Mit der automatisierten Datenfluss-Engine von Domo wurden Hunderte von Stunden manueller Prozesse bei der Vorhersage der Zuschauerzahlen von Spielen eingespart.
Schau dir das Video an
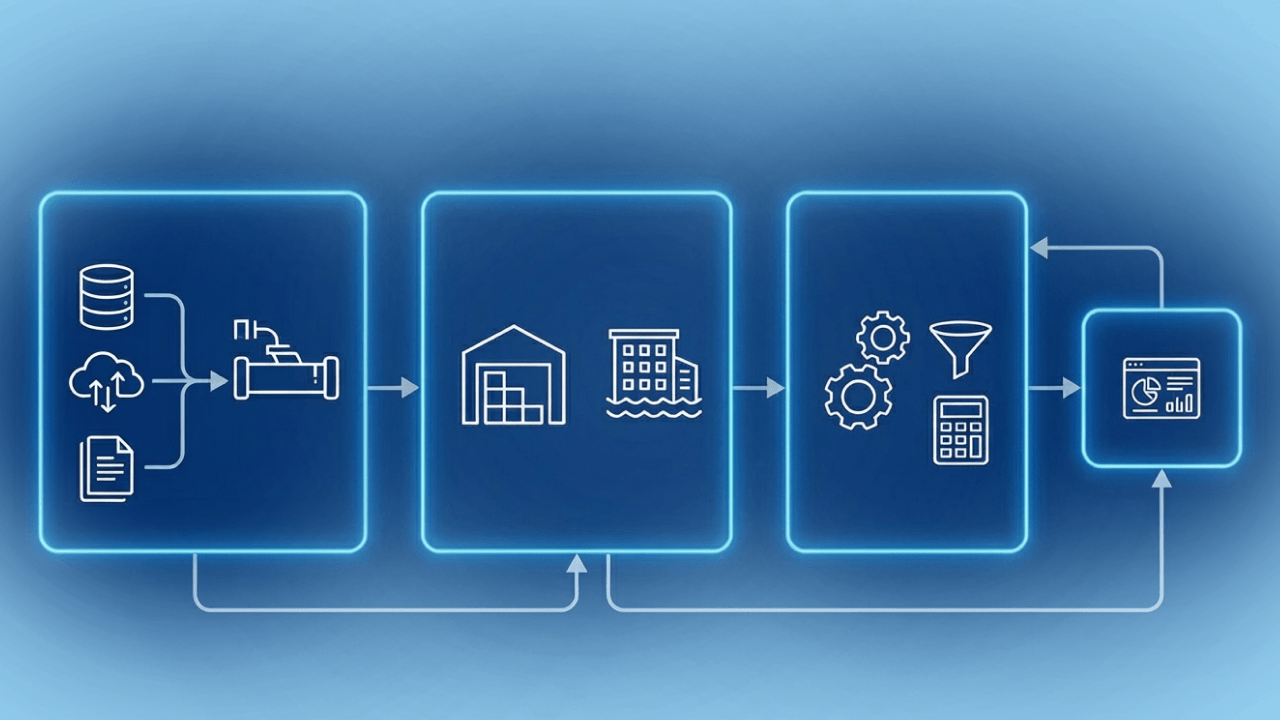

As organizations rely on data to guide strategy and operations, the way they move and prepare data has become just as important as the information it delivers. ETL architecture is central to this process, defining how data flows from source systems into analytics platforms in a reliable and scalable way. Without a clear architectural approach, data pipelines quickly become brittle, costly, and difficult to maintain.
In this blog, we’ll explore what ETL architecture is, the key components and layers that make it work, the benefits it provides, and the best practices for designing ETL systems that grow with your business.
ETL architecture refers to the structured framework used to extract data from source systems, transform it into a usable format, and load it into a destination such as a data warehouse, data lake, or analytics platform. It defines how data moves through an organization, how it’s processed along the way, and how reliability, performance, and scalability are maintained across the pipeline.
ETL architecture is designed to support ETL data migration by ensuring that data is collected from multiple systems, standardized, and delivered consistently to downstream environments. Source systems might include applications, databases, SaaS platforms, or streaming data sources, each producing data in different formats and structures. The architecture determines how these differences are handled and how data flows are orchestrated.
The transformation layer is where raw data becomes useful. Through cleansing, enrichment, normalization, and aggregation, data transformation ensures that information is accurate, consistent, and aligned with business definitions. This step is critical for turning fragmented inputs into reliable data sets that teams trust.
Finally, ETL architecture enables the delivery of actionable data. By organizing data pipelines in a repeatable and governed way, organizations ensure that analytics, reporting, and downstream applications are powered by timely, high-quality data. A well-designed ETL architecture lays the foundation for informed decision-making, operational efficiency, and scalable analytics across the business.
ETL architecture is made up of several interconnected components, each responsible for a specific part of the data pipeline. Organizing these components into clear layers makes ETL systems easier to scale, monitor, and maintain as data volumes and use cases grow.
The source layer is where data originates. This includes operational databases, SaaS applications, APIs, flat files, and event-based systems. Because each source can have different data formats, update frequencies, and access methods, ETL architecture must support flexible connectivity and reliable data integration across a wide range of systems.
The ingestion layer handles extracting data from source systems and moving it into the pipeline. This can happen on a scheduled basis using batch jobs or continuously through ETL streaming for near real-time use cases. Streaming ingestion is particularly valuable for time-sensitive analytics, operational monitoring, and event-driven workflows.
The transformation layer is where raw data is cleaned, validated, enriched, and standardized. Business rules are applied to align data with consistent definitions, remove duplicates, handle missing values, and reshape data sets for analytics. This layer plays a critical role in ensuring data quality and usability.
Once transformed, data is loaded into a destination such as a data warehouse, data lake, or analytics platform. This layer is optimized for querying, reporting, and downstream consumption, providing a centralized place for trusted data.
The orchestration and monitoring layer coordinates the entire ETL process. It manages job scheduling, dependencies, retries, and error handling while providing visibility into pipeline health and performance. This layer keeps ETL workflows running reliably and can scale as data demands evolve.
A well-designed ETL architecture provides more than just a way to move data. It creates a reliable foundation for analytics, reporting, and data-driven decision-making across the organization.
ETL architecture standardizes how data is extracted, transformed, and loaded, reducing inconsistencies across systems. By defining clear workflows and dependencies, each ETL pipeline produces predictable, repeatable results that teams can trust. This consistency is essential for accurate reporting and long-term scalability.
Built-in validation, cleansing, and transformation steps help ensure data accuracy before it reaches downstream systems. Clear ownership, standardized definitions, and access controls support strong data governance, making it easier to manage compliance, security, and audit requirements.
ETL architecture enables data automation by reducing manual intervention in data preparation and movement. Automated pipelines refresh data sets on schedule or in response to events, allowing teams to access timely information without waiting on manual processes.
According to TechTarget, ETL is the most common operating model for data automation. ETL supports data automation and ensures that data is clean, accurate, and properly formatted, empowering organizations to gain insights faster.
A modular ETL design makes it easier to scale individual components as data sources, users, and workloads increase. Teams can add new sources, transformations, or destinations without reengineering the entire system.
ETL architecture prepares data in formats optimized for analytics tools and dashboards. Clean, well-modeled data supports modern BI, enabling faster queries, interactive reporting, and more intuitive data exploration for business users.
By centralizing data processing logic, ETL architecture reduces duplicated effort across teams. This streamlining lowers operational overhead and allows data teams to focus on higher-value initiatives instead of constantly fixing or rebuilding pipelines.
The ETL process follows a simple conceptual flow: data is extracted from source systems, transformed to meet business and technical requirements, and then loaded into a destination for analysis or operational use. While the steps themselves are consistent, the way they’re implemented and performed depends heavily on the underlying ETL architecture.
During extraction, ETL processes pull data from databases, applications, files, APIs, or streaming sources. Architecture determines whether this extraction happens in batches, near real time, or continuously, as well as how systems handle connectivity, security, and error recovery. A well-designed architecture ensures that data can be extracted reliably without overloading source systems.
Transformation is where raw data becomes usable. Through cleansing, normalization, enrichment, and aggregation, ETL data transformation aligns disparate inputs with shared definitions and business logic. Architecture plays a critical role here by determining where transformations occur, how compute resources are allocated, and how transformation logic is reused and governed across pipelines.
The load phase delivers transformed data to its destination, such as a data warehouse, data lake, or analytics platform. Architecture influences performance, scalability, and data freshness by defining how data is written, partitioned, and optimized for downstream use.
Throughout this process, ETL tools operate within the architectural framework to orchestrate workflows, manage dependencies, monitor performance, and handle failures. Strong architecture ensures these tools can scale, adapt to new sources, and support evolving analytics. Ultimately, ETL architecture shapes how efficiently data moves from raw inputs to trusted insights.
Designing an effective ETL architecture requires balancing technical requirements, business goals, and long-term scalability. The right choices early on can prevent performance issues, rework, and complexity as data volumes and use cases grow.
Understanding how much data you’re processing and how frequently it changes helps determine whether batch processing, near real-time updates, or streaming ingestion is most appropriate. This decision directly impacts infrastructure, cost, and pipeline design.
ETL architecture should support a wide range of source systems, including databases, SaaS applications, files, APIs, and event streams. Flexible connectivity makes it easier to onboard new sources as the organization evolves.
Architecture should allow individual components to scale independently, ensuring that increases in data volume or query demand don’t degrade performance. Cloud-native designs often provide greater elasticity for this reason.\
Built-in validation, error handling, and monitoring help ensure data accuracy and reliability. Clear ownership, standardized definitions, and access controls support compliance and trust in downstream analytics.
ETL architectures should be modular, reusable, and easy to monitor. Choosing approaches that minimize operational overhead while providing visibility into pipeline health allows teams to manage ETL efficiently and focus on delivering value rather than constantly troubleshooting.
Designing ETL architecture with best practices in mind helps ensure your data pipelines are reliable, scalable, and easier to maintain over time. These principles can guide teams as data complexity grows.
Build ETL architecture that can scale as data volumes, users, and sources increase. Use modular components and cloud-native services where possible so compute and storage can grow independently without reengineering pipelines.
Keeping extraction, transformation, and loading logic clearly separated improves flexibility and maintainability. This approach makes it easier to update business rules, swap data sources, or change destinations without disrupting the entire pipeline.
Centralizing and reusing transformation logic ensures consistency across data sets. Standard definitions for metrics, dimensions, and business rules reduce duplication and prevent conflicting interpretations of data across teams.
Incorporate validation, deduplication, and error handling directly into ETL workflows. Catching data issues early prevents flawed data from propagating into analytics and downstream systems, where problems are harder to fix.
Design pipelines to process only the data that has changed and avoid unnecessary recomputation. Right-size resources and schedule workloads efficiently to balance performance with cost control.
Strong monitoring provides visibility into pipeline health, performance, and failures. Clear documentation helps teams understand data flows, dependencies, and ownership, making troubleshooting and onboarding easier.
ETL architecture should evolve alongside the business. Design with flexibility in mind so new data sources, transformations, or analytics use cases can be added without major redesigns.
The future of ETL architecture is increasingly shaped by artificial intelligence and advanced data automation. As data volumes grow and sources become more complex, AI is being used to optimize how pipelines are designed, monitored, and maintained. Intelligent systems can automatically detect schema changes, identify data quality issues, and recommend transformation logic, reducing manual interventions.
AI-driven automation is also improving pipeline performance and reliability. Predictive monitoring can anticipate failures before they occur, while adaptive resource allocation helps balance cost and performance in real time. As a result, ETL architectures are becoming more self-healing and resilient.
Looking ahead, ETL will continue to move closer to real-time and event-driven models. Combined with AI-powered automation, this shift will allow organizations to deliver trusted data faster, support more dynamic analytics use cases, and scale pipelines with less operational overhead.
A strong ETL architecture is the foundation of reliable analytics, efficient data pipelines, and informed decision-making. As data sources multiply and the business evolves, organizations should have an approach that’s flexible, scalable, and easy to manage.
Domo supports modern ETL architecture by providing low-code tools that simplify data integration, automate transformations, and deliver trusted data directly to the people who use it. With built-in governance, monitoring, and analytics, Domo helps teams move from complex pipelines to streamlined, business-ready data flows.
Ready to modernize your ETL architecture and turn data into insight faster? Explore Domo or try our platform for free to see how it works.





.avif)
