Hai risparmiato centinaia di ore di processi manuali per la previsione del numero di visualizzazioni del gioco utilizzando il motore di flusso di dati automatizzato di Domo.
Guarda il video
.png)

Connecting AI models to external tools has traditionally meant building custom integrations for every combination of model and system. The Model Context Protocol (MCP) changes that tradition by creating a shared interface that works across AI platforms like Claude, ChatGPT, and other models. This article breaks down how MCP works, when to use it, and what it means for teams building production AI systems.
If you only remember a few things, remember these:
The Model Context Protocol (MCP) is an open standard that gives AI models a consistent way to connect with external tools, databases, and applications. It's like the USB-C for AI. Before USB-C, every phone had its own charger. MCP aims to be that universal connector for AI integrations.
Here's the problem it solves. Say you want your AI assistant (or a full-on AI agent) to query your customer relationship management (CRM) system, pull data from your warehouse, and update your project management tool. Without a standard, each of those connections requires custom code. And that code breaks whenever either side updates.
Data engineers, AI/ML engineers, and enterprise architects are paying attention for good reason. This isn't yet another integration framework. It's a protocol layer that turns tool access into something you can design once and keep stable as models, apps, and vendors change.
The math gets ugly fast. Three models talking to four tools means 12 custom integrations. MCP turns that multiplication problem into addition by creating a shared interface.
The protocol exposes three primitives that define what AI models can do:
One clarification that trips people up: MCP isn't a runtime, an AI model, nor a replacement for retrieval augmented generation (RAG) or function calling. It standardizes how those capabilities get exposed to models. Teams sometimes assume MCP handles orchestration or workflow logic. It doesn't. You still need separate tooling for multistep agent coordination.
If you're thinking about production agents, here's the practical translation: MCP gives an agent a predictable "menu" of approved tools and governed data it can request inside its context window (the model's working memory for a single conversation), then a structured way to call those tools during agent execution.
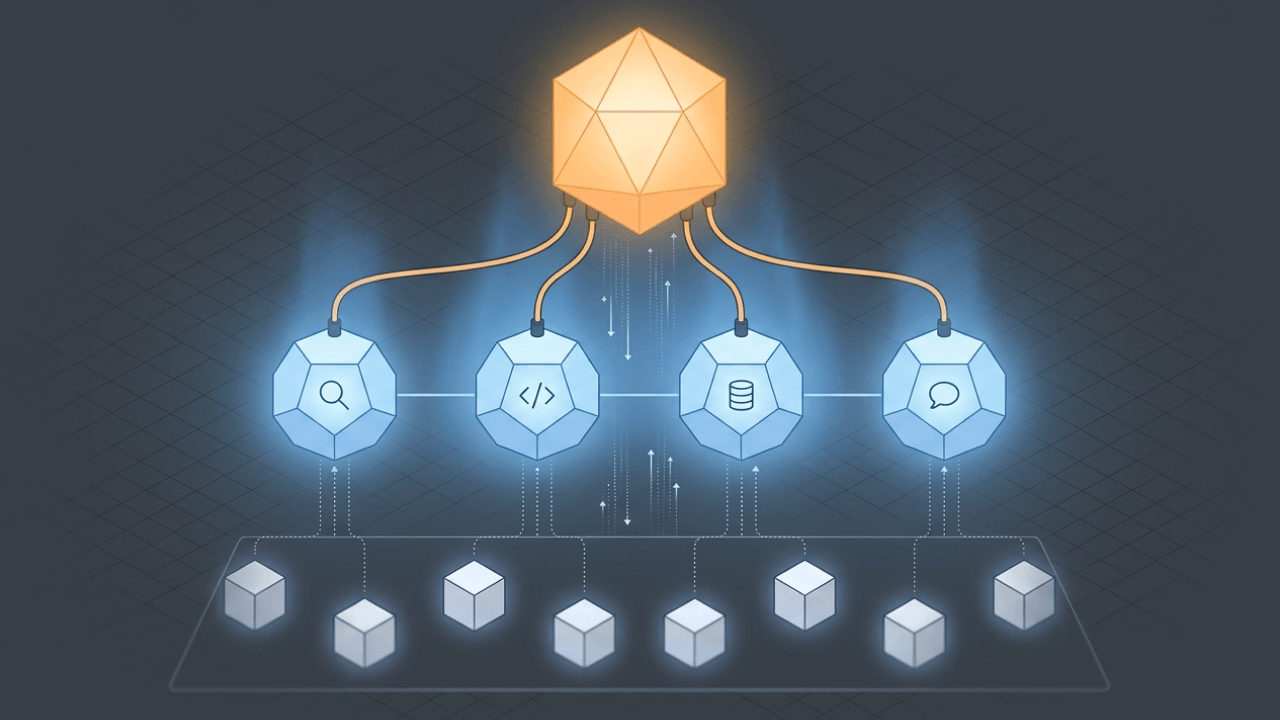
Which component decides what the model can do? Which component actually executes actions? When you give an AI model access to your tools, these questions matter. MCP separates these concerns across three roles.
This separation matters for IT leaders and data leaders. It creates clearer trust boundaries. You can decide where policy lives (in the host) and where credentials and execution live (in the server), instead of mixing everything into one giant, hard-to-audit integration.
The host is the application you interact with directly. Claude Desktop, an integrated development environment (IDE) like Cursor, or a custom AI application your team built. It manages your session, maintains security boundaries, and decides which MCP servers to connect to.
In agentic setups, the host is also where orchestration often lives. That might mean deciding when to ask for human approval, how to route tasks across tools, or which model to use for a step in a multi-step workflow. MCP doesn't dictate those decisions. It just makes the tool layer consistent.
One host can connect to multiple servers at once. You might have one server for your database, another for your calendar, and a third for your file system, all running simultaneously.
The client handles the actual protocol communication. It lives inside the host and manages capability discovery, message formatting, and response parsing. Most teams never build clients directly (they use SDKs in Python or TypeScript that handle this layer).
Each client maintains a one-to-one connection with a server. Three servers means three client instances running under the hood.
This is where the action happens.
An MCP server wraps an external system, whether that's a database, an API, or a file system, and translates its capabilities into the MCP protocol. Servers can run locally on your machine or remotely in a cloud environment. A Postgres server might expose query and schema inspection tools. A Slack server might expose message sending and channel reading. Anthropic maintains a registry of reference implementations, and the community has built servers for Jira, Salesforce, BigQuery, GitHub, and dozens of other systems.
For data engineers, this is the "okay, but where does it touch my pipeline?" moment. In practice, an MCP server often sits next to the systems you already manage: your data warehouse, your operational APIs, your BI semantic layer, or even governed file storage. It then publishes the safest possible set of actions as tools and the safest possible data as resources.
MCP supports two ways to move data between client and server:
Local stdio servers inherit the host machine's permissions. Simpler setup, but limited to local deployment. Remote HTTP servers add latency but enable cloud deployment and multi-tenant architectures.
If you're designing for hybrid environments, this matters. A local stdio server can be great for developer productivity in an IDE, while HTTP with SSE fits better when you need centralized governance, shared servers, and consistent audit trails across teams.
When someone asks an AI assistant to check their latest sales numbers, the model doesn't magically know how to query the database. MCP defines the handshake that makes this possible.
It also creates a cleaner mental model for AI/ML engineers: context gets passed in (capabilities, schemas, resources), then structured tool invocations happen during execution, then results come back as machine-readable outputs the model can reason over.
When a host connects to an MCP server, the client requests the server's capability manifest. The server responds with a structured list of available tools, resources, and prompts, including names, descriptions, and input schemas.
This happens once at connection time. The host then presents these capabilities to the model as part of its context, so the model knows what actions are available.
In a governed enterprise setup, the manifest is also where you can be intentional about business context. Instead of exposing "run arbitrary SQL," you might expose "get pipeline status," "get approved sales metrics," or "pull last 30 days of forecast variance." Same underlying systems, very different risk profile.
When the model decides to use a tool, it generates a structured request matching the tool's schema. The client forwards this to the appropriate server, which executes the action and returns results.
Tools perform actions and allow side effects. Resources provide read-only data. This distinction matters for security. You might let a model read resources freely while requiring approval for tool invocations.
Multi-step agent workflows start to click here. An agent can:
MCP does not force the workflow. It just makes the "read vs act" boundary explicit and consistent.
The server returns results as structured JSON. The client passes these back to the model, which incorporates them into its response.
For large query results or real-time data, MCP supports chunked responses via SSE. The model can start generating output before the full response arrives. Errors follow JavaScript Object Notation Remote Procedure Call (JSON-RPC) conventions, so servers return structured error codes the model can interpret.
You need your AI to access external data. You have options.
MCP and RAG actually complement each other. RAG handles static knowledge retrieval. MCP handles dynamic tool invocation. Many production systems use both, and confusing the two leads teams to implement MCP when they really need a vector database, or vice versa.
If you're an AI/ML engineer building agents, it helps to think of it this way:
When should you skip MCP entirely? If you only need one model talking to one tool, custom integration is simpler. If your tools require complex multi-step workflows, agent frameworks are more appropriate. If you're locked into a single model vendor with mature function calling, MCP adds overhead without portability benefits.
Adopting a new protocol requires justification, especially when Gartner predicts over 40 percent of agentic AI projects will be canceled by 2027 due to escalating costs and inadequate controls. That projection underscores why standardization matters. Teams without clear integration boundaries and governance structures are the ones most likely to see projects spiral.
The value shows up in long-term maintenance, not day-one setup.
Here's what teams usually care about once they move from demos to production:
If you're staring at your existing data stack and thinking, "Where does this fit without wrecking my pipelines," you're asking the right question.
MCP typically becomes the tool-access layer that sits close to the systems you already run:
For architectural engineers, the long-term win is modularity. If you standardize tool boundaries with MCP, you can change models, hosts, and even orchestration patterns without rebuilding the whole integration surface area.
If you're evaluating MCP adoption, these six checks keep you out of trouble:
That's the difference between "we connected an LLM to stuff" and "we shipped an enterprise agent system we can actually defend in a security review."
An AI model with tool access can query databases, send messages, and modify records. Without controls, a prompt injection attack or misconfigured permission could expose sensitive data.
MCP servers should implement OAuth 2.0 or API key authentication for remote deployments. Hosts must enforce least-privilege access, only connecting to servers the person is authorized to use. Consider tool-level permissions: allow reading resources freely while requiring approval for write operations.
Return only necessary fields from queries. Implement audit logging for all tool invocations. Use mutual TLS (mTLS) for remote server communication.
Prompt injection is a real concern when models execute actions. Validate tool inputs against schemas before execution. Implement allowlists for permitted operations. For high-risk actions, require human approval. Teams often validate inputs but forget to sanitize outputs before passing them back to the model. This creates a vector for indirect injection attacks through returned data, which, if not careful, can bite teams who thought they had security locked down.
If your MCP servers access personally identifiable information or regulated data, standard compliance requirements apply. GDPR, HIPAA, and SOC 2 rules govern MCP traffic exactly as they govern direct database access.
For IT leaders, MCP is less about "cool agent features" and more about governance hygiene. You want to know:
MCP doesn't solve all of that by itself. But it makes those questions easier to ask.
MCP standardizes how AI models connect to tools, but production deployments still need governed data access, audit trails, and enterprise-grade security. Connecting an AI model directly to raw data sources often bypasses the business logic and security policies your organization relies on.
Domo provides the governed data foundation that teams can put behind MCP servers (or any tool-calling agent architecture) so agents interact with trusted, permissioned context, not a free-for-all data dump.
More than 1,000 pre-built connectors can serve as the secure data layer you expose to AI agents. Centralized role-based access controls help ensure agents only access data people are authorized to see. Audit logging tracks what data agents accessed and what actions they triggered.
If you're building agents in Domo, Agent Catalyst delivers many of the architectural outcomes MCP is aiming for, without requiring you to implement a protocol layer from scratch:
MCP represents a shift toward standardized AI-to-tool connectivity, similar to how REST APIs standardized web service communication. For teams building AI applications that interact with external systems, it offers a path to reduce integration complexity and improve portability.
The protocol is still maturing. Expect the ecosystem of pre-built servers and host support to expand. Teams adopting MCP now benefit from early standardization while accepting some ecosystem gaps. It doesn't replace RAG or custom integrations. It provides a standard interface that makes AI tool access more maintainable.
Whether you adopt MCP directly or you're validating "MCP-like" patterns, you will want governed context, controlled tool access, and visibility into agent actions. If you want to see what that looks like in practice, watch a demo here.




.png)
.png)