scoring system where high-confidence extractions are auto-validated, medium-confidence extractions receive enhanced processing, and low-confidence extractions are routed directly to human review with the OCR results pre-populated for efficiency
- Duplicate detection: The agent identifies potential duplicate receipt submissions by comparing amounts, dates, and vendor names across submissions, catching a common source of expense fraud that manual review frequently misses
- Policy rule enforcement: Configurable business rules can be applied during validation, such as flagging receipts over a threshold amount, identifying receipts from restricted vendor categories, or detecting submissions that exceed per diem rates for the travel location
- Currency and tax handling: The agent correctly handles multi-currency receipts, foreign tax structures, and tip/gratuity fields that often cause errors in manual processing, applying appropriate conversion rates and tax categorization rules
Who This Agent Is For
This agent is purpose-built for finance operations teams where expense receipt verification is a recurring, high-volume workload that consumes staff time disproportionate to its value.
- Finance teams processing 500+ expense receipts per month who need to reduce verification cycle time without sacrificing accuracy
- Expense administrators responsible for ensuring policy compliance across employee expense submissions and needing systematic rather than spot-check verification
- Internal audit teams requiring documented proof that expense receipts were verified against claimed amounts for compliance and audit trail purposes
- Shared services centers processing expense reports for multiple business units and needing scalable verification that does not require proportional staff increases
- CFOs and controllers seeking to reduce the cost of expense processing while improving the accuracy and completeness of financial controls
Ideal for: Organizations with significant travel and expense budgets, companies with large field sales teams, professional services firms, and any organization where expense receipt volume creates a verification bottleneck in the finance department.

ETL Documentation AI Agent
AI agent that automatically generates business-friendly documentation for complex data pipelines, with a V2 RAG chat interface for interactive Q&A on pipeline logic and configuration.
Benefits
The agent addresses a persistent gap in data infrastructure: documentation that is accurate, current, and comprehensible to both technical and non-technical stakeholders. It generates documentation automatically from pipeline metadata rather than relying on humans to write and maintain it.
- Always-current documentation: Because documentation is generated from the pipeline's actual configuration rather than written separately, it stays in sync with the pipeline automatically. When transforms change, the documentation updates accordingly without manual intervention
- Business-readable output: The agent translates technical pipeline logic into plain-language descriptions that business users can understand. A join operation becomes a step that combines customer records with their purchase history, making pipelines accessible to stakeholders who need to understand data lineage without reading SQL
- Dramatic reduction in onboarding time: New team members can understand existing pipelines in minutes rather than days. Instead of reverse-engineering transform logic by reading configuration files, they read clear documentation that explains what each pipeline does, why it exists, and how its components relate
- Reduced support burden: When business users can read pipeline documentation themselves, the number of how does this data get calculated questions directed at the data team drops significantly, freeing engineers for higher-value work
- Audit and compliance readiness: Generated documentation creates a detailed record of data transformation logic that satisfies audit requirements for data lineage transparency without requiring separate documentation projects
- V2 interactive Q&A: The RAG chat interface in V2 allows users to ask specific questions about pipeline behavior, such as what happens to null values in this transform or which pipelines feed into this dataset, getting immediate, accurate answers from the documentation corpus
Problem Addressed
Data pipelines are among the most critical and least documented components of modern data infrastructure. As organizations build hundreds of ETL workflows to transform, combine, and route data across systems, the logic embedded in those pipelines becomes organizational knowledge that typically lives only in the heads of the engineers who built them. Documentation, when it exists at all, is written manually and falls out of date the moment the pipeline changes. The result is a growing documentation debt that compounds over time: each undocumented or poorly documented pipeline adds to the burden on the original builder to explain, troubleshoot, and modify it, since no one else can understand what it does.
This documentation deficit has concrete operational costs. Onboarding new data engineers takes longer because they must reverse-engineer pipeline logic. Troubleshooting production issues takes longer because the engineer responding does not understand the pipeline's intent. Business users cannot trace data quality issues because the transformation logic is opaque. And pipeline modifications carry higher risk because the engineer making changes cannot fully verify the downstream impact without understanding every step in the chain. The fundamental problem is not that documentation is hard to write; it is that maintaining manual documentation at the pace of pipeline evolution is structurally unsustainable.
What the Agent Does
The agent reads pipeline configurations, analyzes transformation logic, and produces structured documentation at multiple levels of detail:
- Pipeline metadata extraction: The agent connects to the pipeline management layer and extracts the complete configuration of each dataflow, including input datasets, output datasets, transformation steps, join conditions, filter logic, aggregation rules, and scheduling configuration
- Transform logic interpretation: Each transformation step is analyzed and translated into a business-language description that explains what the step does, what data it operates on, and what the output represents. Complex multi-step transformations are explained both individually and as a coherent sequence
- Documentation structure generation: The agent produces structured documentation including a pipeline overview (purpose and scope), input/output inventory, step-by-step transform descriptions, data lineage diagrams, scheduling and dependency information, and known assumptions or limitations
- Cross-pipeline relationship mapping: The agent identifies dependencies between pipelines, documenting which pipelines feed into others and which datasets serve as shared intermediates, creating a navigable map of the entire data transformation ecosystem
- RAG index construction (V2): All generated documentation is indexed in a retrieval-augmented generation system that enables natural-language querying. Users can ask specific questions about any pipeline and receive answers grounded in the actual documentation
- Interactive chat interface (V2): The V2 chat interface allows users to have exploratory conversations about pipeline logic, asking follow-up questions, requesting comparisons between pipelines, or investigating specific transformation behaviors
Standout Features
- Multi-audience documentation: The agent generates documentation at multiple technical levels simultaneously. The same pipeline produces both a technical reference (with exact transform specifications) and a business summary (with plain-language explanations), served to different audiences through the same interface
- Automatic change detection: When pipeline configurations change, the agent detects the modifications and regenerates affected documentation sections, including a change summary that describes what was modified and how the pipeline behavior differs from the previous version
- Dependency impact analysis: Users can query the system to understand the impact of a potential change, asking questions like what would be affected if I changed this input field and receiving documentation-grounded answers about downstream dependencies
- Quality scoring: The agent assigns documentation quality scores to each pipeline based on completeness, description clarity, and the presence of undocumented assumptions, helping data teams prioritize which pipelines need human review of their auto-generated documentation
- Export and integration: Generated documentation can be exported in standard formats for inclusion in data catalogs, wiki systems, or compliance documentation packages, ensuring the auto-generated content integrates with existing documentation workflows
Who This Agent Is For
This agent is built for data teams that have outgrown their ability to manually document pipelines and need an automated solution that scales with their infrastructure.
- Data engineers who build and maintain ETL pipelines and need documentation that stays current without requiring manual updates every time a transform changes
- Business users and analysts who need to understand where their data comes from and how it is transformed without reading technical configuration files
- Support teams responsible for troubleshooting data quality issues who need rapid access to pipeline logic documentation to diagnose problems
- Data governance professionals ensuring data lineage transparency for audit and compliance purposes who need comprehensive, accurate pipeline documentation
- New team members onboarding onto a complex data infrastructure who need to understand existing pipelines quickly without relying entirely on tribal knowledge
Ideal for: Organizations with 50+ active data pipelines, data teams experiencing documentation debt, and any environment where pipeline complexity has outpaced manual documentation capacity.

Content Discovery AI Agent
AI agent that enables users to discover cards, pages, and data within their analytics environment using natural language questions, responding with relevant visual snapshots governed by user-level permissions.
Benefits
If you have ever heard a colleague say they know the data exists somewhere but cannot find it, this agent exists to solve that exact problem. It turns natural language questions into direct paths to the right cards, pages, and datasets.
- Find content without knowing where it lives: Users describe what they are looking for in their own words, and the agent locates the relevant cards, pages, and datasets across the entire environment. No more navigating folder hierarchies or remembering which page a specific chart was placed on
- Visual context in every response: The agent does not just return a list of links. It provides visual snapshots of matching cards and pages so users can verify they have found the right content before navigating to it, saving the back-and-forth of clicking through results
- Follow-up exploration: After finding initial results, users can ask follow-up questions to refine their search, explore related content, or drill deeper into a specific area. The conversational interface maintains context across the entire interaction
- Security-first architecture: Every result is filtered through the user's permission level, including data policy restrictions. Users only see content they are authorized to access, making the agent safe to deploy broadly without risk of exposing restricted data
- Reduced onboarding friction: New team members can explore the analytics environment through natural conversation rather than needing someone to walk them through the folder structure. The agent serves as a knowledgeable guide that knows where everything lives
- Increased content utilization: Cards, dashboards, and datasets that were previously undiscoverable because they were buried deep in folder hierarchies become accessible to the broader organization, increasing the return on analytics investment
Problem Addressed
As analytics environments grow to include hundreds or thousands of cards, pages, and datasets, content discoverability becomes a serious operational challenge. Users know that dashboards and reports exist for their questions, but finding the right content requires either institutional knowledge of where things are organized or time-consuming manual browsing through nested page hierarchies. The search tools available in most analytics platforms rely on exact keyword matching against titles and descriptions, which fails when users do not know the precise terminology used to name the content they need.
The practical consequence is significant underutilization of analytics investment. Organizations build sophisticated dashboards and reports, but adoption plateaus because users outside the core analytics team cannot find what they need. Help desk tickets asking where do I find X data become a constant drain on data team bandwidth. New hires take weeks to learn the content landscape. And duplicate content proliferates because it is often easier to build a new report than to locate an existing one that already answers the question.
What the Agent Does
The agent provides a conversational interface for exploring analytics content, handling the full discovery workflow from initial query through detailed exploration:
- Natural language query processing: The agent interprets user questions expressed in business language rather than requiring technical search syntax. A question like what do our customer retention numbers look like is understood and matched against relevant content even if no card is titled customer retention
- Content matching and ranking: The agent searches across cards, pages, and datasets, ranking results by relevance to the query using semantic understanding rather than simple keyword matching. This includes matching against card titles, descriptions, underlying data sources, and the business context of visualizations
- Visual snapshot generation: For matching cards and pages, the agent generates visual previews that show the actual content, allowing users to visually confirm they have found the right asset before navigating to the full view
- Permission-aware filtering: All search results are filtered through the querying user's data policies and access permissions. Content that the user is not authorized to view is excluded from results entirely, maintaining data governance without requiring any special configuration
- Conversational follow-up: Users can refine their search through follow-up questions, ask for related content, request different time periods or segments, or explore adjacent topics. The agent maintains full conversation context to understand references to previously discussed content
- Navigation assistance: Beyond finding content, the agent provides direct links to the discovered cards and pages, enabling one-click navigation from the search result to the full interactive content
Standout Features
- Semantic search beyond keywords: The agent understands business intent, not just keywords. Searching for how are we doing on renewals will find a card titled subscription renewal rate even though the search terms do not match the title, because the agent understands the semantic relationship
- Cross-content-type discovery: A single query can return cards, pages, and datasets in the same result set, ranked by relevance regardless of content type. Users do not need to search cards and pages separately
- Permission model integration: The agent respects the full permission model including row-level data policies, page-level access controls, and dataset-level sharing rules, making it safe to deploy to every user in the organization without governance risk
- Context-aware suggestions: When initial results do not fully answer the user's question, the agent proactively suggests related content areas or alternative queries that might better match what they are looking for
- Usage-weighted results: The agent factors in content popularity and recency, surfacing actively maintained and frequently accessed content higher in results than abandoned or outdated assets
Who This Agent Is For
This agent is designed for any organization where the analytics environment has grown large enough that finding the right content has become a barrier to adoption and utilization.
- Business users who need answers from data but do not know which dashboard or card contains the information they need and lack the time to browse through page hierarchies
- Analysts who maintain large content libraries and frequently receive where do I find this questions from stakeholders, wanting to deflect routine discovery requests to a self-service tool
- Executives who want quick access to key metrics and reports without memorizing navigation paths or bookmarking dozens of individual pages
- New employees going through onboarding who need to familiarize themselves with the analytics environment quickly without requiring extensive one-on-one guidance
- Data governance teams who want to ensure that content discovery respects permission boundaries while still making authorized content maximally accessible
Ideal for: Any organization with more than 100 cards and pages in their analytics environment, particularly those with diverse user populations spanning multiple departments, roles, and technical skill levels.

Competitor News Analysis AI Agent
AI agent that ingests external news and documents, analyzes and categorizes competitive content, and provides a RAG-powered interface for exploring trends and asking questions about competitive intelligence.
Benefits
Strategy teams gain a continuously updated competitive intelligence system that replaces manual news monitoring with automated analysis, delivering categorized insights and trend visibility that would take weeks to assemble by hand.
- Automated competitive monitoring: External news sources, press releases, industry publications, and document feeds are ingested automatically, ensuring the intelligence pipeline runs continuously without requiring analysts to manually search for and collect content
- AI-driven categorization and tagging: Every ingested article or document is analyzed and categorized by competitor, topic, sentiment, and strategic relevance, creating an organized intelligence archive that is immediately navigable rather than a raw dump of articles
- Trend visibility across time: The agent tracks competitive activity patterns over weeks and months, surfacing trends such as increased hiring in a specific function, repeated product messaging shifts, or geographic expansion signals that only become visible when data is aggregated systematically
- Natural-language exploration: Rather than clicking through folders or running keyword searches, users interact with the intelligence archive through a conversational interface, asking questions like what competitors have been saying about a specific capability or what market moves have occurred in a given quarter
- Reduced time-to-insight: What previously required a dedicated analyst spending hours per week compiling competitive briefings is now available on-demand. Any team member can access current competitive intelligence within minutes without specialized research skills
- Centralized competitive knowledge: All competitive intelligence lives in a single, searchable system rather than scattered across email threads, shared drives, and individual analysts' notes, ensuring organizational knowledge survives team transitions
Problem Addressed
Competitive intelligence gathering at most organizations is a manual, fragmented process. Strategy teams, product managers, and sales leaders each monitor competitors through their own informal channels: reading industry publications, setting up news alerts, attending conferences, and relying on field reports from sales interactions. The resulting intelligence is scattered across email inboxes, presentation decks, and individual memory. There is no centralized system that continuously monitors the competitive landscape, categorizes what it finds, and makes the accumulated intelligence explorable.
This fragmentation means that when a strategic question arises, such as what a specific competitor has been investing in recently or how the competitive landscape in a particular market segment has shifted, answering it requires starting from scratch. Analysts must re-gather information, re-read articles, and re-synthesize findings. Patterns that would be obvious if all competitive signals were aggregated in one place go unnoticed because the signals are distributed across dozens of sources and stakeholders. The organization has competitive awareness, but not competitive intelligence.
What the Agent Does
The agent builds and maintains a continuously updated competitive intelligence system through automated ingestion, AI analysis, and retrieval-augmented exploration:
- Multi-source content ingestion: The agent pulls content from configured external news feeds, RSS sources, industry publication APIs, and document upload channels, creating a steady inflow of competitive content without manual collection
- AI content analysis: Each ingested item passes through an AI analysis pipeline that identifies mentioned competitors, extracts key facts and claims, assesses sentiment and strategic significance, and generates structured metadata for categorization
- Automated categorization: Analyzed content is tagged along multiple dimensions including competitor name, topic category (product, pricing, partnerships, hiring, funding, regulatory), geographic relevance, and estimated strategic impact
- RAG index maintenance: All analyzed content is indexed in a retrieval-augmented generation system that enables semantic search and question answering across the entire intelligence archive, not just keyword matching
- Trend computation: The agent continuously computes trend metrics across the categorized archive, tracking mention frequency, topic distribution, sentiment shifts, and activity patterns per competitor over configurable time windows
- Interactive exploration interface: Users access the intelligence through a conversational interface where they can ask questions, request summaries, compare competitors, explore trends, and drill into specific topics or time periods
Standout Features
- Cross-source synthesis: The agent does not just collect articles in parallel; it synthesizes information across sources, recognizing when multiple articles reference the same underlying event and consolidating them into a unified intelligence item rather than creating duplicates
- Strategic signal scoring: Not all competitive news is equally important. The agent scores each item's strategic relevance based on configurable criteria, ensuring that high-impact signals like acquisition announcements or major product launches rise to the top while routine mentions are filed but not flagged
- Temporal trend analysis: Users can query the system for trend-based insights, such as tracking how a competitor's messaging has evolved over the past six months or identifying which topics are receiving increasing attention in the competitive landscape
- Executive briefing generation: On demand or on a scheduled basis, the agent produces formatted competitive briefing documents that summarize the most significant developments, emerging trends, and strategic implications from the recent intelligence intake
- Custom alert configuration: Users can configure alerts for specific competitive triggers, such as being notified immediately when a particular competitor announces a partnership in a specific market segment, ensuring critical signals are not buried in the regular intelligence flow
Who This Agent Is For
This agent delivers the most value to organizations that compete in dynamic markets where competitive moves happen frequently and the cost of missing a signal is high.
- Strategy teams responsible for competitive positioning and market analysis who need continuous, organized intelligence rather than periodic manual research efforts
- Competitive intelligence analysts who want to spend their time on analysis and interpretation rather than collection and organization
- Product managers tracking competitor feature releases, pricing changes, and positioning shifts to inform their own product roadmap decisions
- Sales enablement teams maintaining competitive battle cards and needing a reliable source of current competitive intelligence to keep those materials accurate
- Executive leadership teams who need on-demand answers to strategic competitive questions without waiting for a research team to compile a report
Ideal for: Technology companies, financial services firms, pharmaceutical companies, manufacturing enterprises, and any organization operating in markets with active, well-funded competitors whose moves require continuous monitoring.

Sales Next-Action AI Agent
RAG-powered AI agent that ingests CRM deal data, enriches it with reference materials, and generates personalized next-action recommendations delivered to reps via email, chat, and dashboards.
Benefits
When a sales team manages over ten thousand active opportunities, the sheer volume makes it impossible for any individual or even a management team to maintain visibility into what each deal needs next. This agent solves that problem by delivering clear, prioritized next actions for every opportunity, every day.
- Personalized guidance at enterprise scale: Every sales rep receives specific, context-aware recommendations for their individual opportunities rather than generic process reminders, with the system handling 10,000+ opportunities simultaneously without degradation in recommendation quality
- Multi-channel delivery meets reps where they work: Recommendations arrive through the channels reps already use daily, including email digests, collaboration platform messages, and embedded dashboard views, eliminating the need to log into yet another tool to get actionable intelligence
- RAG-enriched context: Recommendations are not based solely on CRM data. The agent enriches deal context with reference materials including product documentation, competitive battle cards, industry playbooks, and historical win/loss analyses, producing guidance that reflects the full knowledge base of the organization
- Reduced deal slippage: By proactively identifying deals that need attention and prescribing specific actions, the agent prevents opportunities from stalling unnoticed in the pipeline, which is the primary source of forecast misses in large sales organizations
- Consistent execution across territories: Whether a rep is in their first month or their fifth year, they receive the same caliber of deal intelligence, leveling the playing field and reducing the performance variance driven by uneven experience and tribal knowledge
- Management visibility without micromanagement: Sales leaders can see the recommended actions for any rep's pipeline without requiring status update meetings, shifting their coaching conversations from interrogation to strategy
Problem Addressed
A large enterprise sales organization with over 10,000 active opportunities faced a fundamental visibility problem. Sales reps managing dozens of deals each could not effectively prioritize which opportunities needed attention on any given day. The CRM contained rich data about every deal, but the data sat passively in records rather than driving action. Reps made prioritization decisions based on recency bias (working whatever came in most recently), squeaky-wheel dynamics (responding to whichever customer called), or gut instinct rather than systematic analysis of which actions would have the highest impact on pipeline progression.
The consequences accumulated across the organization: deals stalled in mid-pipeline stages without triggering any alert, competitive threats went unaddressed until it was too late, and high-value opportunities received the same attention as low-probability deals. Sales management attempted to address this through weekly pipeline reviews, but reviewing thousands of opportunities in weekly meetings is structurally impossible. The organization needed a system that could analyze every deal continuously, apply institutional knowledge about what works, and deliver personalized guidance to every rep without requiring them to ask for it.
What the Agent Does
The agent operates as a continuous recommendation engine that processes CRM data, enriches it with organizational knowledge, and delivers personalized action plans through multiple channels:
- CRM data ingestion: Deal data from the CRM system flows through ETL pipelines into the agent's processing layer, including opportunity metadata, activity history, contact engagement records, stage transition timestamps, and custom fields specific to the organization's sales methodology
- Reference material enrichment via RAG: The agent maintains a retrieval-augmented generation index over the organization's sales reference materials, including product guides, competitive intelligence, industry playbooks, objection handling frameworks, and historical win/loss post-mortems. When generating recommendations for a specific deal, the agent retrieves relevant reference content to inform its guidance
- Priority scoring and action generation: Each opportunity is scored based on deal value, stage velocity, engagement recency, competitive presence, and strategic alignment. The scoring model produces a prioritized list, and for each priority opportunity, the agent generates specific next-action recommendations grounded in both the deal's CRM data and the relevant reference materials
- Multi-channel delivery: Recommendations are formatted and distributed through the channels the sales team uses: morning email digests with top priorities, inline messages in team collaboration platforms for time-sensitive actions, and embedded dashboard cards for pipeline review sessions
- Feedback loop integration: When reps take actions on recommendations (logging activities, advancing stages, updating deal notes), the system tracks which recommendations were acted upon and their outcomes, continuously improving the recommendation model
- Manager roll-up and alerts: Sales managers receive aggregated views showing which opportunities across their team have critical pending actions, which reps may need coaching support, and where the pipeline has concentration risk
Standout Features
- Enterprise-scale RAG architecture: The retrieval-augmented generation layer handles a large and continuously growing reference corpus without performance degradation, ensuring that recommendations stay current as new competitive intelligence, product updates, and industry insights are added to the knowledge base
- Methodology-aware recommendations: The agent understands the organization's sales methodology (MEDDIC, Challenger, SPIN, or custom frameworks) and generates recommendations that align with methodology-specific criteria, reinforcing process discipline without adding administrative overhead
- Temporal intelligence: The agent factors time-based patterns into its recommendations, understanding that a deal stalled for two weeks at the proposal stage requires different action than one that just entered that stage yesterday. It calibrates urgency and action type based on where the deal is relative to expected progression timelines
- Cross-deal pattern recognition: By analyzing the full portfolio simultaneously, the agent identifies patterns that individual reps cannot see, such as when multiple deals in the same account are sending conflicting signals or when a competitive threat is emerging across a specific segment
- Configurable delivery cadence: Organizations can configure recommendation delivery frequency, channel preferences, and priority thresholds per role, ensuring that reps get daily tactical guidance while managers receive weekly strategic summaries without information overload
Who This Agent Is For
This agent is built for sales organizations operating at scale where the volume of active opportunities exceeds any individual's ability to maintain awareness, and where systematic deal intelligence can measurably impact revenue outcomes.
- Sales representatives managing large territories with dozens of concurrent opportunities who need daily guidance on where to focus their limited selling time
- Sales managers overseeing teams with hundreds of combined pipeline opportunities who need scalable visibility into deal health and rep execution
- Revenue operations leaders building a data-driven sales execution framework that reduces reliance on individual judgment and ensures consistent pipeline management
- Sales enablement teams responsible for ensuring that organizational knowledge (competitive intel, playbooks, methodology) actually reaches reps at the moment of need rather than sitting in unused repositories
- CROs and VP Sales at organizations where pipeline coverage, deal velocity, and forecast accuracy are board-level metrics that need systematic improvement
Ideal for: Enterprise sales organizations, large B2B SaaS companies, financial services sales teams, and any revenue organization managing thousands of concurrent opportunities through a CRM system.
Opportunity Summarizer AI Agent
AI agent that summarizes CRM opportunity and customer data, then generates next-action recommendations for sales teams to accelerate deal progression.
Benefits
The agent transforms raw CRM data into structured intelligence that sales teams can act on immediately, compressing what used to be 30 minutes of manual deal review into a sub-minute automated briefing.
- Automated opportunity digests: The agent generates concise summaries of each opportunity's current state, including deal stage, engagement history, stakeholder map, and recent activity, formatted for rapid consumption during pipeline reviews or before customer calls
- Context-aware next actions: Rather than generic to-do lists, the agent analyzes the specific deal context including stage duration, engagement gaps, competitive signals, and stakeholder coverage to recommend the precise next actions most likely to advance the deal
- Reduced CRM navigation overhead: Sales reps no longer need to click through multiple CRM views, activity logs, and contact records to piece together a deal's status. The summary aggregates all relevant data into a single, structured view
- Consistent deal intelligence across the team: Every rep receives the same quality of deal analysis regardless of their experience level. Junior reps get the same strategic insights that senior reps would derive from manual analysis
- Faster pipeline review cycles: Sales managers can review pipeline status across their entire team using agent-generated summaries instead of requiring each rep to verbally walk through every deal, cutting meeting preparation time significantly
- Improved forecast accuracy: By surfacing engagement patterns, stage duration anomalies, and activity gaps systematically, the agent helps identify deals that are stalling or at risk before they show up as forecast misses
Problem Addressed
Sales representatives managing complex B2B pipelines spend a disproportionate amount of time on deal administration rather than selling. Before every customer interaction, a rep needs to review the opportunity history: when was the last meeting, who attended, what was discussed, what commitments were made, which stakeholders have been engaged, and what competitive threats have surfaced. This information exists across CRM records, activity logs, email threads, and meeting notes, but assembling it into a coherent picture requires manual effort that scales poorly as pipeline size grows.
The result is predictable: reps either spend too much time preparing for each interaction (reducing selling time) or they go in underprepared (reducing effectiveness). Sales managers face a parallel problem during pipeline reviews, where the quality of deal intelligence depends entirely on how thoroughly each rep has maintained their CRM records and how well they can articulate deal status on the spot. There is no systematic mechanism to synthesize CRM data into actionable deal intelligence and recommend specific next steps based on where each opportunity actually stands.
What the Agent Does
The agent connects to CRM data, processes opportunity records and associated activity data, and produces structured outputs that serve both rep-level and manager-level workflows:
- Opportunity data aggregation: The agent pulls together all data associated with an opportunity including deal metadata, contact roles, activity timeline, email correspondence summaries, meeting notes, and any custom fields relevant to the sales process
- AI-powered summarization: Natural language processing condenses the aggregated data into a structured summary covering deal overview, current stage assessment, key stakeholder status, recent activity highlights, and open risks or blockers
- Next-action recommendation engine: Based on the deal summary and comparison against successful deal patterns, the agent generates prioritized next-action recommendations. These might include scheduling a specific stakeholder meeting, addressing a competitive concern, or escalating a stalled procurement process
- Deal health scoring: The agent calculates a composite health score based on engagement frequency, stakeholder coverage, stage velocity, and activity recency, providing an objective signal that complements the rep's qualitative assessment
- Formatted output delivery: Summaries and recommendations are formatted for the rep's preferred consumption channel, whether that is a dashboard card, a pre-meeting briefing document, or an inline CRM view
- Continuous refresh: As new activities are logged in the CRM, the agent automatically updates its summaries and recalculates recommendations, ensuring deal intelligence stays current without requiring manual triggers
Standout Features
- Pattern-matched recommendations: The next-action engine does not rely on generic playbook rules. It compares the current opportunity's profile against patterns from historically won and lost deals to surface actions that have the highest correlation with positive outcomes in similar deal contexts
- Multi-stakeholder mapping: The agent automatically identifies engagement gaps across the buying committee, flagging when key decision-maker roles have not been contacted recently or when influence mapping suggests untapped champions
- Competitive signal detection: Activity notes and email references are scanned for competitive mentions, allowing the agent to flag competitive threats and recommend counter-positioning actions even when competitors are not formally tracked in the CRM
- Stage duration analytics: The agent tracks how long each opportunity has spent in its current stage relative to benchmarks for similar deal sizes and segments, surfacing stalled deals that might otherwise pass unnoticed in a large pipeline
- Manager-level roll-up views: Beyond individual opportunity summaries, the agent produces team-level intelligence showing pipeline composition, risk distribution, and aggregate next-action priorities across the entire portfolio
Who This Agent Is For
This agent is engineered for B2B sales organizations where deal complexity, pipeline volume, and CRM data richness create a genuine need for automated deal intelligence.
- Sales representatives managing 20+ active opportunities who need quick deal summaries before customer interactions without manually reviewing CRM history
- Sales managers running weekly pipeline reviews who need objective deal health assessments and recommended actions across their team's portfolio
- Revenue operations teams building systematic deal intelligence capabilities that scale independently of individual rep discipline
- Sales enablement professionals who want to ensure every rep has access to consistent, data-driven deal preparation regardless of tenure or CRM proficiency
- VP Sales and CROs who need pipeline visibility that goes beyond self-reported deal stages to include behavioral signals and engagement patterns
Ideal for: B2B SaaS companies, enterprise technology vendors, professional services firms, and any sales organization managing complex, multi-stakeholder deals through a CRM system.

Document Parsing & Search AI Agent
AI agent that processes PDFs and images dropped into file storage through OCR, classification, and extraction pipelines, then enables natural-language search across all processed documents.
Benefits
If you have ever spent an afternoon searching through folders of scanned PDFs trying to find a specific clause or data point, this agent eliminates that problem permanently. It converts your unstructured document repository into a searchable, structured knowledge base.
- Drop-and-forget document processing: Users upload PDFs, images, or scanned documents to a designated file storage location, and the agent handles everything from there. OCR extracts the text, classification models identify the document type, and extraction routines pull out key fields automatically
- Natural-language search across all documents: Instead of remembering file names or folder structures, users ask questions in plain language and receive relevant document excerpts. The search understands context, so querying for a specific topic returns results from across the entire document archive
- Structured data from unstructured sources: The extraction pipeline pulls specific data fields from documents (dates, amounts, names, reference numbers) and stores them in structured format, enabling filtering, reporting, and downstream automation that was impossible with raw scanned files
- Consistent classification at scale: Every document is categorized according to the same taxonomy, regardless of who uploaded it or when. This consistency makes it possible to generate accurate counts, track processing volumes, and ensure compliance documentation is properly tagged
- Reduced manual document handling: Teams that previously spent hours reading, categorizing, and filing documents can let the pipeline handle the routine work while focusing their expertise on documents that require human judgment
- Audit trail for every document: The pipeline logs every processing step, from OCR confidence scores to classification decisions to extraction results, creating a complete provenance record for each document in the system
Problem Addressed
Most organizations accumulate large volumes of documents in PDF and image format that contain critical business information but remain effectively unsearchable. Contracts, invoices, compliance certificates, technical specifications, and correspondence arrive as scanned files or digital PDFs and get stored in file systems where the only way to find specific content is to open documents one by one. There is no automated pipeline for ingesting these documents, extracting their content, classifying them by type, and making them retrievable through search.
The absence of document intelligence creates real operational friction. Legal teams cannot quickly locate specific contract terms across hundreds of agreements. Compliance officers cannot verify that all required certifications are current without manually checking each file. Operations teams cannot aggregate data trapped in PDF reports without re-entering it manually. The documents contain the answers, but without OCR, classification, extraction, and search capabilities, those answers remain locked inside static files.
What the Agent Does
The agent implements a complete document processing pipeline from ingestion through search, handling every step automatically:
- File ingestion: Documents are dropped into a designated file storage area. The agent monitors this location and automatically queues new files for processing, supporting PDFs, scanned images, TIFF files, and common image formats
- OCR text extraction: Optical character recognition converts image-based documents into machine-readable text, handling multi-column layouts, tables, handwriting (where legible), and mixed-format pages with configurable quality thresholds
- Document classification: AI models analyze the extracted content and assign each document to a category within the organization's taxonomy, such as contract, invoice, compliance certificate, technical specification, or correspondence
- Field extraction: Based on the document classification, specialized extraction routines identify and pull out key data fields, including dates, monetary amounts, party names, reference numbers, and domain-specific values relevant to each document type
- Index and store: Extracted text, classification labels, and structured fields are indexed for search and stored alongside the original document, creating a rich metadata layer that supports both keyword and semantic search
- Natural-language search interface: Users interact with the document repository through a conversational interface where they can ask questions, request specific documents, or explore content by topic without needing to know file names or folder locations
Standout Features
- Multi-stage pipeline architecture: Built using a combination of workflows, code engine functions, and file processing services, the pipeline handles each processing stage independently, meaning OCR failures do not block classification of successfully extracted documents
- Confidence scoring at every stage: OCR quality, classification certainty, and extraction confidence are all scored and stored, enabling quality-aware routing where low-confidence documents are flagged for human review rather than processed blindly
- Custom taxonomy support: The classification model can be configured to match any organization's document taxonomy rather than forcing a generic category structure, and new categories can be added by providing training examples
- Incremental processing: The pipeline processes new documents as they arrive rather than requiring batch runs, meaning newly uploaded documents are searchable within minutes rather than waiting for a nightly processing cycle
- Cross-document search intelligence: The natural-language search does not just match keywords within individual documents; it understands relationships across the corpus, enabling queries like finding all documents related to a particular project or vendor across different document types
Who This Agent Is For
This agent is purpose-built for teams drowning in document volume who need structured, searchable access to information trapped in PDFs and scanned files.
- Knowledge workers who spend significant time searching through document repositories to find specific information and need a faster path to answers
- Legal and compliance teams managing large volumes of contracts, certifications, and regulatory documents that need to be searchable and auditable
- Operations teams that receive business-critical data in PDF format (invoices, purchase orders, shipping documents) and need to extract structured data for downstream processing
- Records management professionals responsible for organizing and classifying large document archives according to retention policies and regulatory requirements
- Any team that has asked the question: we know this information is in a document somewhere, but how do we find it?
Ideal for: Legal departments, compliance offices, procurement teams, healthcare records management, insurance claims processing, government agencies, and any organization with significant PDF and scanned document volumes.

Survey Sentiment Analysis AI Agent
AI agent that uses ETL-based AI tiles to automatically score sentiment in free-text survey responses at scale, turning unstructured feedback into quantified, actionable insights.
Benefits
Organizations collecting open-ended survey feedback can now convert every free-text response into a quantified sentiment signal without manual review, unlocking insights that were previously buried in unstructured data.
- Complete feedback coverage: Every survey response receives a sentiment score automatically, eliminating the sampling problem where only a fraction of open-ended answers were ever reviewed by a human analyst
- Real-time pulse on customer experience: Sentiment scores flow directly into dashboards, giving CX teams a continuously updated view of how customers feel about products, services, and interactions without waiting for quarterly manual analysis cycles
- Trend detection at scale: By scoring every response consistently, the agent reveals sentiment shifts across time periods, customer segments, regions, and product lines that would be invisible in manual spot-check reviews
- Reduced analyst burden: Teams that previously spent days reading and categorizing open-ended responses can redirect their effort toward interpreting trends and designing interventions rather than tagging individual comments
- Consistent scoring methodology: AI-driven sentiment scoring applies the same criteria to every response, removing the subjectivity and inconsistency inherent in having multiple human reviewers interpret emotional tone differently
- Faster action on negative signals: Negative sentiment responses are immediately quantified and surfaced, enabling service recovery teams to respond to dissatisfied customers within hours rather than discovering problems weeks later during a manual review pass
Problem Addressed
Organizations that rely on surveys to gauge customer satisfaction, employee engagement, or product feedback face a persistent challenge: the most valuable data lives in free-text fields, and those fields are the hardest to analyze at scale. Multiple-choice questions produce clean, structured data that flows directly into dashboards. But the open-ended responses where customers explain what actually happened, what frustrated them, or what delighted them pile up in spreadsheets, largely unread.
The traditional approach involves assigning analysts to read through responses manually, categorizing them by topic and sentiment. This process is slow, expensive, and inherently limited by human bandwidth. A team that can review a few hundred responses per week falls hopelessly behind when surveys generate thousands. The result is a paradox: organizations invest in collecting qualitative feedback, then lack the capacity to extract value from it. Sentiment trends go undetected, emerging issues are identified too late, and the feedback loop that surveys are designed to create never fully closes.
What the Agent Does
The agent processes free-text survey responses through an automated sentiment analysis pipeline built directly into the data transformation layer:
- Response ingestion: Survey responses are collected from online survey platforms and loaded into the processing pipeline, preserving all metadata including respondent segment, survey date, question context, and response channel
- AI sentiment scoring: Each free-text response passes through AI-powered sentiment analysis tiles within the ETL pipeline, receiving a polarity score (positive, negative, neutral) along with a confidence rating and intensity measure
- Contextual classification: Beyond simple polarity, the agent categorizes responses by topic area including product quality, service experience, pricing perception, and feature requests so sentiment can be analyzed within meaningful business categories
- Aggregation and trending: Individual sentiment scores are aggregated across configurable dimensions such as time period, customer segment, product line, and geography to produce trend visualizations that reveal shifts in customer perception
- Dashboard integration: Scored and categorized data flows directly into interactive dashboards where stakeholders can explore sentiment distributions, drill into specific segments, and compare sentiment across survey waves
- Alert-driven escalation: Configurable thresholds trigger notifications when sentiment scores drop below acceptable levels for specific segments or when unusual patterns emerge, enabling proactive response to emerging issues
Standout Features
- ETL-native processing: Sentiment analysis runs directly within the data transformation pipeline rather than requiring a separate ML platform, meaning scored data is available in dashboards as soon as the pipeline completes without additional integration work
- No-code configuration: Survey administrators can configure the sentiment pipeline using visual ETL tiles rather than writing code, adjusting scoring parameters, topic categories, and aggregation rules through a drag-and-drop interface
- Multilingual support: The AI scoring engine handles responses in multiple languages within the same pipeline, critical for organizations running surveys across international markets without requiring separate processing workflows per language
- Historical rescoring: When scoring models improve or business categories change, the entire response archive can be rescored through the pipeline, ensuring historical trend data remains consistent with current methodology
- Segment-aware benchmarking: The agent automatically calculates sentiment benchmarks per segment, enabling stakeholders to understand whether a particular score is above or below the norm for that customer group, product, or region
Who This Agent Is For
This agent delivers immediate value to any organization that collects free-text feedback at scale and needs to convert qualitative responses into quantified, actionable intelligence.
- Survey administrators managing customer satisfaction, NPS, or product feedback programs who need to process thousands of open-ended responses per survey cycle
- Customer experience teams tracking sentiment trends across touchpoints and needing real-time visibility into how customers feel about recent interactions
- Product managers using survey feedback to prioritize feature development and wanting quantified sentiment data to support roadmap decisions
- HR and employee engagement teams analyzing open-ended responses from internal surveys to identify workplace culture trends and emerging concerns
- Market research analysts who need consistent, scalable sentiment scoring across large survey datasets without manual coding effort
Ideal for: Any organization running regular surveys with free-text fields including customer satisfaction programs, employee engagement surveys, product feedback loops, market research studies, and post-event evaluations.

Marketing Mix AI Agent
AI agent that builds a Marketing Mix Model using ML-based ROI attribution across channels, lets users input a budget and receive optimal allocation recommendations, and provides an interactive dashboard for scenario testing different spend distributions.
Replace budget debates with ML-powered allocation evidence.
The Marketing Mix AI Agent was built for a major healthcare provider whose marketing department had reached a common inflection point: spending was significant, channels were numerous, and the ability to justify allocation decisions with data was insufficient. Their marketing team was making budget decisions based on a combination of historical precedent, vendor recommendations, and leadership intuition. They could report on individual channel metrics, but they could not answer the fundamental question that drives marketing ROI: given a fixed budget, what is the optimal distribution across channels to maximize patient acquisition and revenue? The Marketing Mix Model approach had been proven in academic and enterprise contexts, but building one required data science capabilities, cross-channel data integration, and a delivery mechanism that made the output usable by marketing leaders who were not data scientists.
Benefits
This agent gives marketing teams a quantitative foundation for budget allocation decisions, replacing the intuition-driven planning process with ML-powered optimization that maximizes measurable ROI.
- Data-driven budget justification: Marketing leaders can present allocation recommendations backed by attribution modeling rather than defending spend decisions based on gut feel or vendor pitch decks during budget review cycles
- Optimal channel allocation: Input a total budget number and receive a mathematically optimized distribution across channels that maximizes expected return based on historical performance patterns and diminishing returns curves
- Scenario testing capability: An interactive dashboard lets planners model what-if scenarios, testing how different budget levels and channel mixes would be expected to perform before committing real dollars
- Channel ROI transparency: Each channel's contribution to overall performance is quantified through attribution modeling, revealing which channels deliver outsized returns and which are consuming budget with diminishing impact
- Cross-channel interaction effects: The model captures how channels influence each other, identifying combinations where paired investment delivers more than the sum of individual channel performance
- Diminishing returns identification: For each channel, the model identifies the spend level beyond which additional investment produces progressively less return, preventing over-investment in channels that have reached saturation
Problem Addressed
Marketing budget allocation is one of the highest-stakes recurring decisions in any organization, yet it is consistently made with less analytical rigor than decisions involving a fraction of the budget. A procurement team evaluating a $50,000 vendor contract will conduct a thorough analysis with competitive bids and ROI projections. A marketing team allocating $5 million across channels often relies on last year's split adjusted by subjective judgment. The asymmetry exists not because marketers are less rigorous but because the analytical infrastructure for multi-channel budget optimization has traditionally been unavailable at the speed and usability level that planning cycles demand.
The specific challenge for healthcare marketing is compounded by channel complexity and regulatory constraints. Patient acquisition paths cross digital advertising, content marketing, physician referral programs, community events, direct mail, and organic search. Each channel operates on different time horizons, targets different audience segments, and interacts with other channels in ways that simple last-touch attribution cannot capture. A patient who converts through a search may have been influenced by a direct mail piece received two weeks earlier and a community health event attended three months ago. Without a model that accounts for these cross-channel effects, the search channel receives all the attribution credit, the direct mail program gets cut in the next budget cycle, and the organization unknowingly removes a channel that was driving the conversions it is now trying to scale.
What the Agent Does
The agent operates as a complete marketing analytics and planning platform, from model construction through interactive scenario testing and allocation recommendation:
- Cross-channel data integration: Aggregates marketing spend, impression, engagement, and conversion data from all active channels into a unified dataset structured for Marketing Mix Model analysis
- ML-based attribution modeling: Builds a Marketing Mix Model using machine learning to quantify each channel's independent contribution and cross-channel interaction effects on the target conversion metric
- Response curve generation: Produces diminishing returns curves for each channel showing how ROI changes at different spend levels, identifying the investment range where each channel delivers optimal return
- Budget optimization engine: Accepts a total budget input and applies mathematical optimization against the response curves to recommend the allocation that maximizes expected conversions or revenue
- Interactive scenario dashboard: Provides a visual interface where marketing planners can adjust budget levels, lock specific channel allocations, and test alternative distributions to see predicted performance outcomes in real time
- Model refresh and validation: Automatically retrains the underlying model as new performance data accumulates, maintaining accuracy as market conditions, channel performance, and audience behavior evolve over time
Standout Features
- Practitioner-accessible optimization: The budget optimization interface is designed for marketing planners, not data scientists. Users input a budget number and receive a recommended allocation without needing to understand the underlying ML methodology
- Constraint-aware optimization: Users can set minimum or maximum spend levels for specific channels before running optimization, reflecting business constraints like contractual commitments or strategic priorities that pure mathematical optimization would ignore
- Cross-channel synergy quantification: The model explicitly measures interaction effects between channels, showing marketing teams where paired investments produce amplified returns and where channel combinations produce diminishing returns
- Historical accuracy tracking: Each planning cycle's recommendations are compared against actual outcomes when results data becomes available, building a track record of model accuracy that strengthens confidence in future recommendations
- Incremental contribution isolation: For each channel, the model isolates the truly incremental contribution from the baseline performance that would have occurred without marketing investment, preventing the common error of crediting marketing with organic demand
Who This Agent Is For
This agent is designed for marketing organizations where budget allocation decisions are significant enough to warrant quantitative optimization but where the team lacks in-house data science resources to build and maintain Marketing Mix Models independently.
- Marketing directors and CMOs responsible for defending budget allocation decisions to finance and executive leadership who need evidence-based recommendations rather than experience-based assertions
- Media planners managing multi-channel campaigns who need to understand how budget reallocation between channels would impact expected performance before making changes
- Marketing analytics teams that want to move from descriptive reporting to prescriptive optimization without building a custom data science infrastructure
- Finance teams that partner with marketing on budget planning and need a quantitative framework for evaluating allocation proposals
Ideal for: Healthcare systems, financial services companies, higher education institutions, large retailers, and any organization spending across five or more marketing channels where the total budget is large enough that even a 10% improvement in allocation efficiency represents significant revenue impact.

Sales Optimization AI Agent
AI agent that clusters customers by purchasing behavior and region, scores each account's untapped opportunity, and enables peer-based sales conversations that drive incremental purchases by showing retailers what similar shops in their segment are carrying.
A sales rep walks into a pro shop with a product catalog and a quota. A better-equipped rep walks in with data showing that shops just like this one are carrying three product lines this shop has never ordered. One conversation converts. The other stalls.
The Sales Optimization AI Agent was built for a premium sporting goods manufacturer whose sales team covered a national network of specialty retail accounts. Their reps understood their products deeply, but they lacked systematic visibility into what each customer could be purchasing compared to what they actually were. Every account was treated as an independent relationship, with sales approaches based on the rep's personal experience and the customer's stated preferences. What was missing was the peer lens: the ability to show a pro shop owner that stores with similar customer demographics, geographic profiles, and purchasing patterns in their cluster were successfully carrying product lines they had never considered. The manufacturer needed to transform their sales conversations from product pitches into data-driven consultations.
Benefits
This agent fundamentally changes the sales conversation from product-centric pitching to data-driven consulting, giving every rep the analytical ammunition that previously only the best performers developed through years of experience.
- Peer-powered sales conversations: Reps can show each retailer exactly which product lines their most similar peers carry, converting abstract product recommendations into concrete evidence that drives incremental purchases
- Prioritized account focus: Opportunity scores rank every account by untapped revenue potential, ensuring reps invest their limited field time in the accounts where data indicates the highest conversion probability
- New rep acceleration: Sales representatives who are new to a territory gain immediate access to the same customer intelligence that experienced reps build over years, compressing the ramp period from months to days
- Product line expansion: By identifying specific product categories that peer accounts carry but a given customer does not, the agent creates natural upsell conversations grounded in demonstrated market demand rather than sales pressure
- Regional pattern insights: Clustering by geography reveals regional preferences and seasonal patterns that inform not just sales tactics but inventory planning and marketing campaign targeting
- Reduced guesswork in territory planning: Territory managers can allocate rep time and marketing resources based on quantified opportunity concentration rather than historical visit patterns or geographic convenience
Problem Addressed
Specialty retail sales forces operate in an information asymmetry that works against them. The rep knows the product catalog. The retailer knows their customers. Neither has a systematic view of what similar retailers in similar markets have found successful. The best reps develop this knowledge organically through years of relationship building across their territories, but it lives in their heads rather than in the organization's systems. When a top rep retires or changes roles, their institutional knowledge of which accounts have untapped potential and which product recommendations have worked in similar stores leaves with them.
The second problem is prioritization. A sales rep covering 150 accounts cannot give equal attention to all of them. Without data-driven opportunity scoring, reps default to spending time with their favorite accounts, their most vocal accounts, or their geographically convenient accounts. The accounts with the highest untapped potential may receive the least attention simply because nobody quantified the opportunity. A pro shop doing $50,000 annually with the brand might have $120,000 in potential based on what its peer cluster purchases, but without that comparison, the rep treats it as a satisfied account rather than an underperforming one. The revenue sits on the table because the visibility does not exist to see it.
What the Agent Does
The agent operates as a sales intelligence engine that transforms raw transaction data into prioritized, peer-contextualized account recommendations that reps can use in their next customer conversation:
- Behavioral clustering: Groups customers into peer segments based on purchasing patterns, product mix, order frequency, seasonal buying behavior, and spend levels, creating the comparison framework that powers peer-based selling
- Geographic segmentation: Overlays regional context onto behavioral clusters, recognizing that customer similarity depends on both purchasing behavior and market characteristics like climate, demographics, and competitive landscape
- Opportunity scoring: Calculates a quantified opportunity score for each account by comparing its current purchasing profile against its cluster's aggregate, identifying the specific product categories where the gap is largest
- Peer comparison reports: Generates account-level reports showing the specific product lines that similar stores carry, the average spend in each category within the peer group, and the estimated revenue opportunity
- Prioritized account lists: Ranks accounts by opportunity score within each rep's territory, giving field teams a data-driven visit priority list that maximizes the revenue potential of their available selling time
- Trend tracking: Monitors how each account's purchasing profile evolves relative to its cluster over time, identifying accounts that are growing into new product categories as well as accounts that are falling behind their peers
Standout Features
- Peer-driven conversation framework: The agent does not just produce data for internal analysis. It generates the specific comparison points and product recommendations formatted for use in face-to-face retail conversations, bridging the gap between analytical insight and field execution
- Multi-dimensional clustering: Customer segments are defined by the intersection of purchasing behavior, geographic context, and store characteristics rather than any single dimension, producing peer groups that retailers recognize as genuinely similar to their own business
- Dynamic opportunity recalculation: As customers make new purchases or their cluster composition shifts, opportunity scores update automatically, ensuring that prioritization reflects current reality rather than a static snapshot
- Product whitespace mapping: Beyond aggregate opportunity scores, the agent identifies the specific product categories that represent the largest revenue gaps for each account, giving reps a precise conversation agenda rather than a general instruction to sell more
Who This Agent Is For
This agent is designed for sales organizations that sell through specialty retail networks where peer-based positioning and account-level opportunity quantification can directly drive incremental revenue.
- Field sales representatives covering specialty retail accounts who need data-driven conversation tools to supplement their product knowledge and relationship skills
- Regional sales managers responsible for territory performance who need to ensure their teams focus on the highest-opportunity accounts rather than defaulting to habitual visit patterns
- Sales operations teams building territory plans and quota allocations who need quantified opportunity data at the account level rather than top-down estimates
- Marketing teams planning co-op programs and promotional campaigns who need to understand which product categories have the most whitespace across the retail network
Ideal for: Sporting goods manufacturers, specialty food and beverage distributors, premium consumer brands, and any company selling through a network of independent retailers where peer comparison is a powerful motivator for product line expansion and incremental purchasing.

Dashboard Insights AI Agent
AI agent that sits on top of existing dashboards, analyzes the underlying data and layout context, and generates 3-5 plain-language key takeaways so business users can understand what matters without specialized training or analyst support.
You built the dashboards. You trained the users. They still send messages asking what the numbers mean. The problem was never the data. It was the last mile between a chart and an insight.
The Dashboard Insights AI Agent was created because a premium home goods retailer's analytics team had reached a breaking point. They had invested heavily in building comprehensive dashboards across their business intelligence platform. The dashboards were well-designed. The data was accurate. The visualizations were clear to anyone with analytics training. And yet the analytics team spent a significant portion of their time doing two things that had nothing to do with actual analysis: training users on how to interpret the dashboards, and fielding requests for specific data pulls that the dashboards already contained but that users could not find or interpret on their own. The bottleneck was not data availability. It was data comprehension at the point of consumption.
Benefits
This agent eliminates the comprehension gap between well-built dashboards and the business users who need insights from them but lack the training to extract those insights independently.
- Zero-training dashboard consumption: Business users see the key takeaways from any dashboard without needing to understand chart types, metric definitions, or analytical frameworks, because the agent translates the data into plain-language bullet points
- Analytics team liberation: The hours previously spent training users and answering interpretation questions are eliminated, freeing analysts for the investigative and strategic work that actually requires their expertise
- Consistent insight quality: Every dashboard consumer receives the same set of key takeaways regardless of their analytical sophistication, eliminating the variance in interpretation that occurs when different users draw different conclusions from the same visualization
- Increased dashboard adoption: Users who previously avoided dashboards because they found them overwhelming or confusing now engage with them regularly because the insight card removes the barrier to understanding
- Faster decision-making: Instead of scheduling a meeting with the analytics team to understand what a dashboard is telling them, business leaders can read 3-5 bullet points and act immediately
- Context-aware interpretation: The agent accounts for the dashboard's data dictionary and layout structure when generating insights, producing takeaways that reference the specific metrics and dimensions the dashboard was designed to communicate
Problem Addressed
There is a fundamental disconnect in how organizations think about data democratization. The assumption is that if you build good dashboards and make them accessible, people will use them to make better decisions. In practice, the investment in dashboard development creates a capability that only a fraction of the intended audience can fully utilize. The analytics team builds dashboards designed for people who think in metrics, dimensions, and variance ranges. The business users who are supposed to consume those dashboards think in questions: Are we on track this month? What should I worry about? Where should I focus my team? The translation between what the dashboard shows and what the business user needs to know happens either in the user's head, unreliably, or through a conversation with an analyst, expensively.
The cost of this disconnect is distributed and largely invisible. Every time a user opens a dashboard, spends two minutes trying to interpret it, gives up, and sends a message to the analytics team, the organization pays twice: the user does not get the insight when they need it, and the analyst loses focus to answer a question the dashboard was supposed to answer. Multiply this across hundreds of dashboard consumers and dozens of dashboards, and the analytics team becomes a help desk for data comprehension rather than a strategic function driving business intelligence. The solution is not better dashboards or more training. It is an intelligent layer that reads the dashboard the way an analyst would and communicates the takeaways the way a business user needs to receive them.
What the Agent Does
The agent operates as an interpretive intelligence layer that sits directly on dashboard pages, analyzing the underlying data in context and producing consumable insight summaries:
- Dashboard context analysis: Reads the dashboard's data dictionary, layout structure, metric definitions, and dimensional hierarchy to understand what the dashboard was designed to communicate and what constitutes a meaningful finding
- Automated data interpretation: Analyzes the current data across all visualizations on the page, identifying the trends, anomalies, comparisons, and status indicators that an experienced analyst would highlight when walking a colleague through the dashboard
- Key takeaway generation: Produces 3-5 plain-language bullet points that communicate the most important insights from the current data, prioritized by business impact and relevance to the dashboard's intended purpose
- Insight card rendering: Displays the generated takeaways as a card positioned prominently on the dashboard page, ensuring users see the interpretation before diving into the underlying visualizations
- Dynamic refresh: Updates the insight summary as the underlying data changes, so the takeaways always reflect the current state rather than becoming stale descriptions of data the user cannot see anymore
- Contextual metric referencing: Each takeaway bullet references the specific metrics, time periods, and comparisons that support the insight, providing enough context for users who want to verify the finding in the underlying charts
Standout Features
- Layout-aware intelligence: The agent does not just analyze data in isolation. It reads the dashboard's structural context, understanding which metrics are grouped together, what comparisons the layout implies, and which visualizations are designed to be read in sequence
- Business language output: Takeaways are written in the language business users speak, not in the language analysts think. Revenue is 8% below target this month, driven primarily by the West region rather than technical analytical jargon that requires additional interpretation
- Anomaly prioritization: When multiple insights compete for the 3-5 takeaway slots, the agent prioritizes anomalies, exceptions, and action-requiring items over confirmatory observations, ensuring users see what needs attention rather than what is running as expected
- Zero-integration deployment: The insight card sits on top of existing dashboards without requiring any modification to the underlying data models, visualizations, or page structures, making deployment a configuration step rather than a rebuild
Who This Agent Is For
This agent is built for organizations that have invested in dashboard infrastructure but find that the gap between data availability and data comprehension is undermining the return on that investment.
- Analytics teams that spend more time explaining dashboards than building new analytical capabilities and need to redirect their capacity toward strategic work
- Business leaders who need to understand performance status quickly from dashboards without scheduling time with an analyst to walk them through the data
- Operations managers across distributed organizations who access dashboards daily but lack the analytical training to consistently identify the most important signals
- Organizations with large dashboard consumer populations where the ratio of users to analysts makes one-on-one data interpretation unsustainable
Ideal for: Retail enterprises, financial services firms, healthcare systems, manufacturing organizations, and any company with a large non-technical dashboard audience where the analytics team has become a bottleneck for data comprehension rather than a driver of data strategy.

Financial Insights AI Agent
AI agent that automates financial reporting by querying live data, generating formatted analysis with variance commentary, and distributing executive-ready financial insights to stakeholders on a recurring schedule without manual intervention.
The finance team closes the books on Friday. By Tuesday, they have finally assembled the variance report. By the time leadership reads it on Thursday, the data is already a week old. Every manual step in the chain erodes the value of timely financial insight.
The Financial Insights AI Agent addresses the structural bottleneck in financial reporting that exists in virtually every enterprise: the gap between when financial data is available and when formatted, contextualized financial insights reach the people who need them. A large fitness and lifestyle enterprise with hundreds of locations and complex revenue streams faced this problem at scale. Their finance team produced recurring reports that required pulling data from multiple financial systems, computing variances against budget and prior periods, writing commentary explaining the drivers behind significant deviations, and formatting the output for executive consumption. The report format was well-established. The analytical framework was defined. Yet the process consumed substantial analyst time every cycle because the assembly required human coordination across data sources, variance interpretation, and narrative generation that no standard reporting tool could automate end to end.
Benefits
This agent converts financial reporting from a labor-intensive production process into an automated intelligence pipeline, delivering faster insights with greater consistency and lower operational cost.
- Near-real-time financial visibility: Reports that previously required days of manual assembly are produced within minutes of data availability, giving leadership current financial intelligence rather than stale retrospective summaries
- Consistent analytical rigor: Every report applies the same variance thresholds, comparison frameworks, and materiality standards regardless of which analyst is available or how much time pressure the cycle faces
- Automated variance commentary: The agent generates explanatory narratives for significant variances using the same analytical logic the finance team applies manually, converting raw numbers into contextualized insights
- Freed analyst capacity: Finance analysts previously dedicated to report assembly can redirect their time to the exception analysis, forecasting, and strategic advisory work that requires human expertise and business judgment
- Stakeholder self-service reduction: With comprehensive automated reports arriving on schedule, the volume of ad-hoc requests from executives asking the finance team to explain specific numbers decreases significantly
- Audit-consistent methodology: Every report is generated using the same computational logic and data sources, eliminating the methodological drift that occurs when different analysts build the same report using slightly different approaches
Problem Addressed
Financial reporting at enterprise scale exists in a technology gap. The underlying data lives in ERP systems, accounting platforms, and operational databases that are fully capable of producing raw numbers on demand. Business intelligence tools can visualize those numbers in dashboards and charts. But between the data existing and leadership having an actionable financial report lies a translation layer that technology has not addressed: variance interpretation, commentary generation, and the structured narrative that turns financial metrics into decision-relevant insights. This translation layer is where finance analysts spend most of their reporting time.
The cost of this gap compounds with organizational complexity. A company operating hundreds of locations across multiple revenue streams generates thousands of line items that need variance analysis every reporting period. Each significant variance needs context: is it a timing difference, a one-time event, an operational issue, or a trend? Answering that question for each line item requires cross-referencing multiple data sources, applying institutional knowledge about the business, and making judgment calls about materiality and significance. When this work is done manually, it is both time-consuming and inconsistent. The same variance might receive detailed commentary from one analyst and a one-line note from another. Leadership receives reports of varying depth and quality, and the finance team spends their weeks on production rather than analysis.
What the Agent Does
The agent functions as a complete financial reporting engine, executing every step from data extraction through insight generation and stakeholder distribution:
- Multi-source data extraction: Connects to financial systems, ERP platforms, and operational databases to pull actuals, budgets, forecasts, and prior-period comparisons for all reporting entities and line items
- Automated variance computation: Calculates budget-to-actual, prior-period, and forecast variances across every relevant dimension, applying materiality thresholds to distinguish significant deviations from normal fluctuation
- Contextual commentary generation: Produces explanatory narratives for material variances using pattern recognition against historical commentary, seasonal context, and known business events to generate the interpretive layer executives expect
- Executive report formatting: Assembles the complete report in the organization's established format, including summary tables, detailed breakdowns, trend visualizations, and the written commentary that accompanies each section
- Automated stakeholder distribution: Delivers the completed report to defined recipient lists on schedule via email, with embedded highlights and exception summaries for executives who need the key takeaways without reading the full document
- Trend and pattern analysis: Identifies multi-period patterns in financial performance that point-in-time variance reports miss, surfacing emerging trends that warrant strategic attention beyond the current period's results
Standout Features
- Variance interpretation engine: Rather than presenting raw variance numbers and leaving interpretation to the reader, the agent generates the contextual explanations that turn deviations into insights, mimicking the analytical reasoning a senior finance analyst would apply
- Multi-entity consolidation: Handles the complexity of multi-location, multi-segment financial reporting where entity-level detail must roll up to consolidated views while maintaining the drill-down capability that location managers need
- Materiality-aware filtering: Automatically applies configurable materiality thresholds to focus executive attention on variances that matter, preventing the information overload that makes manual reports difficult to act on
- Commentary consistency tracking: Maintains narrative continuity across reporting periods, referencing previous period commentary when the same variance persists and flagging when previously explained deviations resolve or reverse
- Adaptive learning from corrections: When finance team members edit the agent's commentary before distribution, those edits refine the agent's future analytical approach, progressively improving alignment with the team's interpretive standards
Who This Agent Is For
This agent is designed for finance teams at multi-location enterprises where recurring financial reporting is both critical and disproportionately time-consuming relative to the assembly nature of the work.
- FP&A teams producing weekly, monthly, or quarterly variance reports for executive leadership who need faster delivery without sacrificing analytical depth or interpretive quality
- Finance directors managing reporting across dozens or hundreds of cost centers, locations, or business units where the volume of line items exceeds what manual analysis can handle consistently
- Controllers responsible for ensuring methodological consistency across reporting periods who need automated enforcement of computation standards and presentation formats
- CFO offices that need financial intelligence delivered at the speed of data availability rather than the speed of manual report assembly
Ideal for: Multi-location fitness and hospitality brands, retail chains, healthcare systems, franchise networks, and any enterprise where financial complexity spans dozens of entities and the cost of delayed financial insight compounds with every day between data availability and report delivery.

Marketing Report AI Agent
AI agent that automates the generation and distribution of recurring marketing governance reports, replacing a 20-hour-per-week manual process with AI-powered analysis that queries live data, produces formatted insights, and delivers them to the full team automatically.
Twenty hours every week. That is how long the marketing governance team spent manually building one recurring report. The data existed. The format was defined. The audience was consistent. Yet a human had to assemble it from scratch every single time.
The Marketing Report AI Agent emerged from a straightforward operational pain point at a global technology company operating across 180+ markets. Their Marketing Governance Team produced a highly specific recurring report distributed to 60 people. The report required pulling data from multiple sources, analyzing trends against defined governance criteria, formatting the results into a standardized structure, and distributing it to the full recipient list. This was not complex analytical work. It was assembly work. But it consumed 20 hours of skilled team capacity every week because no existing tool could handle the specific combination of data querying, contextual analysis, and formatted output that the report required. The team went through approximately 10 iterations of prompt refinement to get the agent producing reports that matched their exact specifications.
Benefits
This agent eliminates the single largest recurring time drain on the governance team, converting manual report assembly into an automated process that runs with consistency no human workflow can match.
- 20 hours per week recovered: The team's most expensive recurring manual process is eliminated entirely, freeing skilled marketers to focus on the strategic governance work that actually requires human judgment
- Consistent report quality: Every report follows the same analytical structure and formatting standards regardless of who is on the team that week, eliminating the quality variance that comes with manual production across different analysts
- Expanded distribution reach: With production cost reduced to near zero, the report can reach its full 60-person audience without the implicit pressure to limit distribution that exists when every additional recipient increases the perceived burden of production
- Faster time to insight: Reports that previously required days of manual assembly are produced in minutes, shifting the governance team's review cadence from retrospective analysis to near-real-time monitoring
- Reduced key-person dependency: The report no longer depends on the specific analyst who knows how to pull the data and format it correctly, eliminating the single point of failure that previously caused delays during vacations or role transitions
- Iterative refinement capability: The agent's prompt-based configuration means the report format, content emphasis, and analytical focus can be adjusted through natural language instructions rather than requiring development cycles
Problem Addressed
Marketing governance teams at large enterprises face a particular operational burden that technology has not traditionally addressed well. Their reports are too specific for generic BI dashboards, too data-heavy for simple email summaries, and too recurring to justify custom development for each one. The result is manual assembly: an analyst queries the data, interprets it through the lens of governance criteria, writes up the findings in the required format, and sends it out. For a weekly report, this is a weekly tax on team capacity. For a daily report, it would be unsustainable.
The deeper problem is the specificity requirement. Marketing governance reports are not generic performance dashboards. They measure compliance against specific standards, track initiatives against specific timelines, and evaluate activities against specific criteria that the governance team defines and updates. Off-the-shelf reporting tools can surface the underlying data, but they cannot apply the contextual interpretation layer that turns raw metrics into governance insights. The team tried automating with traditional tools and found that the output required so much manual editing that the time savings were negligible. The AI-powered approach succeeded where previous attempts failed because the agent could be trained through iterative prompt refinement to produce output that matched the team's specific analytical voice and governance framework.
What the Agent Does
The agent operates as a complete report production pipeline, from data querying through analysis to formatted distribution, replicating the workflow that previously consumed 20 hours of manual effort:
- Automated data querying: Connects to the organization's data infrastructure to pull the specific metrics, dimensions, and time periods required for each report cycle without manual data extraction or export steps
- Governance-context analysis: Applies the team's defined governance criteria to the queried data, identifying compliance status, trend deviations, and areas requiring attention using the same analytical framework the team applies manually
- Formatted report generation: Produces the complete report in the team's established format, including section headers, metric summaries, trend commentary, and action items that match the structure the 60-person audience expects
- Automated distribution: Delivers the completed report to the full recipient list via email on the defined schedule, including any attachments or embedded visualizations the format requires
- Exception highlighting: Surfaces the most significant findings, deviations, and action items at the top of the report so busy recipients can identify what requires their attention without reading the full document
- Historical comparison: Includes period-over-period comparisons that show how current governance metrics have changed relative to previous reporting periods, providing the trend context that static snapshots cannot convey
Standout Features
- Prompt-trained precision: Through approximately 10 iterations of prompt refinement, the agent learned the team's specific analytical voice, governance framework, and formatting preferences, producing output that reads as if the team's best analyst wrote it
- Natural language configurability: Report modifications, emphasis changes, and new section additions are accomplished through conversational instruction rather than tool reconfiguration, giving the governance team direct control over report evolution
- Zero-lag distribution: Reports are generated and distributed within minutes of the data being available, eliminating the multi-day lag between data readiness and report delivery that characterized the manual process
- Embedded analytical intelligence: The agent does not just format data into tables. It applies contextual interpretation, identifies the story the data tells, and highlights the governance implications that require human decision-making
Who This Agent Is For
This agent is designed for marketing teams at large enterprises where recurring report production consumes disproportionate analyst capacity relative to the strategic value of the assembly work itself.
- Marketing governance teams responsible for producing compliance, performance, or standards-adherence reports on recurring schedules for large internal audiences
- Marketing operations analysts who spend significant weekly hours on report assembly that follows a consistent format but requires contextual data interpretation
- Marketing leadership who need their teams focused on governance strategy and action rather than report production mechanics
- Enterprise organizations where report distribution reaches dozens of stakeholders and production delays create cascading impacts on decision-making timelines
Ideal for: Global technology companies, financial services firms, healthcare enterprises, and any large organization where marketing governance reporting is a recurring, time-intensive process that follows consistent formats but requires more contextual intelligence than standard BI dashboards can provide.

RFP Calendar Management AI Agent
Custom pro-code calendar application that provides an at-a-glance visual view of all active and simultaneous RFPs, replacing fragmented project management tools with purpose-built priority management for high-volume proposal operations.
Thirty-seven active RFPs. Twelve due this month. And the team is managing them in a project tool that was never designed to show you which proposals overlap, which deadlines conflict, and which ones are about to slip.
A major health benefits company serving millions of members manages one of the most demanding RFP operations in the insurance industry. During peak season, dozens of proposals run simultaneously, each with its own timeline, submission deadline, review stages, and team assignments. The team had been using general-purpose project management tools to track these proposals, but the tools lacked a critical capability: a visual, calendar-based view that showed all active RFPs simultaneously with their timelines, overlaps, and status. What they needed was not another project board or task list. They needed a purpose-built calendar that showed, at a single glance, the full picture of what was in flight, what was coming, and what was at risk.
Benefits
This application replaces the mental model that RFP managers carry around in their heads with a visual system that makes the full scope, timing, and status of the proposal pipeline immediately obvious to everyone who needs to see it.
- Complete pipeline visibility: Every active and upcoming RFP is visible on a single calendar view with timeline bars, status indicators, and deadline markers, replacing the fragmented view that required opening multiple project boards, spreadsheets, and email threads to assemble the same picture mentally
- Overlap and conflict detection: When multiple RFPs share overlapping timelines, the calendar makes this immediately visible, enabling proactive resource allocation and deadline management rather than discovering conflicts when teams are already stretched thin
- Nothing slips through the cracks: The visual format ensures that every proposal is represented and every deadline is visible, eliminating the scenario where a lower-profile RFP is forgotten because it did not appear on the task list that the manager happened to be reviewing
- Faster priority decisions: When a new RFP arrives or a deadline changes, the calendar immediately shows its relationship to everything else in the pipeline, making priority trade-off decisions visual and informed rather than abstract and memory-dependent
- Improved team coordination: Shared calendar visibility means that team leads, writers, subject matter experts, and reviewers all see the same view of what is due when, reducing the communication overhead of keeping everyone aligned on the pipeline state
- Process clarity from chaos: What was previously a fragmented set of tools, spreadsheets, and tribal knowledge becomes a single, authoritative view of the entire RFP operation that brings immediate clarity to a process that felt chaotic during peak volume periods
Problem Addressed
Anyone who has managed a high-volume RFP operation knows the feeling. It is the second week of the quarter, and the pipeline has twenty-eight active proposals. Six are in the writing phase. Four are in internal review. Three are waiting on subject matter expert input. Two have client-modified deadlines that arrived this morning. And one that was supposed to be low priority just became the CEO's top concern because the prospect represents a strategic account. The project management tool shows all of this as a list of tasks with due dates. What it does not show is the shape of the next thirty days: which weeks are dangerously overloaded, which proposals compete for the same writers, and which upcoming RFPs are going to collide with the ones already in progress.
General-purpose project management tools are designed for task management, not for the specific visual challenge of managing dozens of concurrent, time-bounded proposal efforts. They show you what is due next. They do not show you the landscape. A list view with twenty-eight rows of tasks cannot communicate the same information as a calendar where you can see that the week of the 15th has seven submissions due while the week of the 22nd has two, and that the SME who is assigned to three of those seven is already committed to an internal deadline on the 14th. The absence of this visual layer does not just create inconvenience. It creates risk. Proposals slip because the team could not see the collision coming. Priority decisions are made without understanding the full context. And the RFP manager's most valuable asset, the mental model of the entire pipeline, walks out the door at the end of every day.
What the Agent Does
The application provides a purpose-built calendar interface designed specifically for the requirements of high-volume RFP management, showing the complete proposal pipeline with the visual context needed for effective priority and resource management:
- Timeline-based calendar view: Displays all active and upcoming RFPs as timeline bars on a calendar, with each proposal's start date, key milestones, and submission deadline visible in a single view that shows the full shape of the pipeline across weeks and months
- Status visualization: Each RFP carries visual status indicators showing its current phase, such as drafting, internal review, SME input, client revision, final review, or submitted, making the aggregate pipeline state immediately readable without opening individual proposals
- Resource overlap detection: Highlights periods where assigned team members have overlapping commitments across multiple proposals, surfacing resource conflicts that are invisible in task-based project views
- Deadline clustering alerts: Identifies periods where submission deadlines are concentrated, providing advance warning of high-load weeks that require proactive resource planning or deadline negotiation
- Filtering and segmentation: Allows the calendar view to be filtered by team, status, priority, client segment, or proposal size, enabling focused views for different management contexts without losing the ability to see the complete picture
- Integration with existing data: Pulls RFP data from existing systems of record, ensuring the calendar reflects the current state without requiring duplicate data entry into a separate tool
Standout Features
- Purpose-built for proposal operations: Unlike adapted project management tools, every element of the calendar interface is designed for the specific visual and informational needs of managing concurrent proposals with overlapping timelines and shared resources
- At-a-glance pipeline shape: The calendar communicates the density, distribution, and status of the entire pipeline in a visual format that the human brain processes faster than any list, table, or dashboard of numbers could convey
- Pro-code flexibility: Built as a custom pro-code application rather than a no-code configuration, enabling the precise UX design and interaction patterns that high-volume RFP teams need, including custom timeline rendering, drag interactions, and responsive filtering
- Multi-horizon view: The calendar supports week, month, and quarter views, allowing managers to zoom from tactical daily planning to strategic quarterly capacity assessment without switching tools or contexts
- Audit trail for timeline changes: Every deadline change, status update, and priority adjustment is logged, creating a historical record that supports post-season process reviews and client communication about timeline modifications
Who This Agent Is For
This application is designed for organizations where RFP volume is high enough that managing proposals through general-purpose project tools creates visibility gaps, priority confusion, and deadline risk.
- RFP operations managers at insurance, healthcare, government contracting, or professional services firms who manage twenty or more concurrent proposals during peak periods
- Proposal writers and coordinators who need to understand their workload distribution across the coming weeks without manually reviewing multiple project boards and spreadsheets
- Sales and business development leaders who need visibility into proposal pipeline capacity to make informed decisions about which opportunities to pursue
- Resource managers responsible for allocating writers, SMEs, and reviewers across concurrent proposals and who need a visual tool to identify conflicts and gaps
- Executive sponsors who need a quick, visual answer to the question of what the proposal pipeline looks like right now without requesting a custom report
Ideal for: RFP directors, proposal managers, bid coordinators, sales operations leaders, and any organization where the number of simultaneous proposals has outgrown the visual and organizational capacity of general-purpose project management tools.

Demand Forecasting AI Agent
AI agent that analyzes historical weather data against forecasts to predict regional demand surges for service businesses, automatically sending proactive email alerts to regional teams so they can staff up and stock parts before peak periods hit.
When a heat wave hits, every HVAC company in the region gets the same flood of service calls. The ones that staffed up three days earlier are the ones that keep their customers.
The Demand Forecasting AI Agent was built for service organizations where external conditions drive demand in patterns that are predictable if you have the right data and the right lead time. A collection of residential and commercial HVAC, electrical, and plumbing companies operating across the United States faced a recurring crisis: extreme weather events created massive, sudden demand spikes for their services. During heat waves, emergency AC repair calls surged by 300% or more. During cold snaps, heating system failures flooded their dispatch queues. The demand itself was not surprising. What was damaging was the reactive response. Parts ran out. Technicians were overbooked by mid-morning. Customers waited days for service that competitors were already providing because those competitors had somehow anticipated the surge.
Benefits
This agent converts publicly available weather data into a competitive advantage, giving operations teams the lead time they need to meet demand surges rather than react to them.
- Proactive staffing decisions: Regional managers receive demand surge predictions days in advance, giving them time to schedule additional technicians, approve overtime, or bring in contract labor before the phone starts ringing
- Parts and inventory readiness: Predicted demand increases trigger inventory checks and pre-positioning of high-demand parts at the regional level, preventing the stockout situations that force technicians to make return visits
- Customer service preservation: Meeting demand surges on day one rather than day three directly reduces customer wait times, prevents the negative reviews that accumulate during service delays, and retains customers who would otherwise call a competitor
- Revenue capture during peak periods: Peak demand periods represent the highest-margin service windows. Being staffed and supplied to capture that demand rather than turning it away because of capacity constraints directly impacts quarterly revenue
- Reduced emergency operations costs: Planned surge response is significantly cheaper than emergency scrambling, as overtime approved in advance costs less operationally than last-minute dispatch changes and expedited parts shipping
- Regional performance equity: Every region receives the same data-driven advance warning, eliminating the performance gap between regions with experienced managers who watch the weather and regions where newer managers operate reactively
Problem Addressed
Service businesses with weather-dependent demand operate in a paradox. Their busiest periods are their most profitable periods, but those same periods are when they are most likely to fail their customers. A residential HVAC company during a summer heat wave faces exponential demand growth with fixed labor capacity. The company that had 15 technicians available on Monday needs 45 by Wednesday. Parts that normally last a week of inventory are gone by noon. Customers call, hear a three-day wait time, and call the next company in their search results. The revenue walks out the door not because the demand did not exist but because the organization could not respond fast enough.
The irony is that this demand is not unpredictable. Weather forecasts are available five to seven days in advance. Historical data clearly shows the correlation between temperature extremes and service call volume. Every experienced regional manager knows that a week of extreme forecasts means their phone will not stop ringing. But translating that institutional knowledge into systematic, pre-emptive operational action across dozens of regions requires infrastructure that most service organizations lack. The regional manager in Phoenix who has twenty years of experience prepares automatically. The new regional manager in Dallas does not. The result is inconsistent customer experience and inconsistent revenue capture across the network, driven not by market conditions but by the gap between available data and operational response.
What the Agent Does
The agent operates as a predictive operations intelligence layer, connecting weather data to historical demand patterns and converting the analysis into actionable alerts for regional decision-makers:
- Weather forecast ingestion: Continuously monitors multi-day weather forecasts across all operating regions, tracking the temperature extremes, precipitation events, and weather pattern changes that historically correlate with demand surges
- Historical pattern correlation: Analyzes years of historical service call data alongside corresponding weather conditions to build region-specific models of how weather patterns translate into demand changes
- Regional demand prediction: Generates quantified demand increase predictions for each operating region based on the incoming weather forecast, expressed as expected percentage increases in service call volume
- Automated email alerting: Sends structured alert emails to regional managers and staffing coordinators with the predicted demand increase, the weather conditions driving it, and the timeframe the surge is expected to cover
- Staffing recommendation generation: Translates demand predictions into specific staffing recommendations based on each region's current capacity, technician availability, and historical service completion rates
- Post-event accuracy tracking: Compares predicted demand surges against actual outcomes to continuously refine the correlation models and improve future prediction accuracy across all regions
Standout Features
- Region-specific correlation models: Rather than applying a single national model, the agent builds distinct demand-weather correlations for each operating region, reflecting the reality that a 95-degree day in Phoenix drives different demand than a 95-degree day in Minneapolis
- Multi-day lead time optimization: Alerts are timed to give operational teams maximum lead time for the type of response required, distinguishing between situations that need staffing adjustments versus those that need both staffing and parts pre-positioning
- Compound event detection: The agent identifies when multiple weather factors combine to amplify demand beyond what any single factor would predict, such as a heat wave following a week of storms that caused deferred maintenance
- Continuous accuracy refinement: Every weather event becomes a training data point, with the agent automatically comparing its predictions against actual demand outcomes and adjusting regional models to improve future forecast precision
Who This Agent Is For
This agent is designed for service organizations where weather conditions are a primary demand driver and where the ability to anticipate demand surges by even two or three days creates meaningful operational and financial advantages.
- Regional operations managers responsible for technician scheduling and capacity planning who need advance warning of demand surges to avoid customer service failures from reactive staffing
- Staffing coordinators managing technician availability across multiple service territories who need data-driven inputs for overtime approval and contractor scheduling
- Supply chain managers responsible for parts inventory positioning who need regional demand signals to pre-stage high-demand components before surge events deplete stock
- Service business executives building competitive advantage through superior surge response capability across their operating network
Ideal for: HVAC service networks, plumbing and electrical contractors, roofing companies, pest control services, emergency restoration firms, and any service business where weather is the single largest demand variable and proactive positioning directly determines customer capture rates during peak periods.

Saved Search to SuiteQL AI Agent
AI agent that automatically translates complex NetSuite saved search criteria and filters into optimized SuiteQL queries, enabling organizations to reduce dependence on costly native saved searches by converting existing logic into native connector queries.
50% reduction in NetSuite saved search costs. Queries that run 10x faster through native connectors. Zero manual SQL translation effort. These outcomes start the moment the first saved search is converted.
A private investment and holding company managing a portfolio of mid-sized businesses across manufacturing, distribution, and services sectors faced a growing ERP cost problem. Every subsidiary operated on NetSuite, and every one relied heavily on saved searches to extract the operational and financial data that powered their analytics, reporting, and decision-making. Saved searches were the default tool because they were familiar. Business analysts, controllers, and operations managers could build them through the NetSuite interface without writing code. But that convenience came at a cost that scaled with usage: each saved search consumed NetSuite processing resources, contributed to governance limits, and created performance bottlenecks during peak reporting periods when dozens of saved searches executed simultaneously.
The Saved Search to SuiteQL AI Agent was deployed to convert existing saved search logic into optimized SuiteQL queries that run through the SuiteAnalytics Connector. The results were immediate and measurable: lower NetSuite compute costs, faster query execution, reduced governance limit pressure, and a growing library of optimized queries that analysts could use as templates for future data extraction needs. The conversion does not require analysts to learn SuiteQL. They input their existing saved search criteria, and the agent outputs a production-ready query that delivers the same results through a more efficient path.
Benefits
This agent delivers measurable cost reduction and performance improvement from the first conversion, with benefits that compound as more saved searches are migrated to native queries.
- Immediate cost reduction: Each saved search converted to SuiteQL reduces NetSuite processing costs by running through the SuiteAnalytics Connector rather than consuming saved search execution resources during peak periods
- 10x query performance improvement: SuiteQL queries optimized by the agent execute through the native connector with dramatically faster response times than equivalent saved searches, especially for complex multi-table joins and large dataset extractions
- Zero SQL knowledge required: Analysts input their existing saved search criteria using the familiar field names, filters, and formulas they already know, and receive production-ready SuiteQL without writing or understanding a single line of SQL
- Governance limit relief: Migrating high-frequency saved searches to SuiteQL reduces the saved search execution count that contributes to NetSuite governance limits, freeing capacity for searches that genuinely require the saved search engine
- Portable query library: Converted SuiteQL queries work with any SQL-compatible analytics tool, reducing vendor lock-in and enabling the same data extraction logic to feed multiple downstream systems through the SuiteAnalytics Connector
- Standardized data extraction: AI-optimized queries follow consistent naming conventions, join patterns, and filter structures, creating a maintainable query library rather than the ad-hoc collection of saved searches that accumulated over years of individual creation
Problem Addressed
NetSuite saved searches are the default data extraction tool for a reason: they are accessible. Any business user can build one through the UI. They can add filters, choose columns, create formulas, and run the search without understanding the underlying data model. This accessibility is their greatest strength and the source of their greatest cost. Organizations that depend on saved searches for their analytics and reporting needs accumulate hundreds of them over time. Each one consumes execution resources. Many are scheduled to run automatically at intervals. Some are duplicates or near-duplicates created by different users who did not know the other's search existed. During month-end close, quarter-end reporting, and annual planning cycles, the cumulative load from simultaneous saved search execution creates performance degradation that affects every NetSuite user in the organization.
The alternative to saved searches is SuiteQL, a SQL-based query language that runs through the SuiteAnalytics Connector with better performance characteristics and lower resource consumption. But SuiteQL requires SQL knowledge. The analysts, controllers, and operations managers who built the saved searches in the first place chose that tool precisely because they did not know SQL. Asking them to rewrite their logic in a query language they do not understand is not a realistic migration strategy. The organization is stuck between a tool that is accessible but expensive, and a tool that is efficient but inaccessible. The Saved Search to SuiteQL AI Agent resolves this by making the efficient tool accessible without requiring anyone to learn SQL.
What the Agent Does
The agent translates saved search logic into optimized SuiteQL queries through an automated conversion pipeline that handles the full complexity of saved search criteria:
- Saved search criteria ingestion: Users input their existing saved search configuration including selected fields, filter criteria, formulas, sort orders, and summary groupings, using the same field names and filter operators they use in the NetSuite saved search builder
- Schema mapping and table resolution: The agent maps saved search field references to the corresponding SuiteQL table names, column names, and join paths, resolving the abstraction layer that the saved search UI provides over the underlying data model
- Filter and formula translation: Saved search filters, including nested AND/OR logic, formula-based criteria, and multi-select lookups, are translated into equivalent SuiteQL WHERE clauses with proper parameterization and type handling
- Query optimization: The generated SuiteQL is optimized for execution performance, including efficient join ordering, selective column projection, appropriate index utilization, and filter push-down to minimize the data processed by each query
- Validation and result comparison: The agent validates the generated query against the SuiteAnalytics schema and can execute both the original saved search and the converted query to compare results, confirming functional equivalence before the migration is finalized
- Query library management: Converted queries are stored in an organized library with documentation including the original saved search reference, conversion date, owning team, execution schedule, and downstream consumers
Standout Features
- Formula-to-SQL expression engine: The agent converts NetSuite saved search formulas including CASE statements, date functions, NVL expressions, and custom calculations into equivalent SuiteQL expressions, handling the syntax differences that make manual conversion error-prone
- Join path optimization: Multi-table queries are constructed with optimal join paths through the NetSuite data model, avoiding the redundant joins that saved searches sometimes generate when fields are selected from related records
- Governance impact estimation: Before and after governance metrics are projected for each conversion, showing the expected reduction in saved search execution units and the corresponding relief on governance limits
- Incremental migration planning: The agent analyzes the full saved search inventory, prioritizes candidates for conversion based on execution frequency, resource consumption, and conversion complexity, and produces a phased migration plan
- Connector-ready output: Generated queries include the configuration metadata needed to deploy them directly through the SuiteAnalytics Connector, including authentication parameters, scheduling options, and output format specifications
Who This Agent Is For
This agent is designed for NetSuite organizations where the accumulated cost and performance impact of saved searches has become a material concern, but the user base lacks the SQL expertise to migrate to SuiteQL manually.
- Finance and analytics teams running dozens or hundreds of saved searches that contribute to governance limit pressure and performance degradation during peak reporting periods
- IT and data teams responsible for NetSuite administration who need to reduce saved search costs without disrupting the business users who depend on those searches
- Private equity portfolio companies standardizing ERP data extraction across multiple subsidiaries operating on NetSuite
- Business analysts and controllers who want the performance benefits of SuiteQL without learning SQL or understanding the SuiteAnalytics data model
- Data engineering teams building analytics pipelines that would benefit from SQL-based extraction through the SuiteAnalytics Connector rather than saved search API calls
Ideal for: NetSuite administrators, data architects, finance controllers, analytics leads, and IT directors at organizations running 100+ saved searches where the cumulative cost of saved search execution, governance limit pressure, and query performance degradation justifies a systematic migration to SuiteQL that does not require retraining the user base.

POS Monitoring AI Agent
AI agent that proactively monitors point-of-sale data across a retail distribution network, detects week-over-week and year-over-year variance threshold breaches in sales and inventory, and automatically alerts POS owners when customers fall outside defined performance parameters.
By the time someone notices a retail partner's sales dropped 40% week-over-week, the damage is already done. The product sat on shelves. The promotional window closed. The reorder was never placed.
The POS Monitoring AI Agent exists because the gap between something going wrong at a retail point of sale and someone on the brand side noticing it is where revenue disappears. A creative technology company selling through a network of retail partners and direct-to-consumer channels built this agent after recognizing that their POS reporting was fundamentally reactive. Reports were generated on schedule. Analysts reviewed them when they could. Anomalies were spotted weeks after they occurred. By then, the questions were forensic rather than operational: why did sales drop at this retailer three weeks ago? The answer did not matter as much as the fact that nobody knew it was happening when it was happening.
Benefits
This agent shifts POS management from scheduled reporting to continuous monitoring, converting data latency into decision-making speed where it matters most.
- Proactive anomaly detection: Variance breaches in sales and inventory are identified automatically as data refreshes, not when someone opens a report days or weeks later and notices something looks off
- Threshold-based intelligence: The agent operates on defined parameters rather than requiring human interpretation of every data point, focusing attention only on the exceptions that exceed acceptable variance ranges
- Automated owner notification: POS account owners receive email alerts with specific exception details the moment thresholds are breached, eliminating the relay chain of analyst-to-manager-to-owner that introduces days of delay
- Dual-timeframe analysis: Week-over-week variance catches sudden drops or spikes, while year-over-year comparison filters out seasonal patterns and highlights true performance deviations that require intervention
- Reduced analytical overhead: Instead of analysts manually scanning performance data across the entire retail network, the agent surfaces only the accounts that need attention, freeing the team for strategic account management
- Decision documentation: Every alert includes the variance calculation, threshold definition, and historical context needed to make an immediate decision, replacing the research time that previously preceded every action
Problem Addressed
Retail brand teams managing distribution networks live in a world where the data exists to catch problems early but the processes do not. A brand selling through 200 retail partners has 200 sets of sales and inventory metrics updating at different intervals. Weekly reports aggregate this data into dashboards that show regional trends and top-line numbers. What those dashboards do not do is tap someone on the shoulder and say: this partner just had a significant sales drop that your standard seasonal models do not explain, and their inventory levels suggest they stopped reordering your product two weeks ago.
The human cost of this gap is significant. Analysts spend hours combing through partner-level data looking for anomalies they may or may not find. Account managers learn about problems from their retail contacts rather than from their own data systems. When an issue is finally identified, the response is investigative rather than preventive. The team reconstructs what happened instead of intervening while it is happening. For products with seasonal sales cycles, promotional windows, or inventory-sensitive demand patterns, even a one-week delay in detecting a variance can mean the difference between corrective action and a lost quarter at that retail partner.
What the Agent Does
The agent operates as a continuous POS surveillance system, processing sales and inventory data through variance calculations and threshold rules to surface actionable exceptions:
- Automated variance calculation: Computes week-over-week and year-over-year variance for every customer and product combination in the POS dataset, maintaining rolling baselines that account for expected fluctuations
- Threshold exception detection: Evaluates each variance result against configurable threshold parameters, identifying the specific customer-product combinations where performance has deviated beyond acceptable ranges
- Exception customer identification: Isolates the specific retail partners or accounts responsible for threshold breaches, providing account-level specificity rather than aggregate alerts that require further investigation
- Automated email alerting: Generates and sends exception reports to designated POS owners with full context including the variance metrics, threshold that was breached, historical comparison data, and affected product lines
- Decision tree documentation: Includes recommended response actions based on the type and severity of the variance detected, aligning alert content with the organization's established response protocols
- Historical pattern analysis: Maintains a running history of threshold breaches per customer to identify chronic underperformers versus one-time anomalies, helping the team prioritize sustained intervention over reactive firefighting
Standout Features
- Dual-horizon variance engine: Simultaneous WoW and YoY analysis ensures that both sudden disruptions and slow degradation patterns are caught, preventing the common blind spot where gradual declines go unnoticed because no single week looks alarming
- Configurable threshold architecture: Different product lines, regions, and account tiers can operate under different threshold parameters, reflecting the reality that a 10% variance for a major retail partner warrants different urgency than the same percentage at a small independent retailer
- Self-documenting alert workflow: Every alert includes not just the anomaly data but the decision framework for responding to it, so POS owners can act immediately rather than spending time determining what the appropriate response should be
- Exception trend tracking: The agent maintains a longitudinal view of which accounts trigger exceptions repeatedly, surfacing the chronic performance issues that point-in-time reports consistently miss
Who This Agent Is For
This agent is designed for brands and manufacturers that sell through retail distribution networks where POS performance visibility directly impacts revenue management and partner relationship health.
- Sales operations teams managing dozens or hundreds of retail partner relationships who cannot manually monitor every account's POS performance at the frequency required to catch problems early
- Channel managers responsible for retailer performance who need to know within days, not weeks, when a partner's sales or inventory behavior changes significantly
- Demand planning teams that rely on POS sell-through data to forecast production and inventory allocation across the distribution network
- Brand executives who need confidence that anomalies in the retail network are being detected and addressed proactively rather than discovered during quarterly business reviews
Ideal for: Consumer electronics companies, CPG brands, sporting goods manufacturers, and any organization selling through a distributed retail network where POS variance detection speed directly correlates to revenue protection and partner relationship management.
Operations Workflow AI Agent
Suite of intelligent AI agents that streamline complex operational workflows across automotive and enterprise operations, providing intuitive interfaces that drive strong technology adoption rates by making daily tasks simpler for operations teams and staff.
You deploy a new technology platform. Nobody uses it. Not because they do not want to, but because the workflows are too complex for anyone to figure out during a busy workday.
A global automotive services and technology provider with over 25,000 employees across five continents knew this pattern well. The organization operated some of the most recognized brands in the automotive industry, powering vehicle marketplaces, pricing services, wholesale auction platforms, and dealer technology solutions. They had invested significantly in technology platforms designed to improve operational efficiency across their diverse business units. The platforms were powerful. The data was comprehensive. And adoption was disappointing. Not because the technology did not work, but because the gap between what the platforms could do and what busy operations staff could figure out how to do was too wide.
The Operations Workflow AI Agent was built to close that gap. Rather than asking operations teams to learn complex platform interfaces, the agent provides intelligent automation that handles the complexity behind a simple, intuitive interaction layer. Staff describe what they need in plain language. The agent translates that into the multi-step workflow that the underlying platforms require. The result is not just automation. It is adoption. When technology becomes easy to use, people use it. When people use it, the efficiency gains that justified the investment actually materialize.
Benefits
This agent solves the adoption problem that undermines most enterprise technology investments, delivering operational efficiency by making complex workflows accessible to frontline staff.
- Dramatic adoption rate improvement: Technology utilization increased significantly across operations teams because the AI interface eliminated the learning curve that previously prevented staff from engaging with powerful but complex platform capabilities
- Operational task completion acceleration: Multi-step workflows that required navigating multiple screens, entering data in specific sequences, and coordinating across systems are compressed into single conversational interactions that complete in a fraction of the time
- Reduced training investment: New staff become productive with operational technology faster because the AI agent guides them through processes rather than requiring them to memorize interface navigation and workflow sequences
- Consistent process execution: The agent enforces correct workflow sequences, required approvals, and data validation rules that manual execution frequently skipped under time pressure, improving process quality across the operation
- Cross-platform coordination: Tasks that previously required logging into multiple systems, copying data between them, and manually synchronizing state are handled by the agent as unified workflows that coordinate across platforms transparently
- Captured institutional knowledge: The agent embeds operational expertise from top performers into automated workflows, making expert-level process execution available to every team member regardless of their individual experience level
Problem Addressed
Enterprise technology adoption follows a predictable failure pattern. The organization purchases or builds a platform with comprehensive capabilities. Training sessions are conducted. Documentation is distributed. And then the reality of daily operations takes over. Staff are busy. The platform is complex. The training was three weeks ago and covered twenty features, of which they need four but cannot remember which screens they are on. So they fall back to the process they know: the spreadsheet, the email, the phone call, the workaround that takes longer but does not require them to figure out a new interface while a customer is waiting or a deadline is approaching.
The automotive services industry experiences this pattern acutely because of its operational diversity. Dealer network staff, auction operations personnel, data services analysts, and technology support teams all need to interact with operational platforms, but they have different technical skill levels, different daily workflows, and different tolerance for learning new interfaces. A solution that works for a technically sophisticated data analyst fails for a dealer operations coordinator who uses the platform twice a week. The result is a technology investment that delivers value to the subset of users who were already comfortable with complex interfaces, while the majority of the intended user base continues using manual alternatives. The problem is not the technology. It is the interface between the technology and the humans who are supposed to use it.
What the Agent Does
The agent provides an intelligent interface layer that translates simple user requests into complex, multi-step operational workflows executed across enterprise platforms:
- Natural-language task initiation: Operations staff describe what they need to accomplish in plain language rather than navigating through platform menus and screens, with the agent interpreting intent and mapping it to the appropriate workflow
- Multi-step workflow orchestration: The agent executes complex sequences that span multiple platforms, including data retrieval, validation checks, approval routing, record creation, and notification distribution, presenting the result as a single completed action
- Context-aware guidance: When user requests are ambiguous or incomplete, the agent asks targeted clarifying questions rather than producing errors, guiding users through the decision points that the workflow requires without overwhelming them with options
- Cross-system data coordination: The agent synchronizes data across CRM, operations, and transaction platforms, handling the integrations that previously required manual data entry in multiple systems to keep records consistent
- Approval workflow management: Requests that require management approval are automatically routed through the correct chain with all supporting context attached, tracked through the approval process, and acted upon immediately when approved
- Process analytics and optimization: The agent tracks workflow execution patterns, identifies bottlenecks, and surfaces optimization opportunities based on actual usage data rather than theoretical process designs
Standout Features
- Role-adaptive complexity: The agent adjusts its interaction style based on the user's role and demonstrated technical comfort, providing more guidance and confirmation steps for occasional users while offering streamlined shortcuts for power users
- Embedded expert logic: Operational best practices and decision rules from experienced staff are encoded into the agent's workflow logic, ensuring that every user benefits from institutional expertise regardless of their individual experience
- Progressive disclosure interface: Users see only the information and options relevant to their current step, preventing the cognitive overload that complex platform interfaces create when they display all capabilities simultaneously
- Offline-capable queue processing: When connectivity to underlying platforms is interrupted, the agent queues actions and executes them when systems are available, preventing workflow interruptions during system maintenance or network issues
- Adoption analytics dashboard: Real-time visibility into agent usage patterns, workflow completion rates, and user adoption trends gives technology leaders the data needed to measure ROI and identify opportunities to expand automation coverage
Who This Agent Is For
This agent is designed for enterprise operations where powerful technology platforms are underutilized because the gap between platform complexity and daily user needs prevents consistent adoption.
- Operations teams at automotive, manufacturing, and enterprise services companies where frontline staff interact with complex platforms as part of their daily workflow
- Technology leaders who have invested in powerful platforms but are seeing adoption rates below expectations because of interface complexity and learning curve barriers
- Dealer network operations where distributed staff with varying technical skills need to execute consistent processes across shared platforms
- Sales and service teams whose productivity depends on multi-system coordination that is currently handled through manual data entry and copy-paste workflows
- Enterprise IT departments seeking to improve platform ROI by increasing utilization without requiring additional rounds of training and change management
Ideal for: Operations directors, technology executives, dealer network managers, enterprise architects, and any organization where the gap between technology capability and technology adoption represents unrealized operational efficiency that AI-driven simplification can unlock.

Governance & Bottleneck Optimization AI Agent
AI agent that automates employee on/off-boarding governance workflows and analyzes manufacturing plant bottlenecks to recommend strategic equipment purchases, combining compliance automation with Python-driven schedule optimization.
When governance tasks pile up and plant bottlenecks go undiagnosed, the costs compound silently. Delayed offboarding creates security exposure. Unoptimized production lines burn capital on the wrong equipment.
The Governance and Bottleneck Optimization AI Agent was designed for contract manufacturing organizations where two distinct operational challenges converge: managing the compliance-heavy processes of employee lifecycle governance and optimizing production throughput on precision manufacturing lines. A medical device contract manufacturer faced both problems simultaneously. Their on/off-boarding workflows required coordination across IT, HR, compliance, and facility access systems. Every delayed offboarding represented a potential audit finding. Meanwhile, their production floor operated with bottlenecks that were understood anecdotally by shift supervisors but never quantified systematically. Equipment purchase decisions were made based on intuition rather than data-driven analysis of where throughput constraints actually existed.
Benefits
This agent delivers measurable improvements across two operational domains that traditionally require separate tooling and separate teams to manage.
- Automated governance compliance: On/off-boarding workflows execute consistently every time, eliminating the human variability that leads to missed steps, delayed access revocation, and audit findings during compliance reviews
- Reduced security exposure: Automated offboarding ensures that departing employees lose system access, badge access, and credential privileges within defined SLAs rather than lingering for days or weeks in manual queues
- Data-driven equipment investment: Plant bottleneck analysis replaces intuition-based capital expenditure decisions with quantified throughput data, ensuring equipment purchases address the actual constraint points rather than perceived ones
- Schedule optimization: Python-driven optimization algorithms analyze production schedules to identify the most impactful sequencing changes, improving throughput without requiring any new equipment at all
- Cross-functional visibility: Leadership gains a unified view of both governance health metrics and production efficiency indicators, connecting workforce management to manufacturing output in a single operational picture
- Audit-ready documentation: Every governance action is logged with timestamps, approvals, and completion status, providing the documentation trail that regulatory audits require without additional administrative burden
Problem Addressed
Contract manufacturers in regulated industries face a dual operational burden that most organizations experience as separate problems but that compounds when both exist in the same environment. The governance side demands rigorous process adherence: when an employee joins, their access permissions must be provisioned correctly across every system they need. When they leave, those permissions must be revoked completely and promptly. In medical device manufacturing, a missed offboarding step is not just an IT inconvenience; it is a potential FDA audit finding. The manual processes that handle these transitions are fragile. They depend on emails being read, tickets being filed, and multiple departments coordinating without a central orchestration layer.
Simultaneously, the production floor operates with throughput constraints that are felt but rarely measured. A CNC machining center that runs at 95% utilization becomes the bottleneck for every downstream process, but without systematic analysis, the operations team may invest in additional inspection capacity or packaging equipment instead. The capital expenditure decision is significant in contract manufacturing, where a single precision machining center can cost hundreds of thousands of dollars. Making that investment based on anecdotal reports rather than data-driven bottleneck analysis means the constraint persists even after the money is spent. The organization needs both problems solved: governance processes that execute reliably without manual coordination, and production analysis that quantifies exactly where throughput is constrained.
What the Agent Does
The agent operates across two domains through a unified automation platform, handling governance workflow orchestration and production bottleneck analysis as interconnected operational functions:
- Onboarding workflow automation: Triggers provisioning sequences across IT systems, badge access, compliance training assignments, and department-specific tool access when new employees are added, ensuring complete setup without manual coordination
- Offboarding compliance execution: Initiates and tracks multi-system access revocation, equipment return workflows, knowledge transfer documentation, and compliance signoff when employees depart, with escalation triggers for any step exceeding its SLA
- Bottleneck identification engine: Analyzes production line data including machine utilization rates, queue depths, cycle times, and changeover durations to identify the specific equipment or process steps that constrain overall throughput
- Equipment purchase recommendations: Generates capital expenditure recommendations ranked by throughput impact, showing exactly how much additional capacity each potential equipment purchase would unlock
- Schedule optimization modeling: Applies Python-driven optimization algorithms to production schedules, identifying sequencing changes and batch sizing adjustments that improve throughput within existing equipment capacity
- Governance audit reporting: Produces compliance-ready reports showing the status and completion metrics for all governance activities, with drill-down capability into any individual onboarding or offboarding event
Standout Features
- Dual-domain intelligence: Unlike single-purpose tools that address either HR governance or production optimization, this agent connects both domains, enabling the organization to see how workforce changes affect production capacity and vice versa
- Python-driven optimization engine: Production schedule analysis uses mathematical optimization rather than heuristic rules, finding non-obvious sequencing improvements that human schedulers consistently miss because the solution space is too large to explore manually
- SLA-enforced governance workflows: Every step in on/off-boarding has a defined completion window with automatic escalation, transforming what was previously a best-effort process into a measurable, enforceable operational standard
- Capital expenditure simulation: Before recommending equipment purchases, the agent models the expected throughput impact of each option, allowing operations leadership to compare investment scenarios with quantified production improvements
- Regulatory compliance mapping: Governance workflows are mapped to specific regulatory requirements such as FDA QSR and ISO 13485, ensuring the automation directly addresses the compliance obligations the organization must satisfy
Who This Agent Is For
This agent is built for manufacturing and regulated organizations where governance overhead and production optimization both represent significant operational costs that compound when addressed separately.
- Operations directors in contract manufacturing who need to optimize production throughput while maintaining strict governance compliance across a growing workforce
- IT and compliance teams responsible for employee lifecycle management in regulated industries where incomplete offboarding represents audit risk and potential regulatory findings
- Plant managers making capital expenditure decisions who need data-driven justification for equipment purchases rather than relying on floor-level anecdotal reports
- Production schedulers seeking algorithmic optimization of job sequencing and batch sizing to maximize throughput within existing equipment constraints
Ideal for: Medical device manufacturers, aerospace component suppliers, pharmaceutical contract manufacturers, and any regulated manufacturing environment where governance compliance and production efficiency must both improve without proportional increases in administrative or engineering headcount.

Content Summarization AI Agent
AI-powered summarization agent that automatically generates concise summaries of internal content pages across the enterprise, enabling faster knowledge discovery and reducing the time employees spend searching for and digesting relevant information.
Applying NLP summarization models to enterprise content pages: an architecture for automated knowledge condensation at scale across a global technology and entertainment organization
A global technology and entertainment conglomerate with operations spanning multiple industries and over 100,000 employees faced an information architecture problem that grew worse with every page published on its internal platforms. The organization maintained thousands of internal content pages across divisions covering product documentation, policy updates, project status reports, research findings, training materials, and organizational announcements. Employees in one division had no practical way to discover relevant content published by other divisions. The internal search tools returned page titles and snippets, but determining whether a page was actually relevant required opening it and reading through the full content. When your internal knowledge base contains tens of thousands of pages, reading each one to determine relevance is not a viable discovery strategy.
The Content Summarization AI Agent was developed during a rapid prototyping initiative to address this discovery gap. The agent processes every internal content page to generate a structured summary that captures the key information, decisions, action items, and relevance indicators from the source content. These summaries serve as a condensed knowledge layer that sits between the search index and the full content, enabling employees to assess the relevance of any page in seconds rather than minutes. The technical implementation leverages large language model summarization with domain-specific prompting to maintain accuracy across the diverse content types that a multi-industry organization produces.
Benefits
This agent creates an automated knowledge condensation layer that fundamentally changes how employees discover and consume internal information across a large enterprise.
- Order-of-magnitude reduction in discovery time: Employees assess the relevance of internal pages by reading a three-sentence summary rather than scanning through full documents, reducing the time-to-determination from minutes to seconds per page
- Cross-divisional knowledge visibility: Summaries make content from other divisions discoverable without requiring employees to understand the information architecture, terminology, or publishing conventions of organizations outside their own
- Reduced information overload: Instead of facing an unfiltered list of full-length pages for any search query, employees see condensed summaries that allow rapid triage of which content deserves full attention and which can be deprioritized
- Accelerated onboarding: New employees navigate the internal knowledge base through summaries that provide quick orientation to existing documentation, reducing the ramp-up time required to develop organizational context
- Continuous coverage without manual effort: The agent processes new and updated pages automatically, maintaining summary coverage across the entire knowledge base without requiring content authors to write summaries or knowledge managers to curate descriptions
- Improved content quality signals: Summary generation reveals content that is outdated, duplicative, or insufficiently structured, providing content governance teams with automated quality indicators across the knowledge base
Problem Addressed
The information overload problem in large enterprises is often described in terms of volume, but the real issue is the cost of relevance assessment. A search query that returns 200 results is not inherently problematic if the user can quickly determine which results are relevant. The problem is that determining relevance for an internal content page typically requires reading it. Page titles are frequently generic or ambiguous. Search snippets capture whatever text happens to appear near the matched keywords, which may or may not represent the page's actual content or purpose. The result is that employees adopt one of two coping strategies: they read far more content than necessary, wasting hours on pages that turn out to be irrelevant; or they narrow their searches so aggressively that they miss relevant content from unexpected sources.
For a conglomerate operating across technology, entertainment, financial services, and consumer electronics, this problem is compounded by the organizational distance between content producers and potential consumers. A research finding published by a gaming division might be directly relevant to an engineering team in the electronics division, but the gaming team's page title uses domain terminology that the electronics team would never search for. Without a summary layer that describes content in accessible terms, cross-pollination of knowledge across divisional boundaries depends entirely on personal networks and coincidental discovery. The larger the organization, the more valuable cross-divisional knowledge sharing becomes, and the harder it is to achieve through search alone.
What the Agent Does
The agent operates as a continuous summarization pipeline that processes internal content pages into structured summaries optimized for rapid relevance assessment:
- Content page ingestion: The agent connects to internal content management systems, wiki platforms, and document repositories to access the full text of every published internal page, processing both new publications and updates to existing content on a continuous basis
- Content structure analysis: Each page is analyzed to identify its type, including policy documents, project updates, research reports, training materials, and announcements, with the analysis informing the summarization strategy applied to that specific content category
- AI-powered summarization: Large language models generate concise summaries that capture the key information, decisions, recommendations, and action items from each page, calibrated to provide enough detail for relevance assessment without replicating the full content
- Key entity and topic extraction: Beyond the narrative summary, the agent extracts structured metadata including referenced products, projects, teams, technologies, dates, and decision outcomes, enabling faceted filtering and cross-reference discovery
- Summary index integration: Generated summaries are indexed alongside the source content, appearing in search results and browse interfaces as a preview layer that users can scan before deciding whether to access the full page
- Staleness detection and refresh: The agent monitors source pages for updates and regenerates summaries when content changes, flags pages that have not been updated beyond their expected lifecycle, and identifies content that may be outdated
Standout Features
- Content-type-aware summarization: The summarization model applies different extraction strategies for different content types: policy documents get obligation and change summaries, project updates get status and milestone summaries, research reports get finding and recommendation summaries
- Cross-divisional terminology normalization: Summaries translate division-specific jargon into accessible language, making content from specialized domains discoverable by employees who would not know the domain-specific terms to search for
- Relevance scoring by role: Summary presentation is personalized based on the viewer's organizational role and division, highlighting aspects of the content most likely to be relevant to their function without filtering out information that might be unexpectedly useful
- Duplicate and overlap detection: The summarization pipeline identifies content pages that cover substantially similar topics, flagging potential duplicates for content governance review and suggesting canonical sources when multiple pages address the same subject
- Summary quality validation: Generated summaries are automatically validated against the source content for factual accuracy, completeness of key points, and absence of hallucinated information, with low-confidence summaries flagged for human review
Who This Agent Is For
This agent is designed for large enterprises where the volume of internal content has exceeded the capacity of search tools alone to support effective knowledge discovery and cross-organizational information sharing.
- Knowledge management teams responsible for making internal content discoverable and useful across divisions that operate with different terminologies and information architectures
- Enterprise search and information architecture teams seeking to improve the relevance assessment experience without requiring content authors to maintain manual summaries
- Technology and entertainment conglomerates where cross-divisional knowledge sharing could drive innovation but organizational scale makes manual discovery impractical
- Content governance teams needing automated signals about content quality, freshness, duplication, and coverage gaps across a large internal knowledge base
- IT leaders evaluating AI applications that deliver measurable productivity improvements to knowledge workers across the organization
Ideal for: Knowledge management directors, enterprise architects, content strategists, IT leaders, and any organization where employees routinely say "I did not know that page existed" or "I found this by accident" when discovering relevant internal content that was published months ago.

Campaign Taxonomy AI Agent
AI agent that analyzes marketing campaigns for incorrect taxonomy names, recommends corrected classifications to ensure accurate analytics categorization, and operates through a human-in-the-loop approval workflow before any changes go live.
One wrong tag on a campaign and the performance data lands in the wrong analytics bucket. Multiply that across hundreds of campaigns and your marketing measurement becomes unreliable.
The Campaign Taxonomy AI Agent was built for marketing organizations where campaign naming conventions and taxonomy structures have grown complex enough that human error in classification is no longer an occasional nuisance but a systemic data quality problem. A destination marketing organization promoting one of the most visited regions in the United States found that their campaigns were consistently mislabeled. Taxonomy names did not match the established naming conventions, causing campaign data to land in incorrect analytics buckets. Every mislabeled campaign meant that performance reports told an incomplete or misleading story. Channel attribution was skewed. Budget allocation decisions were being made on data that did not reflect reality. And the manual process of catching and correcting these errors consumed hours that the team needed for actual campaign strategy.
Benefits
This agent creates a systematic quality layer between campaign creation and analytics reporting, catching taxonomy errors before they corrupt the data that drives marketing decisions.
- Accurate analytics categorization: Every campaign lands in the correct analytics bucket, eliminating the downstream reporting errors that cascade when taxonomy names are wrong at the source
- Human-in-the-loop confidence: The agent recommends corrections but requires human approval before any changes take effect, combining AI speed with human judgment for a workflow the team can trust
- Elimination of manual taxonomy audits: Instead of periodic manual reviews where analysts scan campaign lists looking for naming errors, the agent surfaces discrepancies automatically as they occur
- Consistent naming standards at scale: As the organization runs hundreds or thousands of campaigns across channels, the agent enforces taxonomy standards that would be impossible to maintain through manual review alone
- Preserved institutional knowledge: Taxonomy rules and naming conventions are encoded in the agent rather than living in the heads of senior team members, reducing the risk of knowledge loss during staff transitions
- Faster campaign launches: Teams can move quickly on campaign setup knowing that the taxonomy validation layer will catch classification errors before they impact reporting, rather than triple-checking every naming field manually
Problem Addressed
Marketing taxonomy seems simple until it is not. An organization running five campaigns across two channels can manage naming conventions in a spreadsheet. An organization running five hundred campaigns across twelve channels, each with sub-categories for region, audience segment, campaign type, and budget tier, faces a combinatorial complexity that defeats manual consistency. The taxonomy structure that looked clean when it was designed becomes a minefield of edge cases, legacy naming patterns, and human interpretation differences as more people create campaigns and more categories are added over time.
The consequences are not cosmetic. When campaigns are miscategorized, every downstream analysis is compromised. Channel performance comparisons become unreliable because campaigns attributed to one channel actually belong to another. Regional performance dashboards show incorrect figures because campaigns were tagged to the wrong geography. Year-over-year comparisons break down because naming conventions drifted and nobody caught it. The marketing team loses confidence in their own data, and budget allocation conversations shift from evidence-based decisions to arguments about whether the data can be trusted at all. The root cause is always the same: taxonomy errors at the point of campaign creation that nobody caught until the reports looked wrong.
What the Agent Does
The agent operates as an intelligent taxonomy validation and correction layer, analyzing campaign metadata against established naming conventions and surfacing discrepancies for human review:
- Campaign metadata scanning: Continuously monitors new and existing campaigns for taxonomy fields that deviate from established naming conventions, catching errors at creation time rather than after data has been reported
- AI classification recommendation: Analyzes the campaign context, content, and metadata to recommend the correct taxonomy name when a discrepancy is detected, using pattern matching against the organization's established naming rules
- Confidence scoring: Assigns a confidence level to each recommendation so reviewers can quickly approve high-confidence corrections and focus their attention on ambiguous cases that require human judgment
- Human approval workflow: Presents all recommended corrections through an approval interface where team members review, accept, modify, or reject each suggestion before any changes are applied
- Batch processing capability: Handles retroactive taxonomy cleanup across historical campaigns, identifying and recommending corrections for legacy data that was miscategorized before the agent was deployed
- Rule learning and adaptation: Improves its classification accuracy over time by learning from human approval and rejection patterns, becoming more aligned with the organization's specific taxonomy interpretation
Standout Features
- Human-in-the-loop design philosophy: The agent explicitly does not auto-correct. Every recommendation passes through human review, giving teams the efficiency of AI detection with the accountability of human approval for every taxonomy change
- Context-aware classification: Rather than simple string matching, the agent understands campaign context, using campaign objectives, channel metadata, and content signals to recommend the correct taxonomy even when naming patterns are ambiguous
- Retroactive cleanup engine: Beyond catching new errors, the agent can scan the entire historical campaign catalog and surface systematic taxonomy issues that have been silently corrupting analytics for months or years
- Taxonomy drift detection: Identifies when naming conventions are being applied inconsistently across teams or regions, surfacing organizational alignment issues before they become entrenched data quality problems
Who This Agent Is For
This agent is designed for marketing organizations where campaign volume and taxonomy complexity have exceeded the team's ability to maintain classification accuracy through manual processes.
- Marketing operations teams responsible for campaign setup and naming conventions who need automated quality checks before data hits the reporting layer
- Analytics teams that depend on accurate campaign categorization for attribution, performance reporting, and budget allocation recommendations
- Destination marketing organizations, agencies, and brands running hundreds of campaigns across multiple channels, regions, and audience segments simultaneously
- Marketing leadership that has lost confidence in reporting accuracy due to recurring taxonomy inconsistencies and needs a systematic solution
Ideal for: Tourism boards, retail brands, agencies managing multi-client campaigns, financial services marketing teams, and any organization where campaign taxonomy errors have become a recurring source of analytics distortion and misallocated budget.

Product Innovation AI Agent
AI-powered innovation agent that analyzes customer feedback, product usage data, and market signals to identify high-impact opportunities for smarter product features, helping consumer product companies maintain competitive advantage through data-driven innovation.
You know the feeling. You are in a product planning meeting, and someone says "customers want smarter features." Everyone nods. Nobody can say exactly which features, for which customers, or what "smarter" actually means in terms of engineering requirements.
A heritage consumer products company known worldwide for home care equipment faced this challenge at a pivotal moment. The company had been manufacturing cleaning and maintenance products for over a century, building deep expertise in mechanical engineering and consumer design. But the competitive landscape was shifting. Newer entrants were embedding AI and connected features into products that had traditionally been purely mechanical. Customers were beginning to expect their home care equipment to be as intelligent as their phones. The product development team knew they needed to innovate, but the gap between "we should add AI features" and "here is exactly what to build and why" was filled with noise rather than signal.
The Product Innovation AI Agent was deployed to close that gap. It connects to customer feedback channels, product usage data, market research, and competitive intelligence sources to identify specific, actionable innovation opportunities. Instead of relying on intuition about what customers might want, the product team gets concrete analysis backed by data. Instead of evaluating feature ideas based on who argues loudest in the meeting, they evaluate them based on projected impact scores derived from actual customer behavior and market signals. Here is what working with the agent actually looks like on a day-to-day basis.
Benefits
This agent changes how product teams identify and prioritize innovation opportunities, replacing opinion-driven planning with data-driven discovery that connects customer needs to engineering possibilities.
- Find the features customers actually want: The agent surfaces innovation opportunities from patterns in customer feedback, support tickets, product reviews, and usage data, identifying needs that customers express but product teams have not yet connected to feature concepts
- Prioritize with confidence: Every identified opportunity includes an impact score based on customer reach, competitive differentiation potential, engineering feasibility signals, and market timing, replacing the debate-driven prioritization that slows planning cycles
- Spot market shifts early: Continuous monitoring of competitor product launches, patent filings, and market research surfaces emerging trends while they are still opportunities rather than competitive threats that require reactive responses
- Connect engineering to customer value: The agent translates customer needs into technical requirements that engineering teams can evaluate and estimate, bridging the language gap between what customers describe and what engineers can build
- Reduce failed feature investments: Data-validated innovation hypotheses reduce the risk of investing engineering resources in features that customers will not adopt, shortening the cycle from concept to validated product-market fit
- Build institutional innovation memory: Every analyzed opportunity, rejected concept, and validated hypothesis is captured in a searchable knowledge base, preventing the organization from repeatedly investigating the same ideas or losing insights from past exploration
Problem Addressed
Product innovation at established consumer goods companies faces a paradox. The company has decades of customer relationships, millions of products in use, and enormous volumes of customer feedback flowing through support channels, reviews, social media, and direct research. The data that should guide innovation decisions exists in abundance. But it exists in fragmented, unstructured, and disconnected forms that no human team can synthesize at the volume and speed needed to drive competitive product planning.
Product managers read customer reviews when they have time. Support teams escalate recurring complaints when they notice patterns. Market researchers produce quarterly reports that arrive after the planning window has closed. Engineering teams hear secondhand accounts of customer needs filtered through multiple organizational layers. The result is that innovation decisions are made based on whichever signal happened to reach the right person at the right time, rather than a systematic analysis of all available signals. Good ideas get pursued because someone was in the right meeting. Better ideas get missed because the data supporting them was scattered across three systems that nobody thought to cross-reference. And the competitive window for any given innovation keeps shrinking as the market accelerates around companies that are still running quarterly planning cycles.
What the Agent Does
The agent operates as a continuous innovation intelligence system that synthesizes customer, market, and competitive signals into prioritized product development opportunities:
- Customer signal aggregation: The agent ingests data from product reviews, support tickets, social media mentions, survey responses, and direct customer research, normalizing feedback from diverse sources into a unified analysis framework
- Usage pattern analysis: Product telemetry and usage data are analyzed to identify behavioral patterns that reveal unmet needs, feature adoption rates, common usage sequences, and friction points where customers struggle or abandon tasks
- Competitive intelligence monitoring: The agent tracks competitor product launches, feature announcements, patent filings, and market positioning to identify gaps in the competitive landscape and emerging capability expectations
- Opportunity identification and scoring: Cross-referencing customer signals, usage patterns, and competitive intelligence, the agent identifies specific innovation opportunities and scores them based on projected customer impact, competitive differentiation, and market timing
- Technical feasibility bridging: Identified opportunities are translated into preliminary technical requirements that engineering teams can evaluate, including component specifications, integration requirements, and complexity assessments
- Innovation pipeline dashboard: A continuously updated view presents the current opportunity landscape, trending customer needs, competitive movements, and recommended innovation priorities with supporting evidence for each recommendation
Standout Features
- Natural-language opportunity briefs: Each identified innovation opportunity is presented as a structured brief that includes the customer need, supporting evidence, competitive context, preliminary technical approach, and projected impact, ready for direct inclusion in product planning discussions
- Cross-signal correlation: The agent identifies opportunities that only become visible when multiple signal sources are combined, such as a support complaint pattern that correlates with a usage drop-off that aligns with a competitor's newly launched feature
- Trend velocity tracking: Beyond identifying what customers need, the agent measures how fast specific needs are growing, helping product teams distinguish between stable long-term opportunities and accelerating demands that require urgent response
- Innovation memory and deduplication: Previously analyzed opportunities are tracked and referenced, preventing the organization from spending cycles re-evaluating ideas that were already investigated and providing the reasoning behind past decisions when similar concepts resurface
- Configurable market focus: The agent's monitoring scope is tunable by product category, customer segment, geographic market, and competitive set, allowing product teams to focus intelligence gathering on the specific domains most relevant to their current planning priorities
Who This Agent Is For
This agent is built for product teams at consumer goods companies where the pressure to innovate is high but the process for identifying and validating innovation opportunities relies too heavily on intuition and fragmented data.
- Product managers who spend planning cycles debating feature priorities based on anecdotal customer feedback rather than systematic analysis of all available signals
- Innovation teams at heritage brands navigating the transition from purely mechanical products to AI-enabled, connected, and intelligent product experiences
- Engineering leaders who need clear, data-validated product requirements rather than vague feature descriptions filtered through multiple organizational layers
- Marketing teams seeking competitive intelligence on feature trends, market positioning shifts, and emerging customer expectations in their product categories
- Executive leadership who need to allocate R&D investment across innovation bets with confidence that priorities are based on evidence rather than opinion
Ideal for: Product directors, innovation leads, engineering managers, brand strategists, and executive teams at consumer products companies where the question is not whether to innovate but where to focus innovation investment for maximum customer impact and competitive differentiation.

Sentiment Analysis AI Agent
AI agent that goes beyond basic positive/negative sentiment scoring to surface specific, actionable customer pain points from review data, automatically routing targeted resolution recommendations to the teams best positioned to act.
Thousands of customer reviews arrive every week. Traditional sentiment tools label them positive or negative. But knowing a review is negative does not tell anyone what to fix or who should fix it.
The Sentiment Analysis AI Agent was built for organizations drowning in customer feedback that existing tools reduce to a single score. A national restaurant chain with hundreds of locations faced this exact limitation. Their review volume had grown to the point where manual reading was impossible, and their existing sentiment tools only told them what they already knew: some customers were unhappy. What they needed was specificity. Which locations had recurring complaints about wait times versus food quality versus staff interactions? Which complaints represented systemic issues versus one-off incidents? And most importantly, who on the operations side should receive which insights to actually drive resolution?
Benefits
This agent transforms raw customer feedback from a lagging indicator into an operational early warning system that drives measurable improvements across locations, products, and service touchpoints.
- Specific pain point identification: Instead of a sentiment score that tells you customers are unhappy, the agent isolates exactly what they are unhappy about, distinguishing between wait time complaints, product quality issues, staff interaction problems, and pricing concerns within the same batch of reviews
- Automated team routing: Each identified pain point is matched to the team or role best equipped to address it, so operations leaders see facility issues, product teams see quality complaints, and training managers see service interaction patterns without anyone manually triaging feedback
- Trend detection across locations: The agent identifies when the same complaint type surfaces across multiple locations or geographies, distinguishing systemic problems that require corporate-level intervention from localized issues that individual managers can resolve
- Resolution recommendations: Beyond identifying what is wrong, the agent generates specific, actionable recommendations based on the complaint patterns it detects, giving teams a starting point for remediation rather than just a problem statement
- Real-time operational awareness: Teams receive insights as review data flows in rather than waiting for monthly or quarterly analysis cycles, enabling faster response to emerging issues before they compound into reputation damage
- Reduced analytical overhead: Analysts previously spending hours reading and categorizing reviews can redirect their time to strategic work, as the agent handles the extraction, classification, and routing that consumed the majority of their review analysis bandwidth
Problem Addressed
The gap between collecting customer feedback and acting on it has widened as review volumes have grown. Organizations with hundreds of locations, thousands of products, or millions of customer interactions generate more qualitative feedback than any human team can process. Sentiment scoring tools were the first attempt to bridge this gap, but they introduced a different problem: oversimplification. Knowing that 34% of reviews are negative this quarter compared to 28% last quarter tells leadership that something changed, but it does not tell them what changed, where it changed, or what to do about it.
The operational cost of this gap is significant. When feedback sits unanalyzed or is reduced to scores that lack specificity, the same complaints repeat week after week. Locations that could have corrected a training issue in days continue receiving the same negative reviews for months. Product defects that customers describe in precise detail go unaddressed because the feedback never reaches the engineering team in a format they can act on. The problem is not a lack of customer voice. It is a lack of infrastructure to translate that voice into specific, routed, actionable intelligence at the speed the business requires.
What the Agent Does
The agent operates as a full-cycle feedback intelligence pipeline, ingesting raw customer reviews and producing categorized, routed, and recommendation-enriched insights ready for team action:
- Multi-source review ingestion: Connects to review platforms, survey systems, support tickets, and social channels to aggregate customer feedback from every source into a unified analysis stream
- Granular complaint extraction: Applies natural language understanding to identify specific complaint topics within each review, separating a single review that mentions both slow service and cold food into two distinct, trackable issues
- Pattern clustering and severity scoring: Groups similar complaints across the review corpus and scores each cluster by frequency, recency, and sentiment intensity to prioritize the issues causing the most customer impact
- Intelligent team routing: Maps each complaint category to the appropriate department, role, or location manager using configurable routing rules, ensuring insights reach decision-makers without manual triage
- Actionable recommendation generation: Produces specific remediation suggestions for each complaint cluster based on the nature of the feedback, giving teams a concrete starting point rather than just a problem label
- Trend monitoring and alerting: Tracks complaint patterns over time and triggers alerts when new issues emerge, existing issues accelerate, or previously resolved problems resurface across the organization
Standout Features
- Beyond-sentiment specificity engine: While conventional tools stop at positive, negative, or neutral classification, this agent identifies the exact noun-verb combinations that define each complaint, turning vague dissatisfaction into addressable operational issues
- Cross-location pattern recognition: Automatically detects when identical complaint patterns appear across geographically dispersed locations, distinguishing between a local manager problem and a systemic corporate issue that requires enterprise-level intervention
- Dynamic routing intelligence: Learns from organizational structure and previous resolution patterns to route insights to the person or team most likely to act on them, adapting as team responsibilities shift
- Resolution tracking feedback loop: Monitors whether routed recommendations lead to measurable complaint reduction, creating a closed-loop system that validates which interventions actually improve customer sentiment over time
Who This Agent Is For
This agent is built for organizations where the volume and variety of customer feedback have outgrown the capacity of manual analysis and the usefulness of basic sentiment scoring.
- Customer experience teams managing feedback across dozens or hundreds of locations who need complaint-level specificity rather than aggregate sentiment trends
- Operations leaders responsible for service quality across distributed teams who need to know exactly which issues to address at which locations
- Product managers tracking customer reception of new offerings who need to separate product complaints from service complaints within the same review streams
- Quality assurance teams that need early detection of recurring defects or service failures before they become widespread reputation issues
- Marketing teams monitoring brand perception who need granular understanding of what drives negative sentiment rather than just tracking its trajectory
Ideal for: Restaurant chains, retail networks, hospitality groups, healthcare systems, and any multi-location business where customer feedback volume demands automated extraction, classification, and routing to convert reviews into operational improvements.

Contract Review Intelligence AI Agent
AI-powered contract intelligence system that automates extraction of critical terms from complex multi-page agreements, tracks renewal and compliance milestones with automated notifications, and provides a conversational interface for natural-language contract queries across the entire portfolio.
Faster access to critical contract terms. Automated milestone tracking across hundreds of agreements. Zero missed renewal deadlines. Compliance visibility that executives can actually use.
A national behavioral health organization providing services to individuals with intellectual and developmental disabilities across multiple states managed a portfolio of hundreds of active contracts. Each agreement governed the terms under which the organization delivered care in a specific jurisdiction, and each ran 80 pages or more of dense legal language covering rates, obligations, performance requirements, renewal terms, and compliance mandates. Staff members responsible for managing these contracts spent hours reading through documents to find specific terms, tracking renewal dates on spreadsheets that were perpetually out of date, and answering executive questions about contractual obligations by physically locating and re-reading the relevant agreement. The administrative burden was enormous, and the risk of missing a critical deadline was constant.
The Contract Review Intelligence AI Agent replaced this manual operation with an automated system that extracts every critical term from every contract, tracks every milestone and deadline, and answers natural-language questions about any agreement in the portfolio instantly. The results were immediate: faster access to contract information for every stakeholder, elimination of the manual tracking that consumed administrative hours, improved compliance visibility for leadership, and the organizational confidence that comes from knowing no critical deadline will be missed because someone forgot to check a spreadsheet.
Benefits
This agent delivers measurable improvements across every dimension of contract management, from daily operational queries to strategic portfolio oversight.
- 80% reduction in contract query response time: Questions that previously required locating a document, reading through 80+ pages, and interpreting legal language are now answered instantly through a conversational interface with citation-backed responses
- Zero missed renewal deadlines: Automated milestone tracking with cascading notifications ensures that every renewal window, termination notice period, and compliance deadline receives appropriate attention at 90, 60, and 30 days before expiration
- Recovered administrative capacity: Staff previously dedicated to contract reading and spreadsheet maintenance redirect their time to compliance management, relationship development, and strategic contract negotiations
- Executive-ready compliance visibility: Leadership accesses real-time dashboards showing the organization's complete contractual position including upcoming obligations, risk concentrations, and rate structures across all jurisdictions
- Consistent extraction across the portfolio: Every contract is processed against the same extraction schema, ensuring that critical terms are captured uniformly whether the agreement was signed last week or five years ago
- Audit-ready contract documentation: Structured contract data with source document references provides the documentation framework that regulatory auditors require, eliminating the document assembly scramble that audits previously triggered
Problem Addressed
Organizations that manage large portfolios of complex agreements operate with a persistent knowledge gap. The terms, obligations, and deadlines that govern their operations exist inside documents that are difficult to search, time-consuming to read, and impossible to monitor at scale. When a compliance officer needs the termination notice period for a specific contract, the answer requires finding the document, opening it, and reading until the relevant clause appears. When an executive asks about the organization's total rate exposure across a specific service category, the answer requires reading every contract that covers that service. When a renewal window opens, someone needs to have remembered to flag the date months earlier on a tracking spreadsheet that depends on a human having read and correctly extracted the deadline from the original document.
For organizations operating in regulated industries where compliance failures carry financial and operational consequences, this knowledge gap is not just an inconvenience. It is a risk vector. Missed renewal windows force organizations into unfavorable auto-renewal terms or gaps in coverage. Overlooked compliance obligations trigger regulatory scrutiny. Inconsistent rate tracking across jurisdictions creates financial exposure that leadership cannot quantify because the data lives inside documents that nobody has the time to read comprehensively. The problem scales linearly with portfolio size: every new agreement added to the portfolio increases the surface area of potential oversight, and no amount of diligent manual effort can keep pace with a growing portfolio of 80-page documents.
What the Agent Does
The agent operates as a comprehensive contract intelligence system that transforms unstructured legal documents into a monitored, queryable knowledge base:
- Contract document ingestion: The agent ingests contracts from document repositories in PDF, Word, and scanned formats, processing documents of any length including the 80+ page agreements that present the greatest extraction challenge and carry the highest oversight risk
- Critical term extraction: AI models analyze each document to extract key data points including effective dates, expiration dates, renewal terms, termination notice periods, rate structures, performance obligations, compliance requirements, and amendment histories
- Structured portfolio dataset: Extracted terms populate a normalized dataset that integrates with existing business intelligence tools, enabling cross-contract analysis, compliance dashboards, and financial reporting across the entire portfolio
- Milestone tracking and cascading notifications: Every extracted deadline is monitored with automated alerts that escalate through configured notification chains, starting with contract owners and reaching leadership as deadlines approach
- Natural-language query interface: Authorized users ask questions about any contract in plain language and receive immediate responses with specific clause references, page numbers, and source document links for verification
- Portfolio analytics and risk visualization: Aggregated contract data surfaces organizational-level insights including total obligation exposure, renewal volume forecasts, rate variance analysis, and compliance risk concentration by jurisdiction
Standout Features
- Citation-backed conversational answers: Every response from the query interface includes document name, page number, and clause identifier so that users can verify any answer against the source material in seconds rather than re-reading the entire agreement
- Multi-format document processing: The agent handles digital PDFs, scanned documents, and Word files with OCR applied where needed, ensuring that even legacy contracts archived as scans are fully extractable and searchable
- Configurable escalation cascades: Notification schedules are customizable per contract type and milestone category, with escalation paths that automatically widen the recipient list as deadlines approach, ensuring that critical dates receive proportional attention
- Cross-contract inconsistency detection: The agent identifies material differences across similar agreements, flagging contracts where rates, terms, or obligations diverge from organizational standards or from comparable agreements in adjacent jurisdictions
- Living portfolio intelligence: As new contracts are executed and existing ones are amended, the system updates automatically, maintaining a single source of truth that reflects the current state of every active agreement without manual re-extraction
Who This Agent Is For
This agent is designed for organizations where the volume, length, and complexity of contractual agreements have outgrown the capacity of manual review and spreadsheet-based tracking to provide reliable oversight.
- Legal teams managing hundreds of active agreements across jurisdictions where each contract runs 50-100+ pages of dense regulatory and operational terms
- Compliance officers responsible for monitoring contractual obligations and deadlines across a portfolio too large to track manually
- Healthcare and behavioral health organizations managing state-specific service agreements with varying rates, terms, and compliance requirements
- Procurement and vendor management teams overseeing supplier contracts where missed renewals or overlooked terms create financial and operational exposure
- Executives who need accurate answers about the organization's contractual position without waiting for staff to locate and read source documents
Ideal for: General counsel, contract managers, compliance directors, procurement leads, and executive leadership at organizations managing 50+ active agreements where the cost of a missed deadline, an overlooked obligation, or an unanswered query about contract terms represents real financial, regulatory, and operational risk.
Real-Time Yield Monitoring AI Agent
Continuous monitoring AI agent that tracks yield across products and individual components in precision manufacturing, automatically flagging drops before they compound into significant production efficiency losses.
In precision manufacturing, the yield problem is not that drops happen. It is that drops in individual components accumulate silently until the aggregate loss becomes visible in the daily summary, and by then the damage is done.
A specialized manufacturer of flexible printed circuits and rigid-flex assemblies for mission-critical applications in aerospace, medical, defense, and industrial markets operates in an environment where yield is not just a profitability metric. It is a quality control imperative. Every flexible circuit that fails a yield checkpoint represents wasted substrate material, lost production capacity, and potential downstream risk in applications where failure is not acceptable. The Real-Time Yield Monitoring AI Agent was engineered to address a specific gap in this environment: the time lag between a yield drop occurring at the component level and that drop being detected and investigated by the production team.
Benefits
This agent provides continuous yield surveillance at a granularity that manual monitoring cannot sustain, catching efficiency losses at the component level before they propagate into product-level and line-level yield degradation.
- Component-level detection granularity: The agent monitors yield at the individual component level rather than only at the product or line level, catching drops in specific circuit elements, layers, or process steps that would be masked in higher-level aggregation until they become severe
- Continuous monitoring without staffing burden: Yield surveillance operates around the clock across all active production lines and products without requiring dedicated monitoring personnel, extending detection coverage to every shift including those with reduced supervisory presence
- Prevention of compounding losses: Early detection at the component level prevents the cascading effect where a single-component yield drop reduces product-level yield, which reduces line-level throughput, which ultimately impacts delivery schedules and material costs
- Material cost protection: In flexible circuit manufacturing where substrate materials represent a significant portion of unit cost, every percentage point of yield recovered through earlier detection translates directly into material savings at scale
- Mission-critical quality assurance: For products destined for aerospace, medical, and defense applications, yield monitoring is not just an efficiency concern but a quality gate, and real-time detection ensures that process deviations are caught before affected components advance further in the production process
- Capacity recovery: Production capacity consumed by yield losses is capacity that cannot fulfill orders, and earlier detection reduces the volume of rework and scrap that effectively reduces plant capacity below its theoretical output
Problem Addressed
Flexible printed circuit manufacturing is a multi-step process where each layer, via, trace, and component must meet tight tolerances. Yield is not a single number. It is a cascading chain of yields at the substrate level, the layer registration level, the plating level, the component level, and the final assembly level. A 2% drop in plating yield on a specific via configuration may not trigger any alarm when viewed at the product level, where overall yield remains within acceptable range because other components are performing well. But that 2% drop represents a systematic process deviation that, left unaddressed, may worsen or spread to adjacent configurations.
The traditional approach to yield monitoring in this environment involves daily or shift-level yield summaries that aggregate data across products and components. These summaries are adequate for tracking broad trends but structurally incapable of detecting component-level deviations in real time. By the time a component yield drop becomes visible in the aggregated summary, it has been running for hours or days. The investigation starts from a cold state, the process conditions that caused the deviation may have already changed, and the production loss during the undetected period cannot be recovered. The fundamental problem is resolution: the monitoring system's temporal and component-level granularity does not match the speed and specificity at which yield deviations actually occur on the production floor.
What the Agent Does
The agent operates as a high-resolution yield monitoring system that continuously tracks performance at the component level and triggers alerts at the earliest detectable point of deviation:
- Multi-level yield ingestion: Connects to production test and inspection systems to collect yield data at multiple hierarchical levels including substrate, layer, component, subassembly, and final product, building a complete yield picture from the ground up
- Component-level baseline management: Maintains statistical baselines for every tracked component type and process step, dynamically adjusting for known variables such as product mix, material lot characteristics, and equipment configuration
- Real-time deviation detection: Applies statistical process control and change-point detection algorithms to identify yield deviations at the component level as they emerge, rather than waiting for the deviation to propagate to higher aggregation levels where it becomes visible in traditional reporting
- Hierarchical impact projection: When a component-level deviation is detected, the agent projects its expected impact on product-level yield and line-level throughput, enabling management to assess the severity in business terms rather than purely statistical ones
- Alert routing with investigation context: Delivers structured alerts to the appropriate process engineering and quality teams, including the specific component, process step, timing, magnitude, and any correlated changes in process parameters that may indicate root cause
- Trend tracking and pattern recognition: Maintains a running analysis of yield trends by component, product, line, and time period, identifying gradual degradation patterns that are invisible in snapshot reporting but critical for preventive maintenance and process improvement
Standout Features
- Hierarchical yield decomposition: The agent provides visibility into yield at every level of the product hierarchy simultaneously, allowing engineers to drill from a product-level anomaly down to the specific component and process step where the issue originates
- Adaptive sensitivity by application: Detection thresholds can be configured differently for products destined for different end markets, applying tighter monitoring to aerospace and medical-grade circuits than to industrial-grade products, reflecting the different quality requirements and consequence severity
- Process parameter correlation: When a yield deviation is detected, the agent automatically checks for correlated changes in monitored process parameters such as temperature profiles, chemical concentrations, exposure times, and equipment calibration records, narrowing the investigation scope before an engineer reviews the alert
- Material lot traceability integration: Yield events are cross-referenced against material lot information, enabling rapid identification of whether a yield drop is associated with a specific material batch and triggering quarantine recommendations when lot-correlated patterns emerge
Who This Agent Is For
This agent is built for precision manufacturing environments where yield is both an economic lever and a quality imperative, and where the granularity and speed of traditional yield monitoring leave detectable efficiency losses running longer than necessary.
- Process engineers at flexible circuit, PCB, semiconductor, or precision component manufacturers who need component-level yield visibility to maintain process control across complex multi-step production sequences
- Quality assurance managers in aerospace, medical, and defense manufacturing where yield monitoring serves as a critical quality gate and where undetected process deviations carry outsized risk
- Plant managers at high-mix manufacturing operations where product diversity creates a complex yield landscape that cannot be adequately monitored through aggregated daily summaries
- Continuous improvement teams seeking real-time yield data at the resolution needed to identify, investigate, and resolve process issues with statistical rigor rather than anecdotal observation
- Operations leaders at precision manufacturing companies where material costs make yield percentage points directly measurable in financial impact
Ideal for: Process engineers, quality directors, plant managers, continuous improvement leads, and any precision manufacturer where component-level yield visibility is the difference between detecting a process deviation in minutes versus discovering its consequences in the next day's summary report.
Marketing Goal Alignment AI Agent
Custom application that standardizes data-driven marketing goal setting across a network of agencies, aligning individual targets to broader business objectives and reducing inconsistency in performance accountability.
When you manage a network of agencies, the hardest problem is not setting goals. It is getting everyone to set the same kind of goals using the same data and the same definitions.
If you have ever tried to roll up marketing performance across a network of agencies, you know the problem. Each agency has its own spreadsheet, its own definitions of success, and its own process for setting quarterly targets. One agency sets goals based on lead volume. Another uses cost per acquisition. A third targets brand awareness metrics that do not map to any downstream business outcome. When leadership asks how the network is performing, the answer requires weeks of normalization work because the goals were not comparable in the first place. A global automotive technology company managing a large network of marketing agencies built this application to solve that problem at its root: standardizing how goals are set, what data they are based on, and how they connect to the business objectives that actually matter.
Benefits
This application replaces the spreadsheet-and-email goal-setting process with a structured system that ensures every agency in the network is working from the same playbook, using the same data, toward the same business outcomes.
- Standardized goal-setting process: Every agency in the network follows the same structured workflow for setting marketing goals, using the same metric definitions, data sources, and target-setting methodology, eliminating the inconsistency that previously made cross-agency comparison impossible
- Data-driven target setting: Goals are grounded in actual performance data rather than aspirational estimates, with the application providing historical benchmarks, trend data, and suggested target ranges that make goal setting a data exercise rather than a negotiation
- Business objective alignment: Individual agency goals are explicitly mapped to broader organizational business objectives, creating a traceable line from agency-level marketing activities to the outcomes that leadership measures the network against
- Cross-network visibility: Leadership can view goal status, progress, and performance across the entire agency network from a single interface, replacing the manual rollup process that previously consumed days of analyst time each quarter
- Improved accountability: When goals are set through a standardized, data-informed process and tracked in a shared system, the accountability conversation shifts from why did you miss to what does the data tell us about what happened, making performance reviews more productive
- Reduced goal-setting cycle time: The structured application compresses the quarterly goal-setting process from weeks of back-and-forth emails and spreadsheet revisions to a focused workflow that agencies complete in a fraction of the time
Problem Addressed
Here is the practical reality of managing marketing goals across a network of agencies. The quarterly planning cycle begins. Corporate sends out a template. Some agencies fill it out thoroughly. Others submit goals that do not match the template categories. A few set targets so conservative they are guaranteed to be met. Others set targets so aggressive they will never be achieved but look impressive in the planning presentation. By the time someone tries to aggregate the goals into a network-level view, they discover that the definitions do not align, the metrics are not comparable, and the connection between agency goals and business objectives is, at best, implied.
The downstream consequences are significant. Performance reviews become debates about definitions rather than discussions about outcomes. Agencies that consistently hit their self-set targets are not necessarily the highest performers. They may simply be the best at setting achievable goals. Meanwhile, agencies that are genuinely driving business results but set ambitious targets may appear to underperform. The lack of standardization does not just create a reporting problem. It creates a management problem. Without consistent, data-grounded, business-aligned goals across the network, leadership cannot effectively allocate resources, identify best practices, or make informed decisions about which agencies need support and which deserve expanded scope.
What the Agent Does
The application provides a structured goal-setting and tracking environment that guides agencies through a standardized process while connecting every target to measurable business outcomes:
- Standardized goal framework: Presents each agency with a consistent set of goal categories, metric definitions, and target-setting fields that enforce uniformity across the network while allowing for agency-specific context within the standardized structure
- Historical performance integration: Populates the goal-setting interface with each agency's historical performance data across relevant metrics, providing factual context that grounds target-setting in actual results rather than estimates
- Business objective mapping: Requires each agency goal to be explicitly connected to one or more corporate business objectives, creating a traceable alignment chain from daily marketing activities to organizational strategy
- Target range guidance: Provides data-driven suggested target ranges based on historical performance, network benchmarks, and seasonal factors, helping agencies set goals that are both ambitious and achievable
- Cross-network dashboard: Aggregates goal status and progress across all agencies into a leadership-facing view that enables comparison, pattern identification, and resource allocation decisions at the network level
- Progress tracking and reporting: Monitors actual performance against goals throughout the quarter, providing both agency-level progress views and network-level rollups that keep accountability current rather than retrospective
Standout Features
- Enforced consistency without rigidity: The application mandates standardized metrics and definitions while allowing agencies to add context, notes, and explanations that capture the local market factors and strategic considerations behind their targets
- Benchmark-informed target setting: Agencies see how their proposed targets compare to network averages, top-quartile performance, and their own historical trajectory, making the goal-setting conversation explicitly comparative and data-grounded
- Cascading alignment visualization: Leadership can trace any agency goal up to the business objective it supports and any business objective down to the agency goals that drive it, making the strategy-to-execution connection visible and auditable
- Automated rollup reporting: The quarterly leadership review that previously required days of manual data assembly now generates automatically from the standardized goal data, freeing analysts to focus on insight generation rather than data consolidation
- Goal revision workflow: When mid-quarter market changes warrant goal adjustments, agencies can submit revision requests through a structured approval workflow that maintains the audit trail and ensures changes are justified by data rather than convenience
Who This Agent Is For
This application is designed for organizations that manage marketing performance across a network of agencies, partners, or decentralized teams where goal-setting inconsistency creates alignment and accountability problems.
- Marketing operations leaders responsible for coordinating goal setting and performance tracking across a network of agencies or regional marketing teams
- Channel marketing directors who need consistent, data-grounded goals from each agency in the network to enable fair comparison and informed resource allocation
- Agency relationship managers who spend excessive time normalizing goal definitions and performance metrics across agencies that each use different frameworks
- Marketing analytics teams tasked with producing network-level performance rollups from inconsistent, agency-submitted goal data that requires manual harmonization
- Senior marketing leadership seeking a single view of goal alignment and progress across the entire agency or partner network
Ideal for: Marketing operations directors, channel marketing leaders, agency relationship managers, and any organization managing ten or more agencies, partners, or decentralized marketing teams where goal-setting standardization is the prerequisite for meaningful performance management.

Investment Document Extraction AI Agent
AI agent that extracts structured property data from large unstructured PDF offering memorandums, building a searchable database of investment opportunities with unit mix, amenity details, and source tracking for real estate acquisitions teams.
A 147-page offering memorandum lands in your inbox at 3pm. The investment committee meets tomorrow at 9am. Somewhere inside those 147 pages are the unit mix, the cap rate, the rent roll, and the renovation scope that will determine whether this deal is worth pursuing.
A real estate investment firm specializing in multifamily acquisitions faced this scenario multiple times per week. Every potential investment opportunity arrived as a thick PDF document prepared by a broker. These offering memorandums contained everything the acquisitions team needed to evaluate the opportunity: property descriptions, unit configurations, bedroom and bathroom counts, countertop types and appliance specifications, amenity packages, financial projections, rent rolls, capital expenditure histories, and market comparables. The information was comprehensive. It was also buried in 100-plus pages of unstructured text, tables, photographs, and floor plans that required hours of manual reading and data extraction before a single number could enter a spreadsheet.
The Investment Document Extraction AI Agent was built to solve this exact problem. It ingests offering memorandums in PDF format, extracts the specific property data points that the acquisitions team needs for evaluation, structures that data into a consistent format, and builds a searchable database that grows with every document processed. The analyst who used to spend four hours reading a single OM now gets the extracted data in minutes, along with a reference link back to the exact page and section of the source document where each data point was found.
Benefits
This agent transforms the acquisitions evaluation process from a document-reading bottleneck into a structured data operation where analysts spend their time on investment analysis rather than data entry.
- Hours reclaimed per opportunity: Data extraction that previously required 3-5 hours of manual reading per document is completed in minutes, giving analysts time to evaluate more deals and focus on the analysis that determines investment quality
- Consistent extraction across documents: Every offering memorandum is processed against the same extraction schema, eliminating the variability that occurred when different analysts extracted data from different documents using different approaches
- Historical deal database: Every processed document contributes to a growing, searchable database of current and historical investment opportunities, enabling comparative analysis across properties, markets, and time periods
- Source traceability: Every extracted data point links back to its source document and page, enabling instant verification without re-reading the original PDF when investment committee members question a specific number
- Faster response to opportunities: Compressed extraction timelines mean the acquisitions team can evaluate and respond to opportunities faster, reducing the risk of losing competitive deals to firms that move more quickly
- Reduced extraction errors: AI extraction eliminates the transcription errors, misread numbers, and overlooked sections that manual reading inevitably produces, especially when analysts are working under time pressure across multiple documents
Problem Addressed
The real estate investment evaluation process has a data extraction problem hiding inside a document reading problem. An offering memorandum is not a standardized document. Every broker, every market, and every property type produces documents with different structures, layouts, and levels of detail. One OM might present the unit mix as a clean table on page 12. Another buries the same information across narrative paragraphs on pages 23, 47, and 89. A third includes the data in an appendix that is actually a scanned photograph of a spreadsheet printed on physical paper. The acquisitions analyst's job is not just to find the data. It is to recognize what constitutes the relevant data point within a document that was designed to market the property, not to facilitate structured analysis.
This problem compounds with deal flow. An active investment firm might evaluate 20-30 opportunities per month. Each opportunity requires extracting the same categories of data from a different document with a different structure. Analysts develop shortcuts and heuristics. They learn which brokers put the unit mix in the appendix and which embed it in the property description. But those heuristics are personal knowledge that does not transfer when an analyst leaves, does not scale when deal flow increases, and does not help when a document from an unfamiliar broker arrives with a novel layout. The result is that the firm's ability to evaluate investment opportunities is bottlenecked by the speed at which skilled humans can read unstructured documents and type numbers into spreadsheets.
What the Agent Does
The agent operates as an automated extraction pipeline that converts unstructured offering memorandums into structured, queryable property datasets:
- Document ingestion from filesets: The agent monitors designated file storage locations for new offering memorandums, ingesting PDF documents of any length and structure including scanned, digital, and mixed-format documents
- Multi-section document parsing: The agent analyzes document structure to identify sections containing property descriptions, unit configurations, financial data, capital expenditure details, amenity specifications, and market comparables regardless of where those sections appear in the document
- Targeted data extraction: Specific property data points are extracted including bedroom counts, bathroom configurations, countertop types, appliance specifications, unit square footages, rent figures, occupancy rates, and renovation specifications
- Unit mix reconstruction: Scattered unit configuration data is consolidated into a standardized unit mix table showing each unit type, count, square footage, current rent, and market rent regardless of how that information was presented in the source document
- Structured dataset output: Extracted data is written into a normalized dataset with consistent field names, data types, and reference links back to the source document, page number, and extraction date for every data point
- Historical database accumulation: Each processed document adds to a growing database that enables cross-property comparison, market trend analysis, and historical deal reference without requiring analysts to re-read previously evaluated documents
Standout Features
- Layout-agnostic extraction: The agent handles offering memorandums from any broker, market, or property type without requiring document-specific templates, adapting its extraction approach to the structure of each individual document
- Source page referencing: Every extracted data point includes the exact page number and section of the source PDF where it was found, enabling one-click verification that eliminates the need to search through the original document
- Confidence scoring per field: Extraction results include confidence scores for each data point, clearly distinguishing between high-confidence extractions from clean tables and lower-confidence values pulled from narrative text or scanned images
- Cross-document deduplication: When the same property appears in updated offering memorandums over time, the agent identifies it as an update rather than a new opportunity, maintaining a version history that shows how deal terms evolved
- Comparative property analytics: The accumulated database enables instant comparison across properties on any extracted dimension, surfacing patterns like average renovation costs per unit type or typical cap rate ranges by market
Who This Agent Is For
This agent is built for real estate investment teams where the volume and complexity of offering memorandums have outgrown the capacity of manual document review to support timely deal evaluation.
- Acquisitions analysts who spend the majority of their time reading offering memorandums and entering property data into spreadsheets instead of performing investment analysis
- Investment committee members who need standardized, verifiable property data to make informed acquisition decisions without reading every source document themselves
- Real estate investment firms evaluating multiple opportunities per week where extraction speed directly affects competitive positioning
- Asset management teams that need historical property data from previously evaluated deals for portfolio comparison and market benchmarking
- Private equity real estate funds where deal flow volume requires systematic data extraction to maintain evaluation quality across a large opportunity pipeline
Ideal for: Acquisitions directors, investment analysts, asset managers, portfolio strategists, and any real estate investment professional who has ever wished they could search across every offering memorandum they have ever received instead of re-reading documents they reviewed six months ago.

Invoice Workflow Automation AI Agent
Multi-agent invoice processing system that ingests invoices from email, dynamically determines extraction methods based on document format, translates across languages, identifies missing data, and routes through decision-based workflows into accounting systems for global financial operations.
A multi-agent architecture that replaces a manual, email-distributed invoice processing operation with coordinated AI agents handling ingestion, extraction, translation, validation, and routing at global scale
A global financial services organization specializing in commodity trading processed thousands of invoices monthly across international markets. The invoices arrived in individual email inboxes throughout the organization, creating a distributed processing problem that no single system could observe or manage. A large operations team manually opened emails, identified invoice documents, determined the appropriate extraction approach based on format and language, keyed data into accounting systems, and routed items through approval chains. The process was slow, opaque, and error-prone at a scale where missed documents and delayed processing had direct financial consequences on trading positions and counterparty relationships.
The Invoice Workflow Automation AI Agent replaced this manual chain with a coordinated multi-agent system. Each agent in the pipeline owns a specific processing stage: email monitoring and document identification, format-aware extraction method selection, multi-language translation, data validation and completeness checking, and decision-based routing into the appropriate accounting system and management review queue. The architecture treats the invoice processing pipeline as an orchestration problem, where each stage's output becomes the next stage's input with decision logic governing the routing between them.
Benefits
This multi-agent system eliminates the operational fragility of email-distributed invoice processing by replacing manual handoffs with coordinated AI agents that maintain processing continuity across the entire pipeline.
- End-to-end pipeline automation: From the moment an invoice arrives in any email inbox through final entry into accounting systems, the agent pipeline handles every processing stage without requiring human intervention on routine documents
- Elimination of document loss: Centralized email monitoring ensures that every invoice attachment is captured and entered into the processing pipeline, resolving the visibility gap where documents sat unprocessed in individual inboxes for days or weeks
- Format-adaptive extraction: The system dynamically selects the optimal extraction method based on document format, language, and structure, achieving high accuracy across the diverse invoice formats that global commodity trading generates
- Reduced processing latency: Automated pipeline stages execute in seconds rather than the hours or days that manual processing required, compressing the time between invoice receipt and accounting system entry from weeks to same-day
- Transparent processing state: Every document in the pipeline has a visible status, current stage, and processing history, replacing the complete opacity of email-based processing where nobody could answer "where is this invoice?"
- Scalable without headcount: Volume increases from new trading partners, markets, or instruments are absorbed by the agent pipeline without requiring proportional increases in operations team size
Problem Addressed
The architectural challenge of email-distributed invoice processing is fundamentally different from centralized inbox processing. When invoices arrive at a single point, the problem is volume management. When they arrive across dozens of individual inboxes throughout an organization, the problem is visibility and coordination. No single person or system can see the full scope of incoming invoices. No dashboard shows the current processing state. When a trading desk asks whether a counterparty invoice has been processed, the answer requires asking multiple people to check their individual email histories.
In commodity trading, this opacity carries financial risk. Invoices reference specific trades, shipments, and contract terms. Delayed processing affects cash flow projections, trading limit calculations, and counterparty credit assessments. When a critical invoice sits unprocessed in someone's inbox because they are traveling, the financial impact extends beyond a late payment. It affects the accuracy of the organization's real-time view of its financial position. The manual process also created quality problems that compounded with scale. Invoices in different languages required ad hoc translation. Documents in unusual formats required judgment calls about extraction approaches. Missing or ambiguous data required back-and-forth with counterparties. Each of these friction points added latency and error potential to a process that the organization needed to be fast and reliable.
What the Agent Does
The system operates as a coordinated multi-agent pipeline where each stage is handled by a specialized AI agent with defined inputs, outputs, and decision logic:
- Email monitoring and document identification: The ingestion agent monitors designated email accounts, identifies invoice documents within attachments and email bodies, separates invoices from non-invoice correspondence, and routes identified documents into the extraction pipeline with sender and timestamp metadata
- Format analysis and extraction method selection: The routing agent analyzes each document's format, structure, and language to dynamically select the optimal extraction approach, choosing between OCR pipelines for scanned documents, structured parsing for digital PDFs, and specialized handlers for non-standard formats
- Multi-language translation: The translation agent detects documents in non-primary languages, produces business-accurate translations preserving financial terminology and numerical precision, and retains both original and translated versions for audit and dispute reference
- Data extraction and validation: The extraction agent pulls structured financial data including amounts, dates, counterparty details, trade references, and payment terms, then validates completeness against configurable business rules that define what constitutes a processable invoice
- Missing data identification and resolution: The validation agent identifies incomplete or ambiguous data fields, generates specific queries for human review or counterparty clarification, and holds documents in a staged state until resolution is provided
- Decision-based accounting system routing: The routing agent applies business rules to determine the appropriate accounting system, cost center, and approval chain for each verified invoice, executing the entry and triggering the correct management review workflow
Standout Features
- Agent coordination protocol: Each agent in the pipeline communicates through a structured handoff protocol that includes processing metadata, confidence scores, and decision rationale, enabling downstream agents to make informed decisions based on the full processing history
- Dynamic extraction strategy: Rather than applying a single OCR or parsing approach to all documents, the system selects extraction methods per-document based on format analysis, achieving higher accuracy across the diverse formats that global operations generate
- Financial terminology translation: The translation component maintains domain-specific vocabulary for commodity trading, financial instruments, and accounting terminology across supported languages, ensuring translations are business-accurate rather than merely linguistically correct
- Staged processing with human-in-the-loop: Documents that require human judgment are staged at the appropriate pipeline point with all available context, allowing targeted human intervention without disrupting the automated flow of documents that do not require it
- Pipeline observability dashboard: Real-time visibility into every agent's processing queue, throughput rate, exception rate, and average latency provides operations management with the data needed to identify bottlenecks and optimize pipeline performance
Who This Agent Is For
This agent is designed for organizations where invoice processing is distributed across multiple email endpoints and the volume, format diversity, and language complexity have made manual coordination untenable.
- Financial services organizations processing invoices from international counterparties across multiple currencies, languages, and document formats
- Commodity trading operations where invoice processing latency affects trading limit calculations and financial position visibility
- Global operations teams managing distributed email-based invoice receipt where document visibility and tracking are primary challenges
- Finance teams seeking to replace manual, error-prone multi-step processing with coordinated automation that maintains audit compliance
- Technology leaders evaluating multi-agent AI architectures for document processing pipelines that require format-adaptive extraction and decision-based routing
Ideal for: Operations directors, finance controllers, technology architects, and enterprise automation leads at commodity trading firms, financial services organizations, and any global operation where email-distributed invoice processing has become a systemic risk to financial accuracy and operational efficiency.

Warehouse Routing Optimization AI Agent
AI agent embedded in operational applications that analyzes real-time warehouse conditions to dynamically recommend optimal conveyor routing, moving decision support from static business rules to adaptive intelligence.
When a cold storage warehouse moves from static routing rules to AI-driven decision support, the result is not incremental improvement. It is a new category of operational capability.
A global leader in temperature-controlled warehousing operates an extensive network of cold storage facilities that serve as critical infrastructure for the food supply chain. Their operational teams already had a custom application that used business rules to manage conveyor routing decisions within their warehouses. The Warehouse Routing Optimization AI Agent represents the next evolution of that capability: embedding AI agents directly into the operational application to analyze real-time conditions and dynamically recommend optimal routing rather than applying static rules. This moves the platform from a reporting and rules engine into an operational decision support system that adapts to conditions as they change.
Benefits
This agent delivers a fundamental upgrade in warehouse operational intelligence, transforming how routing decisions are made and creating measurable improvements in throughput, efficiency, and operational responsiveness.
- Dynamic routing recommendations: Instead of following static rules that cannot account for changing conditions, the AI agent analyzes current warehouse state and recommends routing paths optimized for the specific conditions at that moment, adapting as conditions evolve throughout the shift
- Throughput optimization potential: By routing product through the least congested and most efficient available paths rather than predetermined routes, the agent creates the potential to meaningfully increase warehouse throughput without physical infrastructure changes
- Operational decision support at the point of action: Recommendations are delivered directly within the operational application that warehouse teams already use, eliminating the gap between insight and action that exists when analytics and operations live in separate systems
- Reduced bottleneck duration: The agent detects developing congestion and recommends rerouting before bottlenecks fully form, converting what were previously reactive adjustments into proactive avoidance that keeps product flowing continuously
- Temperature compliance protection: In cold storage environments where routing delays can create temperature excursion risks, faster and smarter routing decisions directly protect product quality and regulatory compliance
- Frontline team empowerment: Warehouse workers receive AI-backed routing guidance that incorporates more variables than any individual operator could track simultaneously, improving decision quality without requiring expertise in optimization
Problem Addressed
Large-scale warehousing operations face a routing complexity problem that static business rules cannot solve optimally. A temperature-controlled warehouse with dozens of conveyor paths, multiple loading zones, varying product types with different temperature requirements, and fluctuating inbound and outbound volumes creates a combinatorial routing challenge that changes minute by minute. Static rules handle the typical case but fail to adapt when conditions deviate: when a dock door is delayed, when a high-priority outbound order arrives, when a conveyor section goes down for maintenance, or when inbound volume spikes on certain lanes.
The operational teams know how to handle these situations individually, but the number of simultaneous variables exceeds what any person can optimize in real time. An experienced warehouse manager might reroute product away from a congested zone, but they cannot simultaneously account for the downstream impact on three other zones, the temperature exposure implications, and the priority sequencing of outbound orders. The gap is not between knowing and not knowing. It is between human cognitive capacity and the complexity of real-time multi-variable optimization in a dynamic physical environment. AI agents embedded in the operational application can bridge that gap by continuously analyzing all relevant variables and surfacing routing recommendations that account for the full state of the warehouse.
What the Agent Does
The agent operates as an AI layer within the existing operational application, continuously analyzing warehouse conditions and producing routing recommendations that frontline teams can execute immediately:
- Real-time condition monitoring: Ingests operational data from warehouse management systems, conveyor sensors, dock scheduling systems, and inventory management platforms to maintain a current picture of warehouse state across all zones and conveyor paths
- Multi-variable optimization: Analyzes current conveyor utilization, zone congestion levels, product type requirements, temperature zones, outbound priority sequences, and available path options simultaneously to identify optimal routing for each product flow
- Dynamic recommendation generation: Produces specific routing recommendations that adapt to changing conditions, updating as new orders arrive, congestion patterns shift, dock schedules change, or equipment status updates are received
- Business rule integration: Layers AI recommendations on top of existing business rules rather than replacing them, respecting hard constraints such as temperature zone requirements, product segregation rules, and safety protocols while optimizing within those boundaries
- Embedded application delivery: Surfaces recommendations directly within the custom operational application that warehouse teams use for daily operations, presenting guidance in the workflow context where routing decisions are made
- Outcome tracking: Monitors the results of implemented routing recommendations to measure throughput impact, congestion reduction, and compliance improvements, creating a feedback loop that validates and improves recommendation quality
Standout Features
- Embedded operational AI: Unlike analytics tools that generate reports for later review, this agent delivers recommendations within the operational application at the moment decisions are being made, closing the gap between insight and action completely
- Cold chain awareness: The agent understands that routing decisions in temperature-controlled environments have quality and compliance implications beyond throughput, factoring temperature exposure time into every recommendation
- Constraint-respectful optimization: The AI operates within the boundaries of existing business rules and safety protocols, augmenting rather than overriding the operational framework that warehouse teams trust and compliance requires
- Congestion prediction: Beyond reacting to current congestion, the agent projects forward based on inbound schedules, outbound commitments, and historical patterns to recommend preemptive routing adjustments before bottlenecks develop
- Scalable architecture: The agent framework is designed to deploy across multiple warehouse facilities, learning facility-specific patterns while sharing optimization strategies that improve performance network-wide
Who This Agent Is For
This agent is designed for warehouse and logistics operations where routing complexity exceeds what static business rules can optimize and where the speed of operational decisions directly impacts throughput, product quality, and customer service levels.
- Warehouse operations managers at large-scale distribution centers who need to optimize conveyor and product routing across complex facility layouts with multiple zones and constraints
- Cold chain logistics operators where routing decisions have direct temperature compliance and product quality implications that static rules cannot dynamically account for
- Supply chain technology leaders seeking to embed AI decision support directly into existing operational applications rather than building standalone analytics tools
- Frontline warehouse supervisors who need intelligent routing guidance that accounts for more variables simultaneously than manual decision-making can process
- Operations executives at multi-facility logistics companies looking to standardize and optimize routing intelligence across their warehouse network
Ideal for: Warehouse directors, logistics operations managers, supply chain technology leaders, cold chain compliance officers, and any warehousing operation where dynamic routing optimization represents a meaningful throughput and efficiency opportunity.

Invoice Attestation AI Agent for Supply Chain
AI-powered invoice attestation agent designed for high-volume supplier networks, automating verification, matching, and approval workflows within NetSuite ERP for supermarket, hypermarket, and distribution operations managing thousands of monthly supplier invoices.
If you have ever stared at a stack of 500 supplier invoices on a Monday morning and wondered how your team is supposed to get through them all by Friday, this agent was built for you.
A leading supermarket and hypermarket chain operating dozens of locations across a national footprint was processing thousands of supplier invoices every month. The accounts payable team knew the drill. Invoices arrived from hundreds of suppliers in every format imaginable. Each one needed to be matched against purchase orders, checked for quantity and pricing accuracy, routed to the right approver, and processed for payment. The team was good at their jobs. They had systems, they had checklists, they had institutional knowledge about which suppliers always rounded up and which ones frequently sent duplicates. But institutional knowledge does not scale. When you add twenty new suppliers in a quarter and transaction volume jumps 30% during a holiday season, the human processes that worked last year become the bottleneck this year.
The Invoice Attestation AI Agent was deployed within the existing NetSuite environment to handle the verification and routing work that consumed the majority of the AP team's time. It does not replace the team. It handles the repetitive matching and checking that the team was doing manually, so they can focus on the exceptions, the disputes, and the vendor relationships that actually require human judgment. Here is how it works in practice, from the perspective of someone who uses it every day.
Benefits
This agent changes the daily reality for accounts payable teams managing high-volume supplier invoicing, replacing the manual grind with automated processing that handles routine verification and surfaces only the items that need human attention.
- End the Monday morning backlog: Invoices that arrived over the weekend are already verified and routed by the time the AP team logs in, eliminating the weekly cycle of catching up that consumed the first two days of every work week
- Stop chasing approvers: Automated routing with escalation timers means invoices move through the approval chain without AP staff having to send reminder emails, make follow-up calls, or track down managers in meetings
- Catch the duplicates you miss: The AI spots duplicate invoices that look different enough to fool human review, including resubmissions with new invoice numbers, slightly adjusted amounts, and reformatted layouts from the same supplier
- Protect supplier relationships: Consistent, timely payment processing keeps suppliers happy and eliminates the uncomfortable conversations about overdue invoices that were actually stuck in an internal approval queue
- Reclaim your expertise: AP professionals spend their time on dispute resolution, vendor negotiations, and process improvements instead of the data entry and document matching that wasted their skills
- Sleep through month-end close: Clean, verified, fully documented invoice data means month-end reconciliation no longer requires weekend overtime to resolve the discrepancies that accumulated during normal processing
Problem Addressed
Here is what a typical day looks like for an AP specialist at a high-volume retail operation. You open your email and there are 47 new invoices. You open the vendor portal and there are another 23. You check the shared mailbox and find 12 more that were forwarded by other departments. You open NetSuite and start matching. The first invoice matches cleanly. The second one has a price discrepancy on line item 7. You flag it, make a note, and move to the next one. The third invoice references a PO number that you cannot find. You email purchasing. The fourth one is from a supplier who always sends invoices in a format that your OCR tool cannot read properly, so you type in the data manually. By 11am, you have processed 15 invoices and spent most of your time on the exceptions rather than the routine matches.
Now multiply this across a team of four people handling invoices from hundreds of suppliers across multiple store locations, each with their own delivery schedules, pricing agreements, and invoicing quirks. The volume is manageable most of the time. But during promotional periods, holiday seasons, and new store openings, it spikes dramatically. The same team that keeps pace during normal weeks falls behind during peak periods, and the backlog that builds during those spikes takes weeks to clear. Meanwhile, suppliers whose invoices are stuck in the queue start calling to ask about payment status. The AP team spends time on those calls instead of processing invoices, which makes the backlog worse. It is a cycle that every high-volume AP team recognizes, and it does not get better without a fundamental change to how routine verification is handled.
What the Agent Does
The agent handles the end-to-end invoice verification workflow within NetSuite, taking over the repetitive processing that consumed the majority of AP team time:
- Collects invoices from everywhere: The agent pulls invoices from email attachments, vendor portal downloads, scanned documents, and direct system uploads into a single processing queue, ending the scattered multi-source collection that required AP staff to check five different places every morning
- Reads any invoice format: Whether a supplier sends a clean PDF, a photographed receipt, or a formatted spreadsheet, the agent extracts line items, amounts, dates, PO references, and payment terms into a consistent data structure without manual data entry
- Matches against purchase orders automatically: Every extracted invoice is matched against the corresponding PO in NetSuite, checking quantities, unit prices, and totals across all line items with tolerance thresholds that account for the normal variances in high-volume procurement
- Routes to the right approver instantly: Clean matches are routed to the designated approver based on amount, category, and location, with configurable escalation if approval does not happen within the defined window
- Queues exceptions with full context: When an invoice does not match, the agent creates a detailed exception report showing exactly what did not align, what the PO says, what the invoice says, and what the likely resolution options are
- Tracks everything for audit: Every step from ingestion through approval is logged with timestamps, confidence scores, and decision details, creating the documentation that auditors request and manual processes rarely produce
Standout Features
- Supplier learning profiles: The agent builds profiles for each supplier's invoicing patterns, learning their formats, common discrepancies, and seasonal volume changes so that matching accuracy improves over time and known quirks are handled automatically
- Volume spike absorption: During promotional periods and seasonal peaks, the agent handles double or triple the normal volume without slowing down or requiring temporary AP staff, maintaining the same processing speed and accuracy regardless of volume
- Real-time team dashboard: AP managers see live processing status, exception queues, approval bottlenecks, and projected payment obligations in a single view, replacing the spreadsheet tracking that previously required daily manual updates
- Multi-location consolidation: Invoices from suppliers delivering to multiple store locations are consolidated and reconciled against the corresponding POs for each location, handling the complexity of multi-drop shipments that manual processes frequently misallocate
- Proactive cash flow alerts: The agent surfaces upcoming large payment obligations, discount deadline windows, and unusual spending patterns before they become surprises, giving finance teams the lead time to manage cash flow proactively
Who This Agent Is For
This agent is built for AP teams and finance operations at retail, grocery, and distribution companies where supplier invoice volume has outgrown the team's capacity for manual processing.
- Accounts payable specialists who spend most of their day on invoice data entry and PO matching instead of the exception handling and vendor management work they were hired to do
- AP managers overseeing teams that consistently fall behind during peak volume periods and spend the following weeks clearing backlogs
- Finance directors at supermarket, hypermarket, and multi-location retail chains where supplier count and invoice volume grow with every new location
- Procurement teams that need clean, timely invoice processing to maintain supplier relationships and capture favorable payment terms
- CFOs and controllers seeking to reduce AP processing costs while improving accuracy, compliance documentation, and payment cycle performance
Ideal for: AP team leads, finance managers, procurement directors, and operations executives at grocery, supermarket, hypermarket, and multi-location retail organizations where the daily reality of high-volume invoice processing has become the biggest bottleneck in financial operations.
Production Yield Review AI Agent
AI agent that analyzes intraday production data to detect yield rate declines in real time, pinpointing the exact timing and production floor location of issues so management can investigate root causes immediately.
Yield dropped at 2:15 PM on Line 3. By the time the end-of-shift report surfaced the problem, four hours of substandard product had already been produced.
In manufacturing environments where yield rates directly determine profitability, the difference between detecting a decline at 2:15 PM and discovering it in the next morning's report is not a matter of convenience. It is the difference between a contained issue and a significant production loss. A private investment group managing portfolio companies in the manufacturing sector faced this problem across its operations. Production yield data existed, but it was reviewed in aggregate after the fact. When yield fell below expectations during a shift, the decline was often invisible until hours or even a full day later, by which point the root cause investigation was working from cold information and the wasted production could not be recovered.
Benefits
This agent transforms yield monitoring from a retrospective reporting exercise into a real-time detection system that gives management the information they need to act while the problem is still happening.
- Real-time decline detection: Yield drops are identified as they occur during the production shift rather than in post-shift or next-day reporting, compressing the response time from hours to minutes and limiting the volume of substandard output
- Precise temporal pinpointing: The agent identifies the specific time window when yield began declining, giving investigators a narrow range to examine rather than an entire shift's worth of variables, dramatically reducing the time to isolate root cause
- Production floor location mapping: Each detected decline is associated with a specific production line, station, or zone, directing management attention to the exact physical location where the issue is occurring rather than requiring floor-wide investigation
- Reduced scrap and rework costs: Earlier detection means fewer units produced during the decline period, directly reducing the material waste, rework labor, and schedule disruption that accumulate when yield problems run undetected
- Shift-level accountability: Real-time visibility into yield performance creates a factual record of when issues started and how quickly they were addressed, supporting both operational accountability and continuous improvement discussions
- Pattern recognition across shifts: Aggregated detection data reveals recurring yield issues tied to specific times, lines, products, or operating conditions, enabling preventive action on systemic problems rather than repeated reactive investigation
Problem Addressed
Walk onto any manufacturing floor and ask the production manager when yield last dropped below target. If they are relying on traditional reporting, the honest answer is: I will know tomorrow. Intraday yield data is being collected by the production systems, but the aggregation, analysis, and alerting infrastructure treats it as reporting data rather than operational data. Reports are generated at the end of the shift or the end of the day. Dashboards update on refresh cycles that may lag by hours. The data that could tell a manager at 2:15 PM that Line 3 yield dropped below the control limit at 2:12 PM is instead compiled into a summary that she reads at 7:00 AM the next morning.
The cost of this delay is concrete and measurable. Every minute that a yield decline runs undetected produces units that will be scrapped, reworked, or shipped at reduced margin. In high-volume manufacturing, four hours of undetected yield decline on a single line can represent tens of thousands of dollars in lost production value. But the problem extends beyond the immediate financial impact. When the investigation begins the next day, the operating conditions that caused the decline have changed. The operator who noticed something unusual has gone home. The material batch that may have been the source has been consumed. The environmental conditions have shifted. Investigating a yield decline twelve hours after it occurred is forensics. Investigating it twelve minutes after it occurred is operations management. This agent exists to make the latter possible.
What the Agent Does
The agent operates as a continuous yield surveillance system that monitors intraday production data and triggers immediate alerts when performance deviates from expected levels:
- Intraday data stream monitoring: Connects to production data systems to ingest yield metrics at sub-shift granularity, processing measurements from individual production lines, stations, and product runs as they are recorded rather than waiting for batch reporting cycles
- Statistical baseline comparison: Maintains dynamic yield baselines for each production line and product combination, accounting for expected variation by product type, shift, day of week, and seasonal factors to distinguish genuine declines from normal production variability
- Decline detection and timing: Applies change-point detection algorithms to identify the specific moment when yield performance deviates from its expected trajectory, establishing a precise timestamp for when the decline began
- Floor location identification: Maps detected declines to their physical origin on the production floor, identifying the specific line, station, cell, or zone where the yield issue is occurring based on the data source topology
- Severity assessment: Evaluates the magnitude of each detected decline relative to the baseline and the product's margin sensitivity, prioritizing alerts so that management attention focuses on the declines with the greatest financial impact
- Alert delivery with context: Notifies designated management personnel with a structured alert containing the decline timing, location, magnitude, affected product, and recent operating condition context to enable immediate investigation
Standout Features
- Sub-shift granularity: The agent operates at a temporal resolution measured in minutes rather than shifts or days, detecting yield changes that would be smoothed out in traditional hourly or shift-level reporting aggregation
- Context-aware baselining: Rather than using a single yield target, the agent maintains baselines that account for the specific product, line, shift, and operating conditions, reducing false positives from expected yield variation across different production scenarios
- Investigation acceleration: Each alert packages the information that investigators need to begin root cause analysis immediately, including the timing window, location, affected product specifications, and any correlated changes in adjacent production parameters
- Cross-line correlation: When yield declines occur simultaneously on multiple lines, the agent flags the correlation, suggesting a shared root cause such as a material batch issue, environmental change, or utility disruption rather than independent line-level problems
- Historical pattern library: Detected declines are cataloged with their eventual root causes, building an institutional knowledge base that accelerates future investigations when similar patterns recur
Who This Agent Is For
This agent is built for manufacturing operations where yield rate directly impacts profitability and where the delay between a yield decline occurring and management becoming aware of it represents measurable financial loss.
- Production managers responsible for maintaining yield targets across multiple lines who cannot physically monitor every station simultaneously during a shift
- Plant directors at manufacturing operations where yield variability is a primary driver of margin performance and where early detection of declines prevents significant waste
- Quality assurance teams that need real-time visibility into production quality metrics to trigger in-process inspection and containment actions before affected product progresses further
- Continuous improvement engineers who need precise temporal and spatial data on yield events to perform effective root cause analysis and implement lasting corrective actions
- Portfolio company operators managing multiple manufacturing sites who need standardized, automated yield monitoring that does not depend on individual site reporting practices
Ideal for: Plant managers, production supervisors, quality directors, continuous improvement leads, and any manufacturing operation where the cost of a four-hour undetected yield decline justifies the investment in real-time detection.

Invoice Attestation AI Agent for Retail
AI-powered invoice attestation agent that integrates with NetSuite ERP to automate verification, purchase order matching, and approval workflows for outdoor retail and specialty commerce operations with growing transaction volumes.
70% faster invoice processing. Zero duplicate payments. Every early payment discount captured. These are not projections. These are the results when AI replaces manual attestation.
A specialty outdoor recreation retailer had built its business on curating the best equipment from hundreds of suppliers. As transaction volumes grew alongside the business, the accounts payable team found themselves drowning in a tide of vendor invoices that arrived in every conceivable format: paper, PDF, email, and vendor portal downloads. Each invoice needed to be opened, matched against the corresponding purchase order, verified for correct quantities and pricing, and routed to the appropriate approver. The process that once took a small team a few hours per week now consumed entire days, and the backlog kept growing.
The Invoice Attestation AI Agent transformed this operation by automating the entire verification and approval workflow within NetSuite. Purchase orders, receiving documents, and vendor invoices are now matched automatically. Discrepancies are flagged instantly rather than discovered during month-end reconciliation. Approval routing happens in seconds based on business rules rather than waiting for someone to forward an email. The result is not incremental improvement. It is a fundamental restructuring of how the finance team spends its time.
Benefits
This agent delivers measurable financial and operational results from the first month of deployment, transforming accounts payable from a cost center bottleneck into an automated, exception-driven operation.
- 70% reduction in invoice processing time: Automated PO matching, verification, and routing compress the attestation cycle from days to hours, processing the same volume that previously required a dedicated team
- 100% early payment discount capture: Accelerated processing ensures every invoice is approved within vendor discount windows, recovering revenue that was previously forfeited to processing delays
- Zero duplicate payments: AI-powered duplicate detection catches identical and near-identical invoices across formatting variations, vendor resubmissions, and timing overlaps that manual review consistently misses
- Improved vendor relationships: Consistent, timely payments and transparent processing status eliminate the vendor inquiry calls that consumed AP team time and created friction with critical suppliers
- Freed finance capacity: Staff previously dedicated to invoice data entry and manual matching focus on exception resolution, vendor negotiations, and financial analysis that drive business value
- Audit-ready documentation: Every verification step, match decision, and approval action is logged with full audit trails, eliminating the documentation gaps that create risk during financial audits
Problem Addressed
Retail businesses face a specific accounts payable challenge that intensifies with growth. Unlike service companies that might process a few large invoices per month, retailers manage high volumes of smaller transactions from many suppliers. Each purchase order might cover dozens of line items. Each delivery might be partial. Each invoice might reference multiple POs. And each vendor uses their own invoice format, numbering convention, and payment terms. The combinatorial complexity of matching all of these moving parts manually creates a system that is fragile by design.
When an outdoor equipment retailer processes invoices from 200 suppliers, each with monthly billing cycles and seasonal volume spikes, the AP team faces a verification workload that scales faster than headcount. During peak buying seasons, invoice volume doubles or triples while the team size stays constant. The result is a backlog that cascades through the entire financial operation: late payments strain vendor relationships, missed discounts reduce margins, and month-end close extends because reconciliation requires cleaning up the errors that accumulated during high-volume periods. The problem is not complexity per invoice. It is the aggregate volume of relatively straightforward verification tasks that overwhelms human processing capacity.
What the Agent Does
The agent automates the complete invoice attestation lifecycle within NetSuite, from document receipt through approval and payment scheduling:
- Multi-format invoice capture: The agent ingests invoices from email attachments, vendor portals, scanned documents, and direct system uploads, parsing structured data from any format without requiring vendor-specific templates or manual data entry
- Three-way matching engine: Each invoice is automatically matched against the corresponding purchase order and receiving document, verifying quantities received, unit prices agreed, and total amounts calculated across all line items
- Tolerance-based verification: Configurable matching tolerances accommodate the real-world variances in retail procurement including quantity overages within accepted thresholds, freight charge variations, and tax calculation differences
- Automated approval routing: Verified invoices route to designated approvers based on amount thresholds, department codes, and vendor classifications, with escalation paths for invoices that exceed normal parameters
- Exception queuing with context: Invoices that fail automated matching are queued with detailed exception reports showing exactly which line items failed verification and what discrepancy was detected
- Payment scheduling optimization: Approved invoices are scheduled for payment based on configured rules that balance early payment discount capture against cash flow management objectives
Standout Features
- Seasonal volume handling: The agent scales automatically during peak buying seasons, processing double or triple normal invoice volumes without degradation in speed or accuracy, eliminating the seasonal backlog that plagued manual operations
- Partial delivery reconciliation: Sophisticated matching handles the partial shipments common in retail procurement, tracking received quantities across multiple deliveries against a single PO and matching partial invoices accordingly
- Vendor performance analytics: Processing data generates vendor scorecards covering invoice accuracy, format consistency, payment term compliance, and dispute frequency, giving procurement teams actionable data for vendor negotiations
- Return and credit memo processing: The agent handles the full cycle including returns, credit memos, and debit adjustments, automatically applying credits against outstanding invoices and flagging discrepancies in vendor-issued adjustments
- Cash flow impact forecasting: Real-time visibility into the approval pipeline provides accurate AP forecasts, showing finance teams exactly what payment obligations are coming and when, replacing the uncertainty of manual tracking
Who This Agent Is For
This agent is designed for retail and specialty commerce organizations where growing transaction volumes have created a gap between invoice processing capacity and business requirements.
- Accounts payable teams at retail companies processing invoices from hundreds of product suppliers with diverse formats and terms
- Finance directors at growing retailers where AP headcount has not kept pace with transaction volume increases
- Procurement teams seeking data-driven vendor management powered by automated processing analytics
- NetSuite-based retail operations looking for AP automation that works within their existing ERP without platform migration
- CFOs targeting working capital optimization through systematic early payment discount capture and payment timing management
Ideal for: AP managers, controllers, procurement directors, and finance executives at specialty retail, outdoor recreation, sporting goods, and consumer products companies where the margin impact of missed discounts, duplicate payments, and vendor relationship friction justifies automation investment.

Cybersecurity Threat Briefing AI Agent
AI agent that analyzes cybersecurity threat data from online banking systems, identifies the top monthly attack vectors, and automatically generates a member-facing email newsletter with practical risk mitigation guidance.
The threat data was already being collected internally. The question was how to turn defensive telemetry into proactive member protection at scale.
A community financial institution supporting thousands of online banking members faced a challenge that many security teams recognize: they had extensive data on the attack methods targeting their systems, but that intelligence stayed locked inside the security operations team. Members, the people most vulnerable to phishing, credential stuffing, and social engineering, received generic security advice that did not reflect the specific threats actually hitting their institution's systems. The Cybersecurity Threat Briefing AI Agent was built to bridge that gap. It ingests the institution's own threat data, identifies the most prevalent attack methods each month, and generates a structured, plain-language email newsletter that transforms internal defensive intelligence into actionable member guidance.
Benefits
This agent converts internal security telemetry into a proactive member service that builds trust while measurably reducing the institution's attack surface through educated member behavior.
- Threat-specific member education: Instead of generic security tips, members receive guidance based on the actual attack methods targeting their institution's systems that month, making every recommendation immediately relevant to their real risk exposure
- Automated monthly production cycle: The newsletter generation process runs autonomously from data analysis through draft production, eliminating the manual effort that previously made regular security communications unsustainable for a small security team
- Proactive trust building: Members perceive the institution as actively protecting them rather than merely reacting to breaches, strengthening the trust relationship that is foundational to community financial institution membership
- Reduced member-side vulnerability: Practical, threat-specific guidance helps members recognize and avoid the exact attack patterns currently in circulation, reducing successful phishing, credential theft, and social engineering incidents
- Security team force multiplication: A team that previously could not justify the hours required for monthly member communications now delivers consistent, high-quality security briefings without diverting resources from core defensive operations
- Regulatory alignment: Regular, documented member security education supports compliance with financial industry regulations that require institutions to demonstrate proactive efforts to protect customer accounts and personal information
Problem Addressed
Financial institutions collect enormous volumes of threat data through firewalls, intrusion detection systems, authentication logs, and fraud monitoring platforms. Security teams analyze this data to harden systems, patch vulnerabilities, and block attack vectors. But the vast majority of successful attacks against consumer banking accounts do not exploit technical vulnerabilities in the institution's infrastructure. They exploit the members themselves. Phishing emails that mimic the institution's login page. Social engineering calls that reference real account details. Credential stuffing attacks using passwords the member reused from a compromised retail site.
The security team knows exactly which attack methods are trending because they see them in the data every day. Members know none of this. They receive the same generic security advice they have seen for years: use strong passwords, do not click suspicious links, enable two-factor authentication. That advice is not wrong, but it is not specific enough to change behavior. When the security team observes a surge in SMS phishing attempts that impersonate package delivery notifications and redirect to credential harvesting pages, that specific, actionable intelligence never reaches the members who are receiving those texts. The data exists to protect members proactively. The missing piece was a system to transform that data into communications automatically, consistently, and at a quality level that members actually read.
What the Agent Does
The agent operates as an automated intelligence-to-communication pipeline that transforms raw threat data into structured, member-appropriate security briefings:
- Threat data ingestion: Connects to the institution's security monitoring systems and online banking portal activity logs to collect data on attempted attacks, blocked threats, authentication anomalies, and fraud patterns over the analysis period
- Attack method classification: Categorizes observed threats by attack vector type, including phishing variants, credential attacks, social engineering methods, malware delivery mechanisms, and account takeover techniques, and ranks them by prevalence and member impact potential
- Top threat identification: Selects the three most significant threats for the current period based on a composite score of frequency, success rate, member exposure, and novelty, ensuring the newsletter focuses on the risks that matter most right now
- Plain-language translation: Transforms technical threat descriptions into clear, non-technical explanations that members can understand and act on, including specific examples of what the attack looks like, how to recognize it, and what to do if encountered
- Practical recommendation generation: Produces concrete, step-by-step protective actions for each highlighted threat, calibrated to the technical sophistication of a general consumer audience rather than security professionals
- Newsletter assembly and formatting: Composes the complete email newsletter with consistent branding, structured sections for each threat, and a professional tone that communicates urgency without creating panic
Standout Features
- Real threat data, not hypotheticals: Every newsletter is grounded in the institution's actual threat telemetry from the preceding month, ensuring that the threats discussed are the ones members are genuinely encountering rather than theoretical risks pulled from industry reports
- Workflow-driven automation: The entire pipeline from data analysis through newsletter generation is orchestrated through automated workflows that execute on schedule without requiring security team initiation, review queue placement, or manual data extraction
- Adaptive threat prioritization: The selection algorithm adjusts for threat novelty, so a new attack type that appears for the first time receives elevated priority even at lower volume, while persistent threats that were covered in recent newsletters are deprioritized to avoid repetitive content
- Member-calibrated language: The agent's output is specifically tuned for consumer financial services members, avoiding both the oversimplification that makes security advice feel patronizing and the technical jargon that makes it incomprehensible to non-specialists
Who This Agent Is For
This agent is designed for financial institutions and member-serving organizations that possess internal threat data and want to transform it into a proactive member protection service without adding headcount to the security team.
- Information security teams at community banks and credit unions who lack the staff to produce regular member-facing security communications manually
- Member services and communications teams seeking content that is grounded in real threat data rather than recycled generic security advice
- Compliance officers at financial institutions who need documented evidence of proactive member security education for regulatory examinations
- Chief information security officers looking to extend the value of their threat intelligence investment beyond internal defensive operations into member-facing protection
- Any financial institution where phishing, social engineering, and credential attacks represent a significant and growing source of member account compromise
Ideal for: CISOs, security operations leads, member communications managers, compliance officers, and any community financial institution that recognizes member education as a critical layer of defense and needs an automated way to deliver it consistently.

Invoice Attestation AI Agent for Telecom
AI-driven invoice attestation agent integrated with NetSuite ERP that automates verification, matching, and approval workflows for telecommunications companies processing high volumes of vendor invoices across global connectivity operations.
Every month, the same ritual. Hundreds of invoices land in inboxes across the finance team. Each one needs to be opened, read, cross-referenced, and approved before a vendor gets paid.
For a global telecommunications provider delivering connectivity solutions to businesses worldwide, this ritual had become a crisis of scale. The company's financial operations processed invoices from hundreds of vendors across multiple geographies, currencies, and contract structures. Each invoice required human eyes to verify amounts against purchase orders, confirm service delivery, validate payment terms, and route to the appropriate approver. The manual process that worked when the company had fifty vendors collapsed under the weight of five hundred. Invoices sat in email inboxes for days. Approvers forgot to respond. Duplicate payments went undetected until reconciliation. Early payment discounts expired because the attestation process took longer than the discount window. The finance team was not incompetent. They were overwhelmed.
Benefits
This agent eliminates the manual bottleneck in invoice processing by automating the verification, matching, and approval workflow that previously consumed significant finance team bandwidth.
- Dramatic reduction in processing time: Invoices that previously required 20-30 minutes of manual review per document are verified and routed in seconds, compressing the end-to-end attestation cycle from days to hours
- Elimination of duplicate payments: AI-powered matching detects duplicate invoices across vendors, time periods, and formatting variations that human reviewers consistently miss during high-volume processing periods
- Recovery of early payment discounts: Accelerated attestation ensures invoices are approved within vendor discount windows that were previously missed due to processing delays, directly recovering revenue
- Reduced error rates in verification: Automated cross-referencing against purchase orders and contracts catches discrepancies in amounts, quantities, and terms with higher accuracy than manual review under time pressure
- Freed finance capacity: Staff previously dedicated to invoice review are redirected to exception handling, vendor relationship management, and financial analysis work that requires human judgment
- Complete audit trail: Every verification decision, match result, and routing action is logged with timestamps, creating the documentation trail that manual processes rarely produce consistently
Problem Addressed
There is a specific moment when manual invoice processing breaks. It is not a gradual decline. It is a threshold. Below a certain volume, a skilled accounts payable team can keep pace with incoming invoices, verify each one against the relevant purchase order, and route it for approval within a reasonable window. Above that threshold, the queue grows faster than the team can process it. Invoices stack up. Approvers receive batches so large that urgent items get buried. Payment terms expire. Vendors call to ask about overdue payments that are not overdue but rather stuck in an attestation backlog that nobody outside the AP team can see.
For telecommunications companies, this threshold arrives earlier than expected because of the complexity of their vendor relationships. Connectivity providers maintain contracts with infrastructure partners, hardware vendors, spectrum licensors, colocation facilities, and managed service providers, each with different invoicing formats, payment terms, and verification requirements. A single vendor might submit invoices in multiple currencies across different subsidiaries. Two invoices from different vendors might reference the same underlying service delivery. The verification task is not just matching a number on an invoice to a number on a purchase order. It is understanding the full context of a financial obligation across a web of interconnected contracts and service agreements. When that understanding depends entirely on human memory and manual document lookup, errors are not occasional. They are structural.
What the Agent Does
The agent operates as an end-to-end invoice attestation pipeline within the NetSuite ERP environment, automating every stage from receipt through approval routing:
- Invoice ingestion and parsing: The agent monitors incoming invoice channels including email attachments, vendor portals, and direct system uploads, extracting structured data from PDFs, images, and electronic invoice formats regardless of vendor-specific layouts
- Purchase order matching: Extracted invoice data is automatically cross-referenced against open purchase orders in NetSuite, matching line items, quantities, unit prices, and total amounts with configurable tolerance thresholds for rounding and currency conversion differences
- Contract term validation: The agent verifies that invoiced amounts, payment terms, and service periods align with the governing contract, flagging discrepancies that require human review before approval can proceed
- Duplicate detection: AI analysis identifies potential duplicate invoices across the full invoice history, catching duplicates that arrive with different invoice numbers, slightly different amounts, or reformatted layouts from the same vendor
- Intelligent approval routing: Verified invoices are automatically routed to the appropriate approver based on amount thresholds, cost center assignments, and organizational delegation rules configured in the system
- Exception management: Invoices that fail automated verification are queued with detailed exception reports explaining exactly which checks failed and what information is needed to resolve the discrepancy, enabling focused human intervention
Standout Features
- Multi-format invoice parsing: The agent handles PDF, scanned image, XML, EDI, and email-body invoices with equal reliability, normalizing data from any vendor format into a consistent internal structure without requiring vendor-specific templates
- Configurable tolerance matching: Verification thresholds for amounts, quantities, and dates are configurable per vendor, per contract, and per cost center, accommodating the real-world complexity of vendor relationships where exact matches are the exception
- Learning from exceptions: Resolution patterns from manually handled exceptions feed back into the verification model, so recurring exception types that follow consistent resolution patterns are automatically handled in future cycles
- Currency-aware processing: The agent handles multi-currency invoices natively, applying exchange rates at the transaction date and reconciling amounts across the base currency equivalents that NetSuite uses for reporting
- Real-time processing visibility: A dashboard provides live status of every invoice in the pipeline, showing current stage, time in queue, blocking issues, and projected completion, replacing the opacity of the manual process
Who This Agent Is For
This agent is designed for finance and accounts payable teams in telecommunications and technology companies where invoice volume and vendor complexity have outgrown manual processing capacity.
- Accounts payable teams processing hundreds or thousands of vendor invoices per month across multiple formats and currencies
- Finance controllers seeking to reduce processing costs while improving verification accuracy and audit compliance
- Telecommunications companies managing complex vendor ecosystems with infrastructure, hardware, and service provider invoices
- NetSuite-based organizations looking to automate AP workflows without replacing their existing ERP platform
- Operations leaders targeting payment cycle reduction to capture early payment discounts and improve vendor relationships
Ideal for: AP managers, finance directors, controllers, and operations executives at telecommunications companies where the cost of manual invoice processing includes not just labor but also duplicate payments, missed discounts, and audit risk that scale with volume.

Financial Narrative Generation AI Agent
AI workflow that analyzes dashboard data across financials, inventory, contracts, and recovery metrics to generate professional executive commentary with configurable analysis prompts and a built-in configuration interface.
You have built the dashboards. The data is clean. Now someone has to look at forty of them and write the executive summary. That is the bottleneck this agent eliminates.
If you manage reporting for an equipment rental and finance operation, you know the monthly cycle. Dozens of dashboards covering revenue, utilization, contract pipeline, inventory aging, recovery rates, and regional breakdowns. Each one tells a piece of the story, but the executive team does not want pieces. They want the narrative: what happened, why it matters, and what to watch next month. An analyst spends days reviewing every dashboard, cross-referencing trends, and drafting professional commentary that synthesizes the story across all of those data views into a coherent report. The Financial Narrative Generation AI Agent was built to handle that synthesis step, analyzing dashboard data and producing draft narrative commentary that the analyst reviews and refines rather than writing from scratch.
Benefits
This agent changes the analyst's role from writer to editor, dramatically accelerating the monthly reporting cycle while maintaining the professional quality that executive audiences expect.
- Days of analyst time recovered monthly: The manual process of reviewing dozens of dashboards and drafting narrative commentary is compressed from days to hours, with the agent producing initial drafts that analysts refine rather than create from blank pages
- Consistent analytical coverage: Every dashboard in the reporting scope receives narrative attention every month, eliminating the coverage gaps that occur when analysts under time pressure focus on familiar metrics and skim over others
- Configurable analysis prompts: Business users control what the agent looks for and how it frames insights through a configuration interface, allowing the analytical focus to evolve with business priorities without requiring technical changes
- Cross-metric trend synthesis: The agent connects trends across different metric domains, identifying relationships between, for example, contract pipeline changes and inventory positioning that an analyst reviewing dashboards sequentially might not connect
- Professional-grade output: Generated narratives follow executive reporting conventions with appropriate hedging, context, and forward-looking language that reads like it was written by a senior analyst, not a template engine
- Scalable reporting capacity: Adding new dashboards or metrics to the monthly report no longer increases the analyst burden proportionally, enabling the reporting scope to grow with the business without adding headcount
Problem Addressed
Here is what the monthly close looks like in practice. The data lands in the dashboards by the third business day. An experienced analyst opens the first dashboard, notes that revenue is up 4% but that the increase is concentrated in two regions while a third is flat. She opens the next dashboard and sees that utilization rates in the flat region have declined, which might explain the revenue stagnation. She opens the inventory dashboard and discovers that the flat region has the oldest average fleet age. Now she has a thread to pull, but she has thirty-seven more dashboards to review before she can write the narrative that connects all of these observations.
The problem is not complexity. The analysts are skilled and they understand the business. The problem is time. Writing professional narrative commentary that synthesizes dozens of data views into a coherent story for executive consumption takes days of focused work. During that time, the analysts are unavailable for ad-hoc analysis, strategic projects, or the deeper investigations that the narrative itself often suggests. And the report has a deadline. If the narrative is not ready by the executive meeting, the dashboards go out without context, and executives draw their own conclusions from charts without the analytical framing that prevents misinterpretation.
What the Agent Does
The agent operates as an AI-powered narrative layer that sits on top of existing dashboards and reporting infrastructure, analyzing the underlying data and producing professional commentary:
- Dashboard data ingestion: Connects to the data sources behind each dashboard in the monthly reporting scope, pulling the current period metrics along with historical comparison data needed for trend analysis and period-over-period commentary
- Configurable analysis framework: Applies user-defined analysis prompts that specify what to look for in each metric domain, including threshold definitions for significance, comparison periods, and the specific business questions the narrative should address
- Trend detection and synthesis: Identifies statistically significant changes, anomalies, and emerging patterns within and across metric domains, connecting observations from different dashboards into coherent analytical threads
- Narrative draft generation: Produces professional executive commentary for each section of the monthly report, including performance summaries, trend explanations, risk callouts, and forward-looking observations
- Configuration interface: Provides a built-in UI where business users adjust analysis prompts, add or remove dashboards from scope, define significance thresholds, and customize the narrative tone and detail level without developer involvement
- Review and refinement workflow: Delivers draft narratives to analysts for review, edit, and approval before inclusion in the final executive report, maintaining human oversight while eliminating the blank-page starting point
Standout Features
- Business-user-controlled analysis prompts: The configuration interface lets business stakeholders define and adjust what the agent analyzes and how it frames insights, ensuring the narrative reflects current business priorities without requiring the analyst or IT team to modify code
- Multi-domain synthesis: The agent does not analyze each dashboard in isolation. It identifies cross-domain patterns, such as the relationship between contract mix changes and margin trends, that require seeing the full picture simultaneously
- Executive-appropriate language: Generated narratives use the hedging, qualification, and forward-looking language conventions that executive audiences expect, avoiding both robotic data recitation and unsupported speculation
- Progressive capability evolution: The system is designed to improve over time as analysts provide feedback on generated narratives, refine analysis prompts, and expand the reporting scope, creating a continuously improving analytical capability
- Audit-ready output: Each generated narrative section includes references to the specific metrics and time periods underlying its observations, providing the traceability that finance and compliance teams require
Who This Agent Is For
This agent is designed for organizations that produce regular executive reports synthesizing data from multiple dashboards and where the narrative writing step is the bottleneck in the reporting cycle.
- Financial analysts who spend days each month writing narrative commentary for executive reports when their expertise would be better applied to strategic analysis
- FP&A teams responsible for monthly performance reports across multiple business units, product lines, or geographic regions
- Operations leaders at equipment rental, leasing, or asset-intensive businesses where monthly reporting spans financials, utilization, inventory, and contract metrics
- Executive teams who need timely, professionally written performance summaries rather than raw dashboards without analytical context
- Any reporting team where the number of dashboards in scope has grown beyond what analysts can comprehensively review and narrate within the reporting deadline
Ideal for: Financial analysts, FP&A directors, operations controllers, reporting managers, and any organization where monthly executive reporting requires narrative synthesis across ten or more dashboards and the writing step consistently threatens the delivery timeline.

Creative Asset Vector Search AI Agent
AI-powered semantic search agent that transforms large creative image libraries into a queryable vector index, enabling context-based discovery of visual assets across distributed agency networks using embedding similarity rather than manual keyword tagging.
Inside the embedding architecture that converts a fragmented creative image library into a unified, similarity-searchable vector index
A global healthcare marketing network spanning more than 50 agencies faced a retrieval problem that no folder structure or tagging taxonomy could solve. Their collective creative asset library contained hundreds of thousands of images produced for pharmaceutical, biotech, and life sciences campaigns across six continents. Campaign photographers, designers, and art directors generated visual assets daily, but the organizational knowledge of what existed and where it lived was distributed across individual teams, local file servers, and siloed digital asset management systems that did not communicate with each other. A creative director in one office could not discover that a colleague in another city had already produced the exact visual concept she was briefing from scratch.
The Creative Asset Vector Search AI Agent implements an embedding pipeline that transforms every image in the library into a high-dimensional vector representation, indexes those vectors for similarity retrieval, and serves context-based search results that surface visually and semantically related assets regardless of how or whether they were tagged. The architecture treats visual similarity as the primary retrieval mechanism, replacing keyword dependency with mathematical proximity in embedding space.
Benefits
This agent converts a fragmented, unsearchable creative asset library into a unified retrieval system where any image can be found through visual and semantic similarity rather than manual metadata.
- Elimination of duplicate creative production: Teams discover existing assets that match their creative brief before commissioning new work, reducing redundant photoshoots, illustrations, and design production across the agency network
- Context-based retrieval without tagging: Vector similarity search surfaces relevant images based on what they visually contain rather than requiring someone to have correctly tagged them, capturing assets that keyword search misses entirely
- Cross-agency asset discovery: Creative teams in any office can search the entire global library from a single interface, breaking down the information silos that previously made each agency's assets invisible to the rest of the network
- Accelerated campaign concepting: Art directors and designers find reference imagery, existing executions, and reusable assets in seconds rather than the hours previously spent browsing folder structures or emailing colleagues
- Scalable ingestion pipeline: New creative assets are automatically embedded and indexed as they are produced, keeping the search corpus current without requiring manual cataloging or metadata entry from creative teams
- Brand consistency across markets: The ability to discover all visual executions of a concept across geographies helps maintain consistent brand expression and identifies unintentional visual drift before it reaches market
Problem Addressed
Creative organizations that operate at scale share a structural problem: the assets they produce become invisible almost immediately after production. A healthcare marketing agency produces thousands of images per quarter. Each one is filed somewhere, possibly tagged with something, and then functionally disappears into the local file system of the team that created it. When another team needs a similar image six months later, they have no way to know it exists. They search by keyword and find nothing because the original asset was tagged with different terminology, or not tagged at all. They browse folder structures organized by client, campaign, and date, but the image they need was produced for a different client in a different quarter. The result is systematic duplication of creative effort across the organization.
The problem compounds with organizational scale. A single-office agency might maintain institutional memory of its recent work through personal relationships and shared hallway conversations. A global network of 50 agencies cannot. The knowledge gap between what the organization has produced and what any individual team can discover is enormous, and it grows with every asset added to the library. Traditional digital asset management systems attempt to solve this with metadata schemas and tagging requirements, but those solutions depend on humans consistently applying the correct tags at the moment of upload. In practice, tagging compliance is low, tag vocabularies diverge across teams, and the most useful search dimensions are often visual characteristics that no reasonable tagging taxonomy can capture. You cannot tag an image with every possible future search query that might find it relevant.
What the Agent Does
The agent implements a multi-stage pipeline that converts raw creative image libraries into an indexed, queryable vector store optimized for semantic similarity retrieval:
- Library ingestion and normalization: The agent connects to distributed asset storage systems across the agency network, pulling images from local servers, cloud storage, and digital asset management platforms into a unified processing pipeline with format and resolution normalization
- Vector embedding generation: Each image is processed through a vision-language model that generates a high-dimensional embedding vector encoding the semantic and visual content of the asset, capturing composition, subject matter, color relationships, style, and conceptual meaning
- Similarity index construction: Embedding vectors are inserted into an approximate nearest-neighbor index with metadata linking each vector back to its source image, originating agency, campaign, creation date, and any existing tags or classifications
- Context-based similarity search: Users upload a reference image or describe a visual concept in natural language, and the agent retrieves the most semantically similar assets from across the entire library, ranked by embedding proximity
- Cross-agency deduplication detection: The agent identifies clusters of visually similar or near-duplicate images across the library, surfacing candidates for consolidation and highlighting potential brand consistency issues
- Incremental pipeline updates: New assets trigger incremental embedding and indexing rather than full library reprocessing, keeping operational costs proportional to new uploads rather than total library size
Standout Features
- Dual-mode query interface: Users can search by uploading a reference image for visual similarity or by typing a natural-language description that the agent converts to an embedding query, supporting both visual-first and concept-first discovery workflows
- Multi-network federation: The index spans assets from all agencies in the network without requiring data migration, maintaining source provenance so that asset ownership and licensing rights remain traceable to the originating team
- Embedding-level deduplication: Near-duplicate detection operates at the embedding layer rather than pixel comparison, catching images that are visually identical but differ in resolution, cropping, or minor color correction adjustments
- Campaign-aware clustering: The agent automatically groups visually related assets into campaigns and concept clusters, building an organizational map of the library that emerges from visual similarity rather than manual categorization
- Compliance-safe retrieval: Search results include licensing status, usage restrictions, and regulatory compliance flags pulled from source metadata, preventing teams from inadvertently reusing assets with expired rights or geographic restrictions
Who This Agent Is For
This agent is built for organizations that manage large, distributed creative image libraries where the volume of assets has outgrown the capacity of manual tagging and folder-based organization to support effective discovery.
- Creative agencies and agency networks managing visual assets across multiple offices, clients, and campaigns
- Brand teams responsible for maintaining visual consistency across markets and channels with large image libraries
- Digital asset management teams seeking to augment metadata-dependent systems with similarity-based retrieval
- Healthcare and pharmaceutical marketing organizations with compliance requirements that demand auditable asset provenance
- Media companies managing archives of editorial, commercial, and licensed imagery where keyword search consistently fails
Ideal for: Creative directors, DAM administrators, brand managers, art directors, and any organization where the question "do we already have something like this?" currently takes hours to answer or goes unasked because the library is too large to search effectively.

Marketing Insight Generation AI Agent
AI agent that scans governed marketing datasets to identify trends in campaign performance and spend allocation, producing structured monthly insights that replace manual agency reports with faster, data-driven media decisions.
The agency delivered the report three weeks after the month closed. By then, the budget had already been committed. The insights arrived too late to change anything.
A global pharmaceutical company deployed an AI agent to fundamentally change the timeline and economics of marketing analytics. The previous process relied on external agency partners to produce monthly analyses of marketing spend across brands, channels, and campaigns. Those reports were thorough but arrived weeks after the data was actionable, cost hundreds of thousands annually, and required cycles of review and revision before insights reached the teams who controlled media budgets. The Marketing Insight Generation AI Agent replaced that entire workflow with an automated system that scans governed marketing datasets, identifies performance trends and spend anomalies, and delivers structured insight reports that internal teams can act on immediately.
Benefits
This agent delivers a measurable shift in how marketing organizations consume analytics, replacing the delay-cost-revision cycle of agency reporting with immediate, consistent, and scalable insight generation.
- Insights delivered in days, not weeks: Monthly marketing analysis is produced within days of period close rather than the three-to-four-week lag typical of agency-produced reports, putting actionable intelligence in front of decision-makers while budget allocation windows are still open
- Significant reduction in reporting costs: The ongoing expense of external agency analytics is replaced by an automated system that operates at a fraction of the cost, redirecting budget from report production to media execution
- Consistent analytical framework: Every monthly report applies the same methodology, metrics, and threshold definitions, eliminating the variability that crept in when different agency analysts produced reports in different months using slightly different approaches
- Brand-level spend intelligence: The agent produces brand-specific performance analysis across all active channels, giving brand managers a consolidated view of their media effectiveness without requiring manual data assembly from multiple platform reports
- Channel optimization signals: Cross-channel spend and performance comparisons surface reallocation opportunities that would take analysts hours to identify manually, enabling continuous optimization rather than quarterly course corrections
- Governed data compliance: All analysis operates on the organization's governed marketing datasets, ensuring that insights are derived from approved, reconciled data sources rather than ad-hoc platform exports with inconsistent definitions
Problem Addressed
Large pharmaceutical companies manage marketing spend across dozens of brands, multiple therapeutic areas, and numerous media channels simultaneously. The complexity of this landscape means that understanding where money is going and what it is producing requires significant analytical effort. Historically, this analysis was outsourced to media agencies that had access to the data and the analysts to process it. The arrangement worked when marketing moved slowly, but modern media buying operates on weekly cycles while agency reports arrive on monthly or quarterly timelines.
The mismatch creates a compounding problem. Media planners make allocation decisions based on the most recent available analysis, which may reflect conditions from six weeks ago. Campaign underperformance that a timely report would have caught in week two continues through week six because the insight did not arrive until the month was over. Meanwhile, the cost of producing these reports represents a significant line item that scales with the number of brands and channels being analyzed. Every new brand launch or channel addition increases the reporting burden and cost without necessarily increasing the quality or timeliness of the insights produced.
What the Agent Does
The agent operates as an automated marketing intelligence pipeline that transforms governed marketing datasets into structured, actionable insight reports on a configurable schedule:
- Governed dataset scanning: Connects to the organization's approved marketing data repositories to ingest spend, impression, engagement, and conversion data across all active brands and channels, respecting data governance policies and access controls
- Trend identification: Applies statistical analysis to detect significant performance trends, spend anomalies, efficiency changes, and pacing variances across brands, channels, and campaigns, distinguishing meaningful shifts from normal variability
- Spend allocation analysis: Evaluates how marketing budget is distributed across channels and brands relative to performance metrics, identifying misalignments between spend share and outcome share that represent optimization opportunities
- Structured insight generation: Produces formatted monthly reports that follow a consistent analytical structure covering spend summary, performance highlights, trend analysis, channel comparison, and recommended focus areas
- Brand-specific deep dives: Generates brand-level analysis modules that brand managers can review independently, containing the channel performance, audience engagement, and competitive context specific to their portfolio
- Historical context layering: Each monthly report includes comparison to prior periods and year-over-year benchmarks, providing the temporal context needed to distinguish seasonal patterns from genuine performance changes
Standout Features
- Governed data-first architecture: The agent operates exclusively on approved, governed datasets rather than pulling from ad platform APIs directly, ensuring all insights comply with the organization's data quality and compliance standards
- Anomaly detection with context: When the agent identifies a significant performance change, it provides contextual analysis including potential contributing factors such as creative rotation, seasonal patterns, competitive activity timing, or budget pacing changes
- Multi-brand portfolio view: Leadership receives a portfolio-level summary that ranks brands by media efficiency, spend pacing, and performance trajectory, enabling resource allocation decisions across the entire brand portfolio rather than reviewing brands in isolation
- Configurable insight thresholds: Organizations define their own significance thresholds for trend detection, spend variance alerts, and performance flags, ensuring the agent surfaces insights calibrated to the organization's scale and volatility tolerance
- Audit trail and methodology transparency: Every insight includes the specific data sources, time periods, metrics, and analytical methods used to produce it, providing the documentation that compliance and finance teams require for marketing spend decisions
Who This Agent Is For
This agent is designed for marketing organizations where the volume of spend, number of brands, and diversity of channels have made manual insight generation too slow, too expensive, or too inconsistent to support the speed of modern media decisions.
- Marketing analytics teams spending disproportionate time assembling cross-channel reports rather than producing strategic recommendations
- Brand managers who need timely, brand-specific media performance analysis without waiting for centralized reporting cycles
- Media planning directors who require consistent, rapid-turnaround spend analysis to inform weekly and monthly allocation decisions
- CMOs and marketing leadership seeking to reduce agency analytics costs while improving the timeliness and consistency of marketing intelligence
- Pharmaceutical and regulated-industry marketing teams where governed data compliance adds complexity to every analytical workflow
Ideal for: Marketing directors, media planners, brand managers, analytics leads, and any enterprise marketing organization spending across multiple brands and channels where the gap between data availability and insight delivery represents lost optimization opportunity.

Member Churn Prediction AI Agent
AutoML-powered churn prediction agent that identifies at-risk members using behavioral data and geographic proximity analysis, enabling proactive retention strategies with household-level risk scoring.
Members do not leave all at once. They drift. The question is whether you can see the drift before the departure.
A large multi-campus community organization serving over 20,000 members weekly across six locations faced a problem that no amount of anecdotal observation could solve. Members were leaving, and leadership had no systematic way to understand why, predict who was next, or intervene before it happened. Attendance data existed. Address records existed. Engagement metrics existed. But none of it was connected into a predictive framework that could tell the retention team which households to focus on this week rather than discovering the loss three months later in an annual report.
Benefits
This agent transforms member retention from a reactive process driven by lagging indicators into a proactive system that identifies risk before disengagement becomes departure.
- Household-level risk visibility: Every member household receives a churn probability score based on behavioral signals, engagement patterns, and demographic factors, replacing gut-feel assessments with quantified risk that retention teams can prioritize systematically
- Geographic proximity as a predictive factor: Geocoded member addresses reveal the relationship between distance-to-campus and churn risk, exposing a retention variable that was previously invisible and allowing location-specific retention strategies
- Early warning before disengagement: The model identifies households showing churn-predictive patterns weeks or months before they stop attending entirely, creating an intervention window that does not exist with traditional attendance-based tracking
- Data-driven resource allocation: Retention staff focus their limited outreach capacity on the households where intervention is most likely to prevent churn, rather than spreading effort uniformly or responding only after members have already left
- Multi-campus pattern recognition: The model surfaces campus-specific churn drivers, revealing whether distance, program availability, service times, or demographic factors drive attrition differently at each location
- Actionable factor decomposition: Each churn prediction includes the specific factors contributing to the risk score, giving retention teams concrete conversation starters and intervention approaches rather than just a number
Problem Addressed
When a community organization operates across multiple campuses, retention is not a single problem but a collection of location-specific challenges masked by aggregate numbers. A campus near a growing suburban area might be losing young families to a competitor location closer to new housing developments. A downtown campus might be losing members whose commute pattern changed after a job relocation. A campus that added new programs might be retaining better than average, but no one connects the program change to the retention improvement because the data lives in separate systems.
The deeper issue is that member loss is a gradual process with identifiable precursors, but those precursors are spread across attendance systems, registration databases, giving records, and address files that no one has the time or tools to analyze together. A household that attended weekly for three years and has dropped to monthly over the past quarter is sending a clear signal. A family that moved from five miles away to fifteen miles away is now in a higher-risk distance bracket. These signals exist in the data. The problem is that without a predictive model, they are invisible until the member is already gone, and by then the retention conversation is a recovery conversation, which succeeds far less often.
What the Agent Does
The agent builds and maintains a predictive churn model that scores every member household and surfaces the specific factors driving each risk assessment:
- Household data consolidation: Aggregates member data across attendance records, registration systems, engagement logs, and contact databases to create a unified household profile that captures the full behavioral footprint of each membership unit
- Address geocoding and distance calculation: Processes member addresses through geocoding to calculate precise distance between each household and their home campus, establishing geographic proximity as a first-class predictive variable alongside behavioral metrics
- AutoML churn model training: Trains a machine learning model on historical churn outcomes to identify the combination of behavioral, demographic, and geographic factors that most reliably predict disengagement at the household level
- Household-level risk scoring: Applies the trained model to the current member base, producing a churn probability score for every active household along with the ranked factors contributing to each score
- Factor analysis dashboard: Delivers an interactive dashboard where retention teams can explore churn drivers by campus, demographic segment, distance bracket, and engagement level to identify systemic patterns
- Intervention priority queue: Generates a prioritized list of at-risk households ranked by churn probability and retention intervention likelihood, giving outreach teams a daily action list rather than a static report
Standout Features
- Geographic churn mapping: Visualizes the spatial distribution of churn risk across the service area, revealing distance-based retention boundaries for each campus that inform location strategy, satellite programming, and outreach geography
- Multi-campus comparative analysis: The model isolates campus-specific churn factors, enabling leadership to identify which locations have retention problems driven by distance, which by programming gaps, and which by demographic shifts in the surrounding area
- Behavioral trajectory tracking: Rather than using point-in-time snapshots, the model analyzes engagement trajectories to distinguish between members who are gradually disengaging and those who have stable low-frequency patterns, avoiding false positives from naturally infrequent attenders
- Configurable intervention triggers: Organizations set their own risk thresholds for automated alerting, choosing the churn probability level that triggers retention team notification based on their outreach capacity and intervention success rates
- Model transparency: Every prediction includes a human-readable breakdown of the top contributing factors, ensuring that retention conversations are grounded in specific, observable changes rather than opaque algorithmic scores
Who This Agent Is For
This agent is built for membership-based organizations where retention directly impacts mission fulfillment and financial sustainability, and where the member base is large enough that individual relationship monitoring has become impossible.
- Membership retention teams at multi-location organizations who need to prioritize outreach across thousands of households with limited staff capacity
- Community organization leadership seeking data-driven insights into why members leave and what interventions are most effective at different campuses
- Operations directors at multi-campus organizations who need to understand how geographic expansion, facility changes, or program adjustments affect member retention patterns
- Data teams at nonprofit and membership organizations looking to apply predictive analytics to member engagement without building models from scratch
- Any organization with recurring membership or subscription relationships where early identification of churn risk creates a meaningful intervention opportunity
Ideal for: Retention directors, membership managers, campus leaders, community organization executives, and any multi-location membership organization where the cost of losing an engaged member far exceeds the cost of a proactive retention conversation.

Skier Visit Forecasting AI Agent
ML-powered forecasting agent that predicts skier visits across multiple resort locations using weather data, historical patterns, and season pass sales to enable proactive staffing decisions and operational planning.
Staffing a ski resort is a forecasting problem disguised as an operations problem. Get the model right, and every other decision downstream improves.
The Skier Visit Forecasting AI Agent was engineered to replace rudimentary seasonal models with a multi-variable prediction system that accounts for the actual drivers of resort traffic. A multi-resort operator managing properties across several states faced a persistent mismatch between staffing levels and actual visitor volume. Their existing in-house models relied on simple historical averages and basic seasonality, which failed to capture the weather-dependent volatility that defines ski resort operations. A warm weekend could cut expected traffic by 40%. An unexpected snowfall midweek could double it. The gap between forecast and reality cascaded into either overstaffing costs or understaffed service failures, and the problem multiplied across every location in the portfolio.
Benefits
This agent replaces guesswork-driven staffing with data-driven predictions that account for the real variables affecting resort visitation, delivering measurable operational improvements across every property in the network.
- Weather-responsive predictions: Forecasts incorporate temperature, snowfall, and precipitation data at each resort location, capturing the weather sensitivity that purely historical models miss entirely and that drives the largest forecast errors
- Multi-resort staffing optimization: Each property receives location-specific forecasts that account for its unique visitor patterns, elevation, regional weather, and proximity to population centers, replacing the one-size-fits-all models that systematically misallocate labor
- Season pass integration: Season pass sales volumes feed directly into the prediction model as a leading indicator of baseline demand, giving operations teams weeks of advance signal about committed visitor volume before the season begins
- Reduced overstaffing costs: Accurate forecasts eliminate the costly practice of staffing to peak capacity as a hedge against uncertainty, allowing resort operators to right-size labor deployment based on data rather than conservative assumptions
- Improved guest experience during surges: When the model predicts high-traffic days with confidence, operations teams can proactively add staff, open additional lifts, and stock inventory rather than reacting after lines have already formed
- Outperformance of seasonal baselines: The ML model consistently outperforms pure seasonal forecasting approaches by incorporating lagged visit data and real-time weather signals that capture week-to-week variability within a season
Problem Addressed
Resort operations teams have always known that weather drives visitation. The problem was never awareness but rather the inability to translate that knowledge into actionable forecasts at the precision and lead time required for staffing decisions. Traditional models used historical averages by week-of-season, which captured broad seasonal patterns but treated every Tuesday in January as interchangeable. In reality, a Tuesday with 8 inches of fresh powder and a Tuesday at 45 degrees with rain produce fundamentally different visitor volumes.
The consequences of inaccurate forecasts compound across the entire operation. Overstaffing on slow days burns labor budget that could be deployed on busy days. Understaffing on surge days creates long lift lines, crowded rental shops, and frustrated guests who are less likely to return. When a resort operator manages multiple locations across different climate zones, these errors multiply by the number of properties, and the aggregated waste represents millions in misallocated labor annually. The fundamental gap was a forecasting system sophisticated enough to model the relationship between weather conditions, historical patterns, pass holder behavior, and actual visitation at each individual location.
What the Agent Does
The agent operates as a continuous forecasting pipeline that ingests multi-source data and produces location-specific visitor predictions calibrated for staffing decisions:
- Weather data integration: Connects to meteorological data sources to ingest current conditions and forecasts for each resort location, including temperature, snowfall accumulation, precipitation type, wind speed, and multi-day outlooks
- Historical pattern analysis: Processes years of historical visit data with lagged variables to identify the specific relationships between conditions and visitation at each resort, accounting for day-of-week effects, holiday calendars, and school break schedules
- Season pass demand signal: Incorporates season pass sales volumes and holder demographics as predictive features, using early-season sales velocity and total pass holder counts to establish baseline demand floors for each property
- ML-based visit prediction: Runs trained forecasting models that combine weather, historical, and pass data to generate daily visit predictions with confidence intervals for each resort location across the planning horizon
- Staffing recommendation output: Translates visit predictions into department-level staffing recommendations based on configurable ratios for lift operations, food service, rental shops, ski patrol, and guest services
- Forecast accuracy tracking: Continuously compares predictions against actual visit counts to monitor model performance, flag drift, and trigger retraining when accuracy degrades below configured thresholds
Standout Features
- Location-specific model calibration: Each resort property has its own calibrated model that reflects its unique elevation, microclimate, visitor demographics, and drive-time radius, avoiding the averaging effect that degrades accuracy in multi-resort deployments
- Lagged visit variable engineering: The model uses recent visit history as a predictive signal, recognizing that visitor behavior this week is partially conditioned on conditions and experiences from recent visits, capturing momentum and fatigue effects
- Confidence-interval staffing: Predictions include uncertainty ranges that allow operations teams to plan for both expected and high scenarios, enabling proportional hedge staffing rather than binary over-or-under decisions
- Automated retraining pipeline: The model retrains on fresh data at configurable intervals, incorporating the latest season's patterns without manual intervention from data science teams
Who This Agent Is For
This agent is designed for resort and hospitality operators where visitor volume is weather-dependent and staffing decisions must be made days in advance based on inherently uncertain conditions.
- Resort operations managers responsible for daily staffing levels across lift operations, food service, rental shops, and guest services
- Multi-property hospitality operators who need location-specific forecasts that account for each site's unique conditions and visitor patterns
- Workforce planning teams at seasonal recreation businesses where labor is the largest controllable cost and forecast accuracy directly impacts margin
- Revenue management directors who need accurate demand forecasts to optimize dynamic pricing for lift tickets, lodging, and ancillary services
- Data and analytics teams seeking to replace ad-hoc spreadsheet models with a production ML pipeline that improves automatically over time
Ideal for: Resort general managers, operations directors, workforce planning leads, and any seasonal hospitality business where weather-driven demand volatility makes accurate forecasting the difference between profitable operations and wasted labor spend.

Partner PDF Processing AI Agent
Hosted partner portal that replaces manual PDF purchase order processing with automated workflow parsing, storing extracted data in datasets, and optionally writing to external platforms via API for end-to-end supply chain automation.
Benefits
This agent eliminates the tedious, error-prone manual processing of PDF purchase orders by giving partners a self-service portal and automating every step from upload to data distribution.
- End-to-end PDF automation: From the moment a partner uploads a purchase order to the moment the extracted data appears in a dataset or external system, every step executes without manual intervention
- Partner self-service: Partners log into a hosted portal and upload purchase orders directly, eliminating the email-based submission process that creates lost documents, version confusion, and manual forwarding chains
- Accurate data extraction: AI-powered PDF parsing extracts line items, quantities, pricing, shipping details, and terms from purchase order documents with consistency that manual data entry cannot match
- Multi-platform data distribution: Extracted data is stored in datasets and can optionally be written to any external platform via API, integrating purchase order data into ERP systems, inventory management tools, or financial platforms
- Scalable partner onboarding: Adding a new partner to the system requires creating a login credential, not building a new integration. The same portal and parsing workflow handles every partner's submissions
- Complete audit trail: Every submission, parsing result, and data distribution event is logged, providing full traceability from the original PDF to every system that received the extracted data
Problem Addressed
The scene is familiar to anyone in supply chain operations: a partner emails a PDF purchase order. Someone downloads it, opens it, and starts manually typing line items into a spreadsheet or ERP system. They squint at the formatting, trying to distinguish between item numbers that look similar. They make a transposition error on the quantity. They miss a line item on page three because the PDF formatting pushed it to an awkward position. By the time the data is entered, thirty minutes have passed for a single purchase order.
Now multiply that by dozens of partners, each sending purchase orders in slightly different PDF formats, on different schedules, to different email addresses. Some orders get lost in inboxes. Some get processed twice because the confirmation email did not go out. Some sit for days because the person who handles them is on vacation and nobody else knows to check that inbox. The manual PDF processing workflow is not just slow. It is fragile in ways that create real financial consequences: wrong quantities lead to wrong shipments, missed orders lead to missed revenue, and duplicate processing leads to wasted inventory allocation.
What the Agent Does
The agent operates as a complete purchase order processing pipeline, from partner submission through data extraction and multi-platform distribution:
- Hosted partner portal: Provides a secure, branded web portal where authenticated partners log in and upload PDF purchase orders through a simple drag-and-drop interface
- Submission validation: Validates uploaded documents for format compliance, file integrity, and required information before accepting them into the processing queue
- AI-powered PDF parsing: Processes each submitted PDF using trained extraction models that identify and extract purchase order fields including line items, product codes, quantities, unit prices, shipping addresses, payment terms, and delivery dates
- Structured data storage: Transforms extracted purchase order data into structured records stored in datasets, with normalized field formats and relational keys that support downstream analytics and reporting
- API write-back: Optionally pushes extracted data to external platforms via configurable API integrations, enabling automatic population of ERP systems, inventory management tools, accounting software, or any system with an API endpoint
- Status notification: Notifies both the submitting partner and internal stakeholders when purchase orders are received, processed, and distributed, providing visibility into the pipeline status
Standout Features
- Multi-format PDF handling: The parsing engine handles purchase orders in varying PDF formats from different partners, adapting its extraction logic to the document structure rather than requiring standardized templates
- Embedded partner authentication: The portal can be embedded within partner-facing sites or accessed standalone, with authentication that supports individual partner accounts, role-based access, and submission history tracking
- Configurable API destinations: The write-back functionality supports multiple simultaneous API destinations per submission, enabling a single purchase order to populate both an internal dataset and an external ERP system in a single processing cycle
- Exception handling workflow: When the parser encounters ambiguous or unreadable content, it routes the submission to a human review queue with the extracted data pre-populated for correction rather than requiring complete manual re-entry
- Historical analytics: Every processed purchase order contributes to a growing dataset of partner ordering patterns, seasonal trends, and volume analytics that supports demand forecasting and partner relationship management
Who This Agent Is For
This agent is built for operations teams drowning in PDF purchase orders that arrive by email and require manual data entry before the information can be used anywhere.
- Supply chain teams processing high volumes of PDF purchase orders from 3PL partners, distributors, or wholesale customers
- Partner operations managers who need a scalable submission process that works for five partners today and fifty tomorrow
- Logistics coordinators who need purchase order data to reach inventory and fulfillment systems faster than manual processing allows
- Finance teams requiring accurate, timely purchase order data for revenue recognition, accounts receivable, and cash flow forecasting
Ideal for: Any organization with partner or vendor relationships that generate regular PDF purchase orders, where the manual processing of those documents creates delays, errors, and scalability constraints.

Page Export Bursting AI Agent
Workflow-based agent that replicates MicroStrategy's page export bursting capability, automatically generating and distributing filtered dashboard views to cloud storage or email recipients based on configurable filter permutations.
Benefits
This agent delivers a critical capability for organizations migrating from MicroStrategy: automated distribution of personalized, filtered dashboard views without requiring recipients to log in, navigate, or apply their own filters.
- MicroStrategy feature parity: Organizations migrating from MicroStrategy retain the page export bursting capability their users depend on, eliminating a common migration blocker that stalls platform consolidation projects
- Automated personalized distribution: Each recipient receives a version of the dashboard filtered to their specific context, whether that is a region, a department, a product line, or any other dimension, without any manual preparation
- Flexible delivery targets: Bursted reports can be delivered to Google Cloud Storage buckets for archival and downstream processing, or sent directly via email to individual recipients or distribution lists
- Schedule-driven execution: Bursting jobs run on configurable schedules, automatically generating and distributing fresh dashboard views as underlying data updates, with no manual intervention required
- Eliminated manual report preparation: Report producers no longer need to manually apply filters, export, and distribute individual dashboard versions for each recipient or region, reclaiming hours of repetitive work per distribution cycle
- Consistent formatting and timing: Every recipient receives their filtered view in the same format, at the same time, with the same data freshness, eliminating the inconsistencies that plague manual distribution processes
Problem Addressed
MicroStrategy's page export bursting was one of its most relied-upon features: configure a report, specify a set of filter values, and the system automatically generates and distributes a separate version for each filter combination. Region managers get their region. Department heads get their department. No one has to log in, navigate, or apply filters. The reports just arrive.
When organizations migrate to a new platform, this capability often does not have a direct equivalent. The result is one of two outcomes: either someone manually creates and distributes each filtered version, or the organization loses the capability entirely and asks recipients to self-serve. Neither outcome is acceptable for organizations where hundreds of stakeholders expect personalized reports delivered to their inbox or cloud storage on a predictable schedule. The technical challenge is not the filtering or the export. It is the orchestration: iterating through filter combinations, rendering each version, and routing each output to the correct destination without manual intervention.
What the Agent Does
The agent operates as a burst distribution engine that automates the generation and delivery of filtered dashboard views across configured recipient lists:
- Dashboard and filter configuration: Administrators specify the source dashboard page and define the filter dimensions that should be permuted, including the specific values for each dimension that constitute the burst set
- Filter permutation engine: Generates the complete set of filter combinations that need to be rendered, whether that is one filter dimension with 50 values or multiple dimensions creating a cross-product of views
- Automated page rendering: For each filter combination, applies the filters to the source dashboard and renders the resulting view as a distributable output in the configured format
- Recipient routing: Maps each rendered output to its designated recipient or storage location based on the filter values, ensuring that each stakeholder receives only the views relevant to their context
- Cloud storage delivery: Uploads rendered outputs to configured Google Cloud Storage buckets with organized folder structures and consistent naming conventions for easy downstream access
- Email distribution: Sends rendered outputs as email attachments or inline content to configured recipients, with customizable subject lines, body text, and sender information
Standout Features
- Multi-dimension bursting: Supports bursting across multiple filter dimensions simultaneously, generating every valid combination of region, department, product line, or any other filterable dimension on the source dashboard
- Dual delivery mode: Each burst configuration can deliver outputs to cloud storage, email, or both simultaneously, supporting organizations where some recipients consume reports from storage while others prefer email delivery
- Execution monitoring: Provides detailed execution logs showing which outputs were generated, which deliveries succeeded, and which failed, with automatic retry for transient delivery failures
- Dynamic recipient mapping: Recipient lists can be driven by dataset lookups rather than static configuration, allowing the distribution list to automatically adjust as organizational structures change
- Incremental rendering optimization: When only a subset of filter combinations need to be re-rendered due to selective data updates, the agent can execute partial bursts rather than regenerating the entire output set
Who This Agent Is For
This agent is specifically built for organizations migrating from MicroStrategy or any platform with native bursting capabilities, and for any team that needs automated distribution of personalized dashboard views.
- BI administrators responsible for migrating from MicroStrategy who need to maintain bursting functionality for their user base
- Report consumers who depend on receiving personalized, filtered dashboard views on a regular schedule without self-service navigation
- Migration project teams evaluating feature parity between their current platform and the target environment
- Operations teams distributing performance dashboards to regional or departmental managers who need filtered views of centralized data
Ideal for: Organizations with MicroStrategy migration projects, distributed reporting requirements, or any environment where stakeholders expect personalized dashboard views delivered automatically without logging into the platform.

Universal Chat with RAG AI Agent
Universal chat application that connects to every FileSet with built-in RAG embeddings and every dataset in the instance, providing a single conversational interface with persistent chat history for contextual data queries.
Benefits
This is the chat interface that practitioners have been assembling piecemeal from separate tools. One app. Every FileSet. Every dataset. Built-in RAG. Persistent history. No per-source configuration.
- Universal data access: A single chat interface connects to every FileSet and every dataset in the instance, eliminating the need to know which data source contains the information you need before you can ask the question
- Built-in RAG without setup: FileSets are automatically embedded for retrieval-augmented generation, meaning document-based queries work immediately without any preprocessing pipeline or vector database configuration
- Persistent conversation history: Chat history is maintained across sessions, allowing users to reference previous queries, build on earlier analysis, and maintain context in ongoing research threads
- Elimination of per-source configuration: Traditional RAG implementations require configuring each data source individually. This agent connects to everything by default, removing the setup overhead that prevents most organizations from achieving universal data access
- Natural language querying: Users ask questions in plain language and receive answers synthesized from across the entire data estate, whether the answer lives in a PDF in a FileSet or a column in a dataset
- Instant time-to-value: Because the agent connects to all existing data sources automatically, it provides useful answers from the moment it is deployed without requiring data migration, indexing, or configuration
Problem Addressed
Here is what the data access experience looks like in most organizations: you know the information exists somewhere, but you do not know which dataset or document contains it. So you search through file directories, scan dataset names, open a few likely candidates, and eventually find what you need twenty minutes later. Now multiply that by every question, every day, every person in the organization.
RAG-based chat interfaces solve this problem beautifully in theory. In practice, every implementation requires configuring each data source individually: connecting the source, building the embedding pipeline, indexing the content, and maintaining the index as content changes. For organizations with dozens or hundreds of FileSets and datasets, the setup overhead means that most data sources never get connected, and the chat interface only has access to a fraction of available knowledge. The gap between the RAG promise of "ask anything" and the RAG reality of "ask about the three sources we had time to configure" is where this agent lives.
What the Agent Does
The agent operates as a universal chat interface with automatic connection to every data source in the instance:
- Automatic FileSet discovery and embedding: Scans all available FileSets in the instance and builds embeddings for each document, enabling retrieval-augmented generation across the complete document corpus without manual configuration
- Universal dataset connection: Connects to every dataset in the instance, enabling structured data queries across the full data estate without specifying which dataset to search
- Conversational query interface: Provides a natural language chat interface where users ask questions and receive synthesized answers that draw from both unstructured documents in FileSets and structured data in datasets
- RAG-powered document retrieval: When a query relates to document content, the agent uses embedding similarity to identify the most relevant documents and passages, then synthesizes an answer grounded in the retrieved content
- Structured data analysis: When a query relates to structured data, the agent identifies the relevant dataset, constructs the appropriate query, and returns formatted results with context and interpretation
- Persistent chat history: Maintains full conversation history per user, enabling contextual follow-up questions, reference to previous answers, and long-running research threads that build on accumulated context
Standout Features
- Zero-configuration data coverage: The agent automatically connects to and indexes every available data source in the instance, achieving complete coverage without requiring administrators to configure each source individually
- Hybrid structured and unstructured querying: A single question can trigger both document retrieval from FileSets and data queries from datasets, synthesizing answers that combine insights from both modalities
- Automatic embedding maintenance: As new documents are added to FileSets or existing documents are updated, embeddings are automatically refreshed to keep the RAG index current without manual reindexing
- Source attribution: Every answer includes references to the specific documents, passages, or datasets that contributed to the response, enabling users to verify answers against source material
- Conversation threading: Users can maintain multiple active conversation threads for different research topics, with each thread preserving its own context and history independently
Who This Agent Is For
If you have been building separate RAG pipelines for different data sources, this agent is the consolidation you have been planning but never had time to build.
- All platform users who need to find information across the organization's complete data estate without knowing which specific source contains the answer
- Analysts who routinely search across multiple datasets and document repositories to answer business questions
- Knowledge workers who need quick access to information stored in uploaded documents, reports, and reference materials across FileSets
- Platform administrators who want to provide a single, powerful data access interface to their user base without configuring individual data source connections
Ideal for: Any organization with a large, distributed data estate across both structured datasets and document FileSets where the time spent searching for information represents a measurable productivity cost.

App Generator AI Agent
AI-powered app generator built entirely by business users on the platform, demonstrating that sophisticated development tooling can be created without engineering resources and enabling self-service app creation.
Benefits
This agent delivers a transformative outcome: business users who previously waited weeks for engineering to build custom apps can now generate functional applications themselves, directly on the platform, without writing code.
- Engineering independence: Business teams create the apps they need without filing tickets, waiting in development queues, or compromising on requirements due to engineering bandwidth constraints
- Proof of platform extensibility: The agent itself was built by business users on the platform, demonstrating that the same tools available to every user are powerful enough to create sophisticated development tooling
- Rapid prototyping: Ideas go from concept to functional prototype in minutes rather than sprint cycles, enabling teams to test approaches, gather feedback, and iterate at the speed of thought
- Reduced development backlog: By enabling self-service for routine app creation, the engineering team can focus on complex, high-value development work rather than building simple data entry forms and dashboard views
- Consistent app quality: Generated apps follow platform best practices for layout, data binding, and interaction patterns, producing a more consistent user experience than ad hoc manual development
- Democratized innovation: When the barrier to creating an app drops to describing what you need, every business user becomes a potential builder, unlocking innovation from the people closest to the problems
Problem Addressed
Every organization has a backlog of apps that business teams need but engineering cannot prioritize. A data entry form for the field team. A tracking dashboard for the operations group. A simple approval interface for the procurement department. Each one is straightforward to build but competes for attention with revenue-generating features and critical infrastructure work. The result is a growing gap between what business teams need and what they receive.
The conventional answer is to train business users to build their own apps, but the learning curve for most development tools is steep enough that only the most technically inclined business users make the investment. The unconventional answer, demonstrated by this agent, is to build a tool that lets business users generate apps by describing what they need. This agent proves that the platform itself is powerful enough to support this level of abstraction, with business users building the generator itself on the same platform where the generated apps will run.
What the Agent Does
The agent functions as a self-service app creation interface that translates user specifications into functional applications:
- Specification intake: Presents a guided interface where users describe the app they need, including its purpose, the data it should display or collect, the user interactions it should support, and any workflow triggers it should initiate
- Layout generation: Translates specifications into app layouts with appropriate component placement, responsive design structure, and navigation patterns that match the described use case
- Data binding: Connects generated app components to the specified data sources, configuring read operations for display components and write operations for input forms
- Interaction wiring: Configures user interaction handlers including form submissions, button actions, navigation events, and filter controls that implement the specified app behavior
- Style application: Applies consistent visual styling that aligns with organizational branding and platform design conventions, ensuring generated apps look professional without manual design work
- Preview and refinement: Provides a preview of the generated app where users can test interactions, review layouts, and request modifications before finalizing the application for deployment
Standout Features
- Built by business users, for business users: The app generator itself was created by business users using the same platform capabilities available to every user, proving that no engineering team is needed to build sophisticated tooling
- Natural language specification: Users describe their app requirements in plain language rather than through technical configuration forms, making the specification process accessible to anyone who can articulate what they need
- Multi-component app generation: Generated apps include data tables, input forms, chart visualizations, filter controls, and action buttons, not just single-purpose views but complete, multi-component applications
- Data-aware component selection: The agent examines the connected data sources and selects appropriate components based on data types, cardinality, and relationships, choosing between tables, charts, and forms based on what makes sense for the data
- Iterative refinement workflow: Users can modify generated apps through additional natural language instructions, adding components, changing layouts, or adjusting behavior without starting from scratch
Who This Agent Is For
This agent is for every business user who has ever thought "I just need a simple app for this" and then discovered that "simple" still means weeks in the development queue.
- Business users across any department who need functional apps for data entry, tracking, reporting, or workflow management but lack development skills
- Citizen developers who have some technical aptitude and want to create more sophisticated apps without writing code
- Department managers looking to equip their teams with custom tools without consuming engineering budget or bandwidth
- Innovation teams exploring rapid prototyping approaches where speed of iteration matters more than pixel-perfect design
Ideal for: Any organization where the demand for custom applications exceeds engineering capacity, and where empowering business users to create their own tools would unlock measurable productivity gains.

Workflow Generator AI Agent
AI-powered tool that generates medium-sized workflows with loops, correctly mapped parameters, and working automation logic ready for deployment, eliminating the deep platform expertise previously required.
Benefits
This agent removes the most painful part of workflow development: the hours spent manually configuring loop structures, mapping parameters between steps, and debugging the subtle misconfigurations that cause workflows to fail silently at runtime.
Problem Addressed
Building workflows sounds simple until you actually do it. The first few steps are straightforward: add a trigger, connect an action, map a couple of parameters. But complexity grows fast. You need a loop that iterates over a dataset, performing an API call for each row. The loop requires an iterator variable. Each API call inside the loop needs parameters that reference both the loop context and the outer workflow context. One wrong parameter reference and the workflow either fails with an opaque error or silently processes the wrong data.
The problem is not that workflows are conceptually difficult. The problem is that the mechanical work of correctly configuring medium-complexity workflows, those with loops, conditional branches, and cross-step parameter dependencies, requires a level of platform expertise that most teams do not have in depth. A workflow builder who understands what they want the automation to do can still spend hours debugging parameter mapping issues, loop scoping problems, and step sequencing errors. For organizations that need many workflows built quickly, this expertise bottleneck becomes a capacity constraint that limits their automation ambitions.
What the Agent Does
The agent operates as an intelligent workflow construction engine that translates automation requirements into fully configured, deployable workflow packages:
Standout Features
Who This Agent Is For
This agent is for anyone who has spent a frustrating afternoon debugging a workflow loop that should have been simple, and for teams that need automation built faster than their platform expertise allows.
Ideal for: Teams building moderate-complexity automations where the gap between understanding what the workflow should do and correctly configuring every step represents a significant time and expertise cost.

Competitive Intel Maintenance AI Agent
Daily AI agent that verifies, updates, and maintains competitive intelligence databases by checking facts against current sources, removing stale data, and adding new findings.
Benefits
If you have ever built a competitive database and watched it go stale within weeks, this agent solves that problem permanently. It does the tedious verification work so your team never has to.
- Always-current competitive data: Every fact in the competitive database is verified on a daily cycle, ensuring that the intelligence your team accesses is current rather than reflecting the competitive landscape as it existed weeks or months ago
- Zero manual maintenance: The agent handles the full maintenance lifecycle autonomously — verifying existing facts, removing outdated entries, adding newly discovered information, and validating data integrity — without requiring any human involvement in the routine process
- Stale data elimination: Facts that can no longer be verified against current sources are flagged and removed, preventing the accumulation of outdated intelligence that erodes trust in the competitive database over time
- New intelligence discovery: Beyond verification, the agent actively discovers new competitive facts — product releases, pricing changes, leadership moves, partnership announcements — and adds them to the appropriate competitor profiles
- Change transparency: Every modification to the competitive database is logged with a timestamp, change type, and source reference, giving analysts full visibility into what changed, when, and why
- Scalable coverage: The agent maintains data hygiene across all tracked competitors simultaneously. Adding a new competitor to the tracking list does not increase the manual maintenance burden because the automated process handles it identically
Problem Addressed
Competitive intelligence databases are only as valuable as the data they contain, and competitive data has a short shelf life. Competitors update pricing quarterly. Product features ship monthly. Executive teams change. Partnerships form and dissolve. Market positioning evolves in response to competitive pressure and customer feedback. A competitive fact that was accurate three months ago may be actively misleading today.
Most organizations build competitive databases with an initial burst of research effort, then watch the data quality degrade over time because ongoing maintenance requires the same research effort that built the database originally. Product marketing teams are too busy with launches, campaigns, and sales support to systematically verify every fact in a database covering multiple competitors. The result is a competitive intelligence resource that team members learn to distrust, defaulting back to ad-hoc research that duplicates work already done. The organization needed an automated maintenance layer that could keep the competitive database current at the same level of quality and freshness that was present on the day it was originally built.
What the Agent Does
The agent operates as a daily automated maintenance service that systematically verifies, updates, and extends the competitive intelligence database:
- Fact extraction: The agent pulls all existing facts from the competitive database for each tracked competitor, organizing them by category (features, pricing, releases, leadership, positioning, partnerships) for systematic verification
- Source verification: Each fact is checked against current competitive intelligence sources including competitor websites, press releases, analyst reports, review platforms, and public filings to confirm it remains accurate
- Stale data identification: Facts that cannot be verified against current sources, or that conflict with newer information, are flagged for removal. The agent distinguishes between facts that are simply unverifiable (source page removed) and facts that are actively contradicted by newer data
- New fact discovery: During the verification process, the agent identifies new competitive information not currently in the database and adds it with appropriate source attribution and confidence scoring
- Database update execution: Verified removals, additions, and modifications are applied to the competitive database with full change logging, including timestamps, change descriptions, and source references for every modification
- Maintenance report generation: After each daily cycle, the agent produces a summary report detailing what changed: facts removed, facts added, facts modified, and any competitor profiles that experienced significant changes warranting analyst review
Standout Features
- Autonomous daily execution: The entire maintenance cycle runs without human intervention on a daily schedule, ensuring that data freshness is maintained consistently regardless of team availability, workload, or competing priorities
- Granular change logging: Every database modification is recorded with the specific fact that changed, the nature of the change (add, remove, update), the source that triggered the change, and a timestamp, creating a complete audit trail of competitive database evolution
- Confidence-scored additions: New facts discovered by the agent are added with a confidence score based on source reliability and corroboration, enabling analysts to prioritize manual verification of lower-confidence additions
- Anomaly escalation: When the agent detects unusually large changes for a single competitor — such as a complete pricing restructure or major product pivot — it escalates the changes for human review rather than applying them automatically
- Coverage gap identification: The agent identifies competitor profiles where fact density is thin relative to other tracked competitors, flagging areas where additional research investment would improve intelligence coverage
Who This Agent Is For
This agent is designed as a companion to competitive intelligence systems that require continuous data freshness to remain trustworthy and useful.
- Product marketing teams maintaining competitive databases who lack the bandwidth to manually verify facts across all tracked competitors on a regular cadence
- Competitive intelligence analysts who want to focus on strategic analysis and insight generation rather than spending time on routine database maintenance and fact-checking
- Sales enablement teams who depend on competitive battle cards being current and accurate, and need confidence that the underlying data is regularly verified
- Marketing operations teams building automated competitive intelligence workflows that require a reliable, continuously maintained data layer
- Strategy teams using competitive intelligence for planning and decision-making who need assurance that the data supporting their analyses is current
Ideal for: Technology companies, financial services firms, consulting organizations, and any enterprise that maintains structured competitive intelligence databases across multiple tracked competitors.

Competitive Intelligence AI Agent
AI agent that queries structured competitor fact databases to provide in-depth competitive research across multiple tracked competitors through natural language conversation.
Benefits
This agent transforms competitive intelligence from a time-intensive research project into an instant, conversational capability available to everyone who needs it.
- Instant competitive answers: Sales reps preparing for competitive deals get detailed, accurate competitive intelligence in seconds through natural language queries, eliminating the days-long turnaround of requesting research from product marketing
- Structured fact foundation: Every competitive claim is grounded in a structured database of verified facts — feature comparisons, pricing data, product releases, positioning statements — rather than ad-hoc research that varies in quality and currency
- Broad competitive coverage: The agent maintains detailed profiles across multiple competitors simultaneously, providing depth of analysis that would require a dedicated analyst for each competitor to replicate manually
- Consistent messaging: Because all competitive intelligence flows from the same curated fact base, every team member receives the same competitive narrative, eliminating the inconsistencies that arise when different people research the same competitor independently
- Comparative analysis on demand: Users can ask for head-to-head comparisons, feature gap analyses, and positioning differentiators between any combination of tracked competitors, receiving structured responses that are immediately usable in sales conversations or strategy discussions
- Time savings at scale: The hours previously spent by product marketing researching competitive questions, building battle cards, and briefing sales teams are largely automated, freeing strategic resources for higher-value competitive strategy work
Problem Addressed
Competitive intelligence is one of the most requested and least scalable functions in most marketing organizations. Sales teams need competitive positioning before every deal. Product teams need feature comparisons for roadmap planning. Executives need competitive context for strategic decisions. Each request triggers a research effort that consumes product marketing time and produces outputs that are accurate only at the moment they are created.
The core problem is that competitive information lives in an unstructured state — scattered across analyst reports, competitor websites, press releases, customer feedback, and the institutional memory of product marketing team members. Every competitive question requires someone to reassemble relevant facts from these disparate sources, assess their currency, and synthesize an answer. When the same question is asked by different people, it gets researched independently each time. The organization needed a system where competitive facts were captured once in a structured format, continuously maintained, and queryable by anyone through natural language without requiring product marketing to act as an intermediary.
What the Agent Does
The agent operates as a conversational competitive intelligence platform backed by a structured, continuously maintained fact database:
- Fact database architecture: For each tracked competitor, the agent maintains structured collections of verified facts organized by category: product features, pricing and packaging, recent releases, executive leadership, market positioning, customer base, partnerships, and technical architecture
- Natural language query processing: Users ask competitive questions in plain language — such as comparing feature sets, requesting positioning guidance for a specific deal, or asking about a competitor's recent product announcements — and the agent retrieves and synthesizes relevant facts
- Multi-competitor comparison: The agent can execute comparative analyses across any subset of tracked competitors, producing structured comparison matrices for features, pricing, market positioning, or any other dimension stored in the fact database
- Context-aware response synthesis: Responses are tailored to the query context. A sales-focused question gets battle-card-style positioning. A strategic question gets market analysis. A technical question gets feature-level comparison detail
- Source attribution: Every competitive claim in the agent's response is traceable to its source fact in the database, including when the fact was last verified, enabling users to assess the currency and reliability of the intelligence
- Cross-reference with internal data: The agent compares competitive facts against the organization's own product capabilities, identifying areas of advantage, parity, and gap for each competitor across tracked dimensions
Standout Features
- Structured fact architecture: Unlike document-based competitive intelligence that degrades as it ages, the structured database format ensures that individual facts can be updated independently, keeping the entire competitive picture current even when only specific data points change
- Multi-competitor depth: The system maintains deep profiles across all tracked competitors simultaneously, making it equally effective for analyzing a primary competitor as for comparing niche players in a specific market segment
- Conversational accessibility: Users interact with the competitive database through natural language rather than structured queries or navigation interfaces, lowering the barrier to access and enabling ad-hoc competitive research during live customer conversations
- Positioning guidance generation: Beyond raw facts, the agent synthesizes positioning recommendations that explain how to frame the organization's strengths relative to a specific competitor's weaknesses in the context of a given deal or market scenario
- Trend tracking: The agent identifies patterns in competitor activity over time, such as accelerating release cadence, pricing pressure, or market segment expansion, providing strategic context that individual fact queries would not reveal
Who This Agent Is For
This agent is built for organizations where competitive intelligence is a constant operational need rather than an occasional research project.
- Sales teams who need instant competitive positioning, objection handling, and differentiation guidance before and during customer conversations
- Product marketing managers responsible for maintaining competitive battle cards, positioning frameworks, and analyst briefing materials
- Product teams evaluating competitor feature sets and release patterns to inform roadmap prioritization and differentiation strategy
- Executive leadership who need current competitive context for strategic planning, board presentations, and investor communications
- Competitive intelligence analysts who want to spend their time on strategic analysis rather than repetitive fact-finding for internal stakeholders
Ideal for: Technology vendors, SaaS companies, financial services firms, consulting organizations, and any enterprise operating in a competitive market where real-time intelligence provides a measurable advantage.
Review Distribution AI Agent
AI agent that aggregates new peer reviews, identifies high-quality candidates for distribution, and delivers channel-specific positioning for social media, sales enablement, and marketing.
Benefits
Customer reviews are one of the most powerful marketing assets an organization produces, yet most teams capture less than ten percent of their distribution potential. This agent fixes that.
- Automated review discovery: New reviews are detected and ingested automatically as they appear on peer review platforms, eliminating the manual process of checking for new submissions and copying content into tracking spreadsheets
- AI-powered quality scoring: Each review is evaluated for specificity, quotability, sentiment strength, and use case relevance, ensuring that only the most impactful reviews are selected for distribution rather than defaulting to the most recent
- Channel-specific positioning: The agent generates tailored distribution packages for each channel — social media posts, sales battle cards, email marketing snippets, website testimonials, and analyst relations evidence — formatted for immediate use
- Faster time-to-distribution: The gap between a review being published and the marketing team leveraging it shrinks from weeks to hours, maximizing the relevance and timeliness of customer proof points
- Sales enablement integration: High-quality reviews are automatically packaged with competitive context and use case alignment, giving sales teams ready-made proof points they can drop into prospect conversations
- Volume tracking and trend analysis: The agent maintains a running database of all reviews with scores and distribution status, enabling reporting on review volume trends, sentiment shifts, and distribution coverage over time
Problem Addressed
Organizations invest heavily in driving customers to peer review platforms, but the return on that investment is limited by how quickly and effectively the resulting reviews are leveraged across marketing channels. A five-star review with specific use case details and quantified outcomes is a powerful sales and marketing asset — but only if someone finds it, recognizes its value, adapts it for each distribution channel, and gets it into the hands of the teams that can use it.
In most organizations, this process is manual, inconsistent, and slow. Product marketing checks the review platform periodically, skims new reviews, flags a few that seem good, and eventually creates social posts or adds quotes to sales materials. Reviews that arrive during busy periods get missed entirely. High-quality reviews from less visible categories or competitor comparison pages are overlooked because nobody is monitoring those specific views. The result is that the organization's best customer advocacy sits unused on third-party platforms while marketing teams struggle to source fresh proof points for campaigns and sales conversations.
What the Agent Does
The agent operates as an automated review intelligence and distribution pipeline that continuously identifies and packages high-value customer reviews:
- Review aggregation: The agent monitors peer review platforms for new submissions, pulling in review text, star ratings, reviewer metadata (title, company size, industry), and any structured response data (feature ratings, pros/cons)
- Quality scoring: Each review is scored across multiple dimensions including overall sentiment, specificity of claims, presence of quantified outcomes, relevance to key use cases, and quotability of individual sentences
- Top review selection: Reviews exceeding configurable quality thresholds are flagged as distribution candidates, with the highest-scoring reviews escalated for priority distribution
- Channel positioning generation: For each selected review, the agent generates distribution-ready content packages including social media posts, email marketing snippets, sales enablement quotes, and website testimonial formats
- Competitive context tagging: Reviews that mention competitors or comparative evaluations are tagged with competitive intelligence metadata, making them especially valuable for sales battle cards and competitive positioning materials
- Distribution notification: Packaged reviews are delivered via email digest to configurable recipient lists, with separate distributions for social media teams, sales enablement, and product marketing based on review content and use case alignment
Standout Features
- Multi-dimensional quality scoring: The scoring engine evaluates reviews across sentiment, specificity, quotability, and strategic relevance simultaneously, identifying the reviews that will have the most impact in distribution rather than simply selecting the highest star ratings
- Channel-optimized content generation: Each distribution channel receives content formatted for its specific requirements. Social posts are concise and engaging. Sales quotes include context and attribution. Email snippets include supporting data points
- Competitive mention extraction: When reviewers mention competitors by name or reference competitive evaluations, the agent extracts those comparisons and packages them specifically for competitive intelligence and sales enablement use
- Trend and volume analytics: Beyond individual review distribution, the agent provides aggregate analytics on review volume trends, average sentiment scores, frequently mentioned features, and category ranking changes
- Distribution tracking: Every review and its generated content packages are tracked through the distribution lifecycle, enabling reporting on which reviews were used, in which channels, and how distribution velocity compares to review arrival rate
Who This Agent Is For
This agent is built for marketing organizations that want to systematically convert customer reviews into multi-channel marketing assets at scale.
- Product marketing managers responsible for sourcing and distributing customer proof points across sales, marketing, and analyst relations channels
- Social media teams who need a steady stream of authentic customer quotes formatted for platform-specific posting
- Sales enablement professionals building competitive battle cards and proof point libraries that require fresh, relevant customer evidence
- Customer marketing teams managing review generation programs who need to demonstrate ROI by tracking distribution and usage of generated reviews
- Marketing leadership seeking visibility into review sentiment trends and competitive positioning as reflected in customer feedback
Ideal for: SaaS companies, technology vendors, professional services firms, and any organization that actively generates peer reviews and wants to maximize their marketing and sales impact.

SEO Page Optimizer AI Agent
AI agent that pulls SEO performance data and best practices to analyze page structure and recommend changes for maximum search engine performance and efficiency.
Benefits
This agent encodes the full SEO audit process into an automated system that produces technically precise, page-specific optimization plans.
- Systematic coverage: Every page in the site receives a structured SEO analysis on a regular cadence, eliminating the common pattern where only high-priority pages get audited while the rest of the site accumulates technical debt
- Best-practice enforcement: The agent evaluates page structure against a continuously updated library of SEO standards, catching violations like missing meta descriptions, improper heading hierarchies, thin content, and canonical issues automatically
- Data-backed prioritization: Recommendations are weighted by current search performance data, so pages with high impression volume but low click-through rates are prioritized over pages that receive minimal search traffic
- Structural optimization: Beyond keyword targeting, the agent analyzes HTML structure, internal linking patterns, schema markup, page speed factors, and mobile rendering to address the technical foundations that determine search visibility
- Consistent audit quality: Automated analysis eliminates the variability between different SEO analysts or audit tools, producing uniform, comprehensive assessments that follow the same evaluation framework every time
- Reduced audit costs: Organizations that previously relied on quarterly agency audits or expensive enterprise SEO tools can run continuous, automated analysis at a fraction of the cost
Problem Addressed
Search engine optimization for large websites involves a set of technical and structural requirements that are difficult to maintain consistently across hundreds or thousands of pages. Each page must adhere to heading hierarchy standards, contain appropriate meta tags, use semantic HTML correctly, implement structured data markup, maintain internal linking relevance, and avoid technical issues like duplicate content, broken links, or slow load times.
SEO teams typically address these requirements through periodic audits that produce a snapshot of issues at a point in time. Between audits, new pages are published without SEO review, existing pages are modified in ways that introduce structural problems, and search algorithm updates change which factors matter most. The result is a constant cycle of audit, remediate, and re-audit that never fully catches up with the rate of change. The organization needed a system that could continuously evaluate every page against current SEO standards, combine structural analysis with actual performance data, and produce specific, prioritized recommendations that the web team could execute immediately.
What the Agent Does
The agent operates as a continuous SEO audit engine that evaluates page structure, content quality, and search performance to produce actionable optimization plans:
- Structural analysis: Each page is evaluated for HTML heading hierarchy compliance, meta tag completeness, canonical tag configuration, hreflang implementation, and other structural SEO requirements
- Content quality assessment: The agent analyzes content length, keyword density, topic coverage depth, readability scores, and content freshness to identify pages that are thin, off-topic, or outdated relative to their target queries
- Technical SEO evaluation: Page speed metrics, mobile rendering quality, Core Web Vitals scores, JavaScript rendering dependencies, and crawlability factors are assessed to identify technical barriers to search performance
- Performance data integration: Search console data including impressions, clicks, click-through rates, and average position for each page's ranking queries is combined with the structural analysis to prioritize recommendations by actual search impact
- Schema and structured data review: The agent verifies that appropriate schema markup is implemented correctly for each page type, identifying missing or malformed structured data that could enhance search result appearance
- Recommendation generation: The combined analysis produces a ranked list of specific changes for each page, with clear descriptions of the issue, the recommended fix, the expected impact, and implementation guidance
Standout Features
- Continuous audit cadence: Unlike point-in-time audits, the agent runs on a configurable schedule, catching new issues as they are introduced and verifying that previous recommendations were implemented correctly
- Algorithm-aware recommendations: The best-practice library is regularly updated to reflect current search engine ranking factors, ensuring that recommendations align with how search algorithms actually evaluate pages today
- Competitive gap analysis: For target keywords where competing pages outrank the site, the agent analyzes the structural and content differences between the ranking page and the site's page, producing specific recommendations to close the gap
- Internal linking optimization: The agent maps the site's internal link graph and identifies pages that are under-linked relative to their strategic importance, recommending specific internal linking changes to improve crawl efficiency and authority distribution
- Regression detection: When a previously optimized page experiences a ranking decline, the agent automatically investigates whether structural changes, content modifications, or technical issues caused the regression
Who This Agent Is For
This agent is designed for SEO teams and web marketers who need to maintain search optimization standards across large, frequently changing websites.
- SEO specialists responsible for maintaining technical SEO health across websites with hundreds or thousands of pages that change regularly
- Content marketing teams who need to ensure that published content meets structural SEO requirements without requiring manual review of every page
- Web development teams who need automated verification that code changes and CMS updates do not introduce SEO regressions
- Marketing operations teams building systematic SEO workflows that scale optimization effort across the entire site rather than concentrating on top pages
- Digital marketing leaders who need visibility into SEO health metrics and optimization progress across the full website portfolio
Ideal for: Content-heavy websites, e-commerce platforms, SaaS marketing sites, media publishers, and any organization where organic search traffic is a significant channel that requires continuous technical optimization.

Landing Page Optimizer AI Agent
AI agent that pulls from analytics, search data, and other sources to analyze landing page performance and generate specific optimization recommendations for increased conversion rates.
Benefits
If you have ever stared at analytics dashboards trying to figure out why a landing page is underperforming, this agent does that analysis for you and tells you exactly what to fix.
- Multi-source analysis in one pass: The agent combines traffic data, search performance metrics, user behavior signals, and conversion data from multiple platforms into a unified page-level analysis, eliminating the manual work of cross-referencing different analytics tools
- Specific, actionable recommendations: Instead of generic optimization advice, the agent generates page-specific recommendations based on that page's actual performance data, traffic sources, keyword rankings, and conversion patterns
- Priority-ranked improvements: Recommendations are ranked by projected conversion impact, so marketing teams work on the changes most likely to move the needle rather than optimizing based on gut instinct
- Scale across the entire site: The agent analyzes every landing page in the portfolio automatically, identifying optimization opportunities across hundreds of pages that manual review would never cover
- Continuous monitoring: As performance data updates, the agent re-evaluates its recommendations, ensuring that optimization guidance stays current as traffic patterns, search rankings, and user behavior evolve
- Reduced agency dependency: Marketing teams can execute data-driven optimization programs internally rather than relying on expensive external agencies or consultants for landing page audits
Problem Addressed
Marketing teams managing large websites face an optimization challenge that compounds with every new landing page they create. Each page has its own traffic profile, keyword targeting, user behavior patterns, and conversion funnel. Identifying what is working and what needs improvement requires analyzing data from multiple platforms, cross-referencing traffic sources with conversion outcomes, and understanding how search performance connects to on-page experience.
In practice, most marketing teams only optimize their highest-traffic pages because manual analysis is too time-consuming to cover the full site. Mid-tier and long-tail pages that collectively represent significant conversion volume go unoptimized indefinitely. When optimization does happen, it tends to follow generic best practices rather than data-specific insights, because the effort required to build a custom analysis for each page exceeds available capacity. The organization needed a system that could analyze every page in the portfolio, pull performance data from all relevant sources, and generate specific, data-backed recommendations at scale.
What the Agent Does
The agent operates as an automated landing page analyst that continuously evaluates performance data and generates targeted optimization recommendations:
- Traffic analysis: The agent ingests page-level traffic data including session volume, source distribution, bounce rates, time on page, and scroll depth to establish a behavioral baseline for each landing page
- Search performance integration: Keyword ranking data, click-through rates, search impression volumes, and position trends are pulled from search platforms and mapped to each landing page's target keyword set
- Conversion funnel analysis: The agent traces the conversion path from page entry through form submission or purchase completion, identifying specific funnel stages where drop-off exceeds benchmarks
- Competitive benchmarking: Where available, the agent compares page performance metrics against industry benchmarks and competitor page data to identify relative strengths and gaps
- Recommendation generation: Based on the combined analysis, the agent generates specific recommendations for each page, including content changes, layout adjustments, CTA modifications, load speed improvements, and mobile optimization priorities
- Impact projection: Each recommendation includes a projected conversion impact estimate based on the severity of the identified issue, the page's traffic volume, and historical performance patterns from similar optimizations
Standout Features
- Cross-platform data fusion: The agent pulls from multiple analytics and search platforms simultaneously, creating a richer analysis than any single data source could provide and identifying optimization opportunities that only become visible when data is combined
- Page-level specificity: Every recommendation is tailored to the individual page's performance data, not generic advice applied uniformly. A high-traffic page with low conversion gets different recommendations than a low-traffic page with high engagement
- Automated prioritization: The agent ranks all recommendations across all pages by projected impact, creating a site-wide optimization backlog that teams can execute in the order most likely to improve total conversion volume
- Trend-aware analysis: The agent distinguishes between temporary performance fluctuations and sustained trends, ensuring that recommendations address real structural issues rather than reacting to noise in short-term data
- Before/after tracking: Once a recommendation is implemented, the agent monitors the affected metrics and reports whether the change produced the expected improvement, creating a feedback loop that refines future recommendations
Who This Agent Is For
This agent is designed for marketing teams that manage more landing pages than they can realistically optimize through manual analysis.
- Demand generation managers responsible for conversion rates across landing page portfolios who need data-driven optimization at scale
- Web marketing teams managing hundreds of landing pages who cannot manually analyze performance for every page in their portfolio
- Growth marketers running continuous optimization programs who need a constant stream of prioritized, data-backed improvement recommendations
- Marketing operations teams building systematic optimization workflows that replace ad-hoc page audits with structured, repeatable analysis
- CMOs and marketing VPs who need visibility into which pages represent the biggest conversion improvement opportunities across the site
Ideal for: SaaS companies, e-commerce businesses, financial services firms, media companies, and any organization with a large landing page portfolio where conversion optimization directly impacts revenue.