Stem-and-Leaf Plot: What It Is and How to Create One

Stem-and-leaf plots give data viz builders a way to show distribution shape without losing sight of exact values. This article walks through data requirements and step-by-step construction of stem-and-leaf plots, along with common variants such as back-to-back plots and the practical tradeoffs between them. You will also learn how to spot errors that distort your results and when to bring this visualization into a governed BI environment.
What a stem-and-leaf plot is
Distribution and raw data points in one view? That's the promise here. A stem-and-leaf plot displays numerical data so you can see both the shape of a distribution and every individual value. The stem represents the leading digits of your numbers. The leaf represents the trailing digit. Together they reconstruct each original value perfectly.
You might also hear this called a stemplot or stem and leaf display.
For a data analyst or BI specialist doing quick exploratory analysis, this plot is especially handy. It's also helpful for anyone who needs to explain "where the numbers actually land" to a line of business manager who is tired of hearing only averages.
Here's how the structure works. For the number 47, the stem is 4 and the leaf is 7. You always need a key to decode the numbers, like this: Key: 6|2 = 62Wh
Whereas a histogram shows frequency by bin but throws away the exact values inside those bins, a stem-and-leaf plot keeps every value readable while still showing you the distribution shape. When you need to verify specific data points or identify exactly which values cluster together, this distinction matters.
Data requirements for a stem-and-leaf plot
Aim to get your data into a shape that won't fight you before you build. At minimum, you need one field (or one column) of numerical values. For teams working in BI, it also helps when that field comes from a governed data set, so the chart inherits the same access rules and audit trail as the rest of your environment.
A few practical requirements to check:
If you're building this in a spreadsheet like Excel, or in R or Python notebooks, this "data cleanup" step tends to turn into a mini project. It's unsurprising, then, that employees spend up to 27 percent of their time correcting bad data. That's more than a quarter of the workweek lost to fixing what should already be clean. In a BI tool, your analytics engineer or data engineer can standardize the transformations once, then feed the same clean field into every stem-and-leaf plot chart without rework.
How to create a stem-and-leaf plot step by step
Your first decision shapes everything else. You need to choose the stem unit based on your data range. If your data runs from 15 to 98, the tens digit becomes the stem. If you have decimals like 1.2 to 4.7, the ones digit becomes the stem and the decimal becomes the leaf.
For three-digit numbers, the approach shifts slightly. A number like 145 gets a stem of 14 and a leaf of five.
Step 1: Choose the stem unit
Aim for five to 15 stems. Fewer than five compresses the distribution too much, and you'll miss important variation. More than 15 stretches it thin and makes clusters hard to spot.
Step 2: List all stems in order
Write your stems vertically from lowest to highest. Include empty stems where no data falls. Skipping them distorts the visual gaps and hides where data is absent.
Step 3: Add and sort leaves
Place each leaf digit next to its stem. Sort the leaves in ascending order within each row. Unsorted leaves make finding the median slower and more error-prone.
Step 4: Add the key
Always include a stem and leaf plot key showing how to reconstruct a value:
Key: 3|7 = 37
Key: 2|4 = 2.4
After building your plot, count the total leaves. That number should match your data set size exactly. If it doesn't, you missed something or duplicated a value.
Of course, manual reconstruction in a spreadsheet gets old fast. It's also easy to ship the wrong version to a stakeholder.
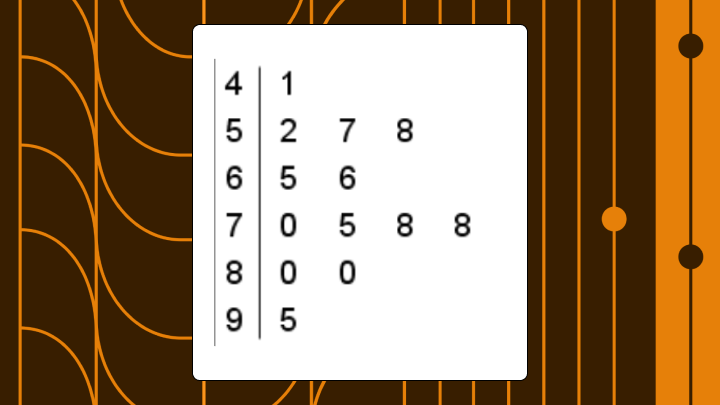
Stem-and-leaf plot example with interpretation
A concrete example makes this clearer. Here's a small dataset:
23, 27, 31, 35, 35, 42, 44, 48, 51, 56, 62
And here's the completed plot:
2 | 3 7
3 | 1 5 5
4 | 2 4 8
5 | 1 6
6 | 2
Key: 3|5 = 35
What can you see immediately? The distribution is roughly symmetric with values concentrated in the 30s and 40s. With 11 values, the median sits at position six. Counting left to right and top to bottom, that's 42.
The range is 62 minus 23, which equals 39. The mode is 35 because it appears twice while nothing else repeats.
This format reveals details that summary statistics hide. You can see the 35 appears twice. There's a gap in the 20s after 27. The 60s have only one lonely value. And honestly, that granularity is the part most guides skip over when they rush to histograms.
How to read a stem-and-leaf plot and identify patterns
Start with the key, always. Without it, you're guessing.
Then scan the stem column to see the range of leading digits. Look at how many leaves sit in each row to spot where values cluster. Check for empty stems that signal gaps in your data.
If you're sharing the stem-and-leaf plot chart with non-technical stakeholders (say, a finance or operations manager), narrate the pattern in plain terms: "Most values live in these stems, and these few leaves are the outliers." That's the bridge from statistical shape to decision.
Visual patterns translate directly to statistical terms:
The plot won't calculate statistics for you. You still need to count leaves to find the median position.
How to find median, mode, and range from the plot
The values already appear in order. That makes finding statistics faster than working from raw data.
For the median, count total leaves (n). If n is odd, the median is at position (n+1)/2. If n is even, average the values at positions n/2 and (n/2)+1. Read leaves left to right, top to bottom, counting until you reach that position. Counting leaves out of order because they weren't sorted properly in the first place will throw off your calculation, so verify your leaves are sorted before calculating.
For the mode, scan each row for repeated leaf digits. The value appearing most frequently wins. No repeats? No mode.
For the range, find the smallest value (first leaf on the first stem with data) and the largest (last leaf on the last stem). Subtract.
Quartiles work similarly. Q1 is the median of the lower half. Q3 is the median of the upper half. The interquartile range (IQR) equals Q3 minus Q1.
Some analysts flag potential outliers using Tukey fences. Calculate the lower fence as Q1 minus 1.5 times the IQR. The upper fence is Q3 plus 1.5 times the IQR.
Stem-and-leaf plot variants that change how you interpret data
The basic format of a stem-and-leaf breaks down in certain situations, and you'll need a plan for how to fix it.
Back-to-back stem-and-leaf plot
Comparing two groups on the same variable? Put the stem column in the center. One group's leaves extend left, the other's extend right. Shape comparison becomes immediate.
This works well for comparing test scores between two classes or response times between two systems. It's also a clean way to compare operational cycle times across two teams, or sales values across two regions, without hiding the exact data points. Both groups must use the same stem unit or the comparison falls apart.
Split stems
When a single stem accumulates too many leaves, the row becomes unreadable. Split each stem into two rows: one for leaves zero through four, another for five through nine.
If any stem has more than 10 to 15 leaves, splitting helps. But it creates more rows, which can stretch a compact distribution unnecessarily. You'll notice this tension between readability and compactness shows up a lot in practice. There's no universal answer.
Decimal leaf units
For data with decimal precision, the integer becomes the stem and the first decimal digit becomes the leaf.
Key: 3|7 = 3.7
This works cleanly for one decimal place. Two or more decimal places require rounding or a different chart type entirely.
When to use a stem-and-leaf plot instead of a histogram or box plot
Data set size drives this decision more than anything else. Use a stem-and-leaf plot when your data set has about 50 to 100 values (or fewer) and you need to see individual data points. It is ideal when you want distribution shape and exact values in one view.
Use a histogram when your data set exceeds 100 values or when exact values do not matter. Histograms handle massive scale without becoming an unreadable wall of digits. They also give you flexibility in bin width that stem-and-leaf plots cannot match.
Use a box plot when comparing distributions across many groups or when summary statistics matter more than shape details. Box plots condense data into boundaries that fit easily side by side.
The stem-and-leaf plot ties bin width to place value. You can't adjust granularity the way you can with histogram bins. If your data doesn't fit neatly into decimal-based groupings, a histogram gives you more control.
One more practical filter if you work in an enterprise BI environment: distribution charts that live outside your dashboards are harder to share, harder to version, and harder to govern. Stack Overflow found that 35 percent of developers use six to 10 distinct tools in their workflows. That fragmentation makes it easy for a stem-and-leaf plot built in one tool to fall out of sync with dashboards maintained elsewhere.
Errors that distort a stem-and-leaf plot
These mistakes make stem-and-leaf plots misleading or unreadable:
Before sharing your chart, run through this validation:
If you're emailing screenshots around or copying a plot into a slide deck, add one more habit: Make sure the chart points back to the same governed data set as the rest of your reporting. That's how teams avoid "Which file is the source of truth?" debates. IBM research links poor data quality to multimillion-dollar annual losses for many organizations. For stem-and-leaf plots specifically, that governance gap often surfaces when someone rebuilds the plot manually and accidentally uses a stale data extract.
Chart checklist for stem-and-leaf plots
A quick sanity check before finalizing any plot: Your minimum data set needs just one column of numerical values. The total leaf count must equal your data set size. The plot should reveal the distribution shape while preserving every individual value.
Watch for this misleading pattern: A stem with many leaves can look like a strong cluster. But if those leaves span the full zero through nine range, the data within that stem is actually spread out. Visual density doesn't always mean tight clustering.
If you want the quick version, here are the key takeaways:
Stem-and-leaf plots in business intelligence tools
When your analysis moves past small samples, a BI platform handles the scale that stem-and-leaf plots cannot. It can connect to your data sources, automate distribution visualizations, and let you switch between chart types as your dataset grows.
For exploratory work on small data sets where you need exact values visible, stem-and-leaf plots remain useful. For production dashboards or larger data sets, histogram and box plot visualizations stay readable at scale.
If your team wants a stem-and-leaf plot chart inside the same governed environment as everything else, a tool like Domo supports custom and advanced chart types through its app and visualization framework. BI specialists and analytics engineers can build a reusable stem-and-leaf plot chart component with Domo's Code Engine and custom app capabilities, then share it across dashboards and more.
And for the people who care (a lot) about governance, that same approach keeps the visualization tied to governed data sets, so row-level security, access controls, and audit trails carry through. Data engineers can also prep the stems and leaves with Magic ETL or SQL transformations, and store reusable logic or supporting tables in AppDB, so the chart stays consistent from team to team.
If you're ready to bring distribution analysis into the same governed workflow as your dashboards (without getting stuck in spreadsheet busywork), watch a demo and see how Domo helps you move from quick exploration to shareable, scalable visuals.