Hai risparmiato centinaia di ore di processi manuali per la previsione del numero di visualizzazioni del gioco utilizzando il motore di flusso di dati automatizzato di Domo.
Guarda il video


One model rarely gets you all the way there. Hybrid machine learning blends deep learning with traditional ML, rule-based systems with neural networks, or multiple model types in a single architecture so you can trade less between accuracy, interpretability, and flexibility. This article breaks down five major categories of hybrid ML, walks through implementation patterns like semi-supervised and self-supervised learning, and covers real-world applications from predictive maintenance to fraud detection. You'll also get a practical gut-check for when hybrid complexity is worth it and what tools help you run governed hybrid pipelines.
Here are the main points to keep in mind:
Most ML algorithms are excellent at one job with one kind of data. That is still a huge upgrade over manual analysis, but it caps what you are able to do when your data is messy, mixed-format, and spread across systems.
Hybrid machine learning (HML) is what you reach for when "one model" is not the constraint you want to live with. Run multiple algorithms together so they complement each other. Stop forcing every problem into the same modeling shape.
Before diving deeper, get specific about what "hybrid" means here. People use the term in a few different ways across the industry, and mixing them up makes evaluations drag on longer than they should.
Here is how the major categories break down:
This article focuses primarily on algorithmic hybrids, systems that combine different learning approaches to get results no single model could deliver on its own. (Deployment hybrids are a separate conversation, and honestly a frequently conflated one.)
Forrester reports that "98 percent of organizations said that analytics are important to driving business priorities, yet fewer than 40 percent of workloads use advanced analytics or artificial intelligence."
That gap is exactly where hybrid machine learning shows up in practice. Teams care about analytics, but production constraints like data variety, governance, and integration effort keep advanced approaches from making it into real workflows.
Automation and AI become even more important when you consider the exponential rate at which companies are producing data in need of continuous analysis. AI powered by machine learning (ML) will be critical to managing future insights for data scientists. ML uses algorithms and statistical models to identify patterns, mine data, and apply labels across different datasets. These models learn from the data as they go and will help data scientists develop increasingly sophisticated and accurate predictions.
For Data Engineers and Architectural Engineers managing legacy-to-cloud transitions, the appeal of hybrid ML is not academic. It is survival. Single-model approaches often crack when data quality varies across sources, legacy systems impose constraints, or the cost of rebuilding pipelines for every new model type turns into a permanent backlog. Hybrid architectures let you move forward while working with what you have, not what you wish you had.
For AI/ML Engineers, "hybrid" can also mean hybrid model sourcing: mixing a vendor model (like DomoGPT), third-party models (including popular large language model providers), and custom models trained elsewhere, without turning every experiment into a months-long integration project. Teams that treat this as a purely technical swap tend to regret it. If you do not standardize inputs, outputs, and evaluation criteria, you end up comparing apples to transcripts.
With the right BI and ML tools in place, companies will be able to extract even greater insights from their data.
There is no trophy for "most hybrid." The real question is whether hybrid complexity solves the constraints you actually have, or just adds a new layer to babysit.
Single-model approaches work well when your data is consistent, your requirements are clear, and your compute budget has room to spare. The walls show up fast in a few familiar places.
Traditional ML models struggle with unstructured data. If your use case involves images, text, or audio alongside structured records, a Random Forest or XGBoost model alone will not cut it. You will need deep learning for the unstructured components, and at that point, you are already building a hybrid system whether you call it that or not.
Deep learning models, meanwhile, often struggle with interpretability. When a compliance team asks why a model flagged a specific transaction, "the neural network said so" will not land. Regulated environments require explainable outputs and an audit trail, and pure deep learning rarely gives you both without substantial extra work.
Running single-model systems in production long enough, you start to see the pattern. Every new data type or requirement means a new pipeline. That pipeline adds governance overhead, slows deployment timelines, and increases the surface area for errors. Maintain six different model architectures with six different deployment patterns and, pretty quickly, operations becomes the bottleneck.
Hybrid ML earns its keep when one or more of these conditions is true:
If you checked multiple boxes, hybrid ML is likely worth the investment. If your data is uniform, your requirements are simple, and interpretability is not a concern, a well-tuned single model will usually deliver the outcome with less operational overhead.
Quick framing before we get into examples: the hybrid types below are algorithmic hybrids, approaches that combine different learning paradigms within a single system. They are different from deployment hybrids (on-prem + cloud splits), which describe where models run rather than how they learn.
In semi-supervised learning, you provide the algorithm with a small set of labeled data, then hand it a much larger set of unlabeled data and put it to work. Useful when you need to start with a smaller batch of data upfront, or when labels are expensive to produce. In practice, teams tend to trust pseudo-labels too early. You usually need confidence thresholds and periodic spot-checks so the model does not reinforce its own mistakes.
This form of HML works well with data that changes over time. Take supply cost tracking: as costs shift, production plans and forecasts shift with them, and semi-supervised learning can help you keep categories and signals current without labeling everything by hand.
Or consider brand sentiment for customer retention. Track how current customers are engaging with or discussing your brand on social media, then turn that into targeted mitigation strategies when customers fall below a designated threshold. Sentiment labels drift faster than most teams expect, so plan a refresh cadence for your labeled set. A one-and-done training run will not hold.
Often, you can use semi-supervised learning in tandem with unsupervised and supervised learning methods. These additional models help with grouping and training on unlabeled data, especially when you need a clean separation between "discover structure" and "predict outcomes."
Self-supervised learning starts by creating "labels" from the data itself, then trains with a supervised objective on those generated targets. It is a useful workaround when you have lots of raw data and not much annotation budget. The easy misread is assuming any pretext task will transfer well. If the task you invent (say, rotation prediction) does not reflect what you care about downstream, you get impressive training curves and mediocre business results.
Teams commonly use this type of learning on unlabeled images and define actions for those images, like rotating them, identifying color or grayscale, or distinguishing between real and fake photos.
Multi-instance learning flips the labeling unit: you label groups or collections of data rather than individual items. Handy when you are working with large sets of similar data or lots of duplicates. Where teams go wrong is treating a "positive bag" label as if every instance inside it is positive. The whole point is that only some instances may drive the label.
This method uses supervised learning models to identify labels for groups of data. You train the models to recognize attributes of a few pieces of data within a group, and then they predict labels for future groups based on attributes of some of the data within the new groups. In production, bag construction matters more than most people realize. Small changes in how you group records can swing performance more than any amount of model tuning.
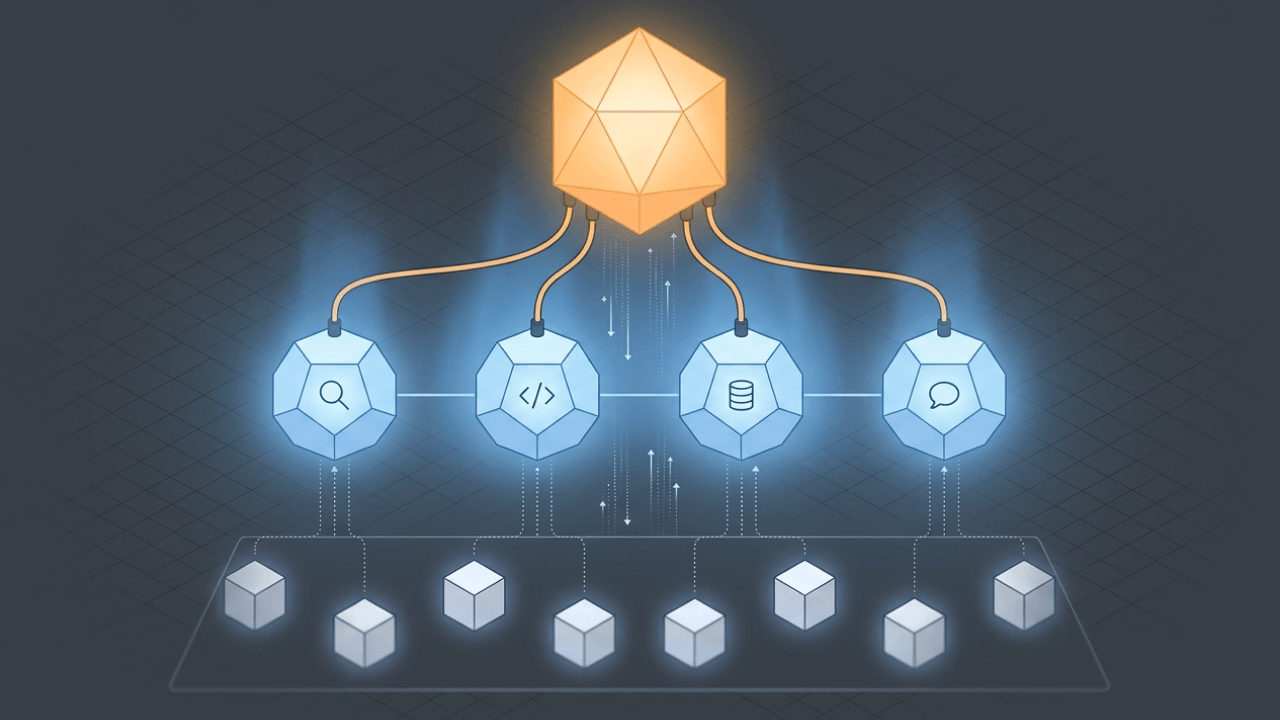
Hybrid machine learning systems combine the strengths of different algorithms into a single, more capable setup. Instead of betting everything on one learning method, HML blends traditional machine learning with deep learning, or runs multiple models in layered or parallel architectures, so you can fit the messiness of real data and real requirements.
Before walking through the workflow stages, it helps to name the integration mechanisms that make hybrid systems work. These are not academic patterns. They are concrete design choices, and each one changes what you can test, debug, and govern.
The most common integration mechanisms include:
In production, there is often one more "glue" layer that matters: orchestration. That can be an ML pipeline that sequences steps (data prep, embeddings, scoring, write-back), or an AI service layer abstraction that lets teams swap or combine models from different providers without rewriting every downstream workflow. Where teams stumble is letting orchestration logic turn into hidden business logic. Keep rules and decision points versioned and reviewable, just like code.
Each pattern has different governance implications. Stacked architectures make it easier to audit individual model outputs at each stage, while parallel fusion architectures require more careful lineage tracking to understand how each component contributed to the final prediction.
Many hybrid pipelines start with deep learning methods like Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), or Transformers to extract high-dimensional features from images, text, or time series. These models are strong at learning representations you would struggle to hand-engineer.
This stage is the first half of what is often called a two-stage hybrid pipeline: deep learning handles feature extraction, then traditional ML handles the final prediction. It is a pattern that shows up repeatedly because it is reusable and keeps the "fancy" part contained.
A few pitfalls to watch for at this stage:
One more real-world gotcha: keep your feature store or embedding outputs consistent across training and serving. If training pulls embeddings from one pipeline and production generates them another way, you will spend weeks chasing "mysterious drift" that is really just a mismatch.
After features are extracted, traditional machine learning algorithmssuch as Decision Trees, Random Forests, XGBoost, or Support Vector Machines can analyze those features for classification, regression, or clustering. These models are generally easier to explain and cheaper to run, which matters when business teams ask for transparency and quick turnaround.
Treating the downstream model as a simple plug-in is a mistake teams make more often than they should. If you do not calibrate probabilities or validate threshold choices, handoffs to rules and workflows can behave unpredictably.
Fusion is how you combine outputs from deep learning and traditional ML components. It is easy to blur fusion with ensemble methods, so it is worth being precise: in a hybrid context, fusion combines fundamentally different model types (for example, a CNN feature extractor feeding an XGBoost classifier), while ensemble methods like bagging or boosting combine multiple instances of the same model family.
The main fusion strategies include:
For example, an ensemble might average multiple model outputs to reduce variance, while stacking uses a meta-model to learn how best to combine the predictions from different model families. Test failure modes explicitly. Hybrid systems can look great on aggregate metrics while still failing badly on the exact edge cases that triggered the hybrid approach in the first place.
Sometimes the "hybrid" part shows up earlier than people expect. Traditional algorithms can play a key role early in the pipeline by handling data cleaning, feature selection, or dimensionality reduction (e.g., using PCAprincipal component analysis (PCA) or clustering methods) before deep learning runs. Just make sure those preprocessing steps are fitted only on training data and then replayed consistently. Otherwise you end up baking future information into your pipeline without realizing it.
Hybrid ML can pay off quickly, but only if you are clear about what you are buying with the added complexity.
In a hybrid machine learning system, each component model can focus on a different part of the problem. The system combines those strengths for more reliable predictions. Traditional ML often handles structured data well, while deep learning shines on unstructured data like images and text. Put them together and you can raise performance across mixed datasets without forcing everything into one feature space.
HML systems can stay steady across changing data types and shifting conditions because they are not dependent on a single modeling assumption. Whether you are dealing with structured numerical data, unstructured text, or multimedia content, hybrid approaches can keep outputs consistent even when one input stream gets noisy or incomplete.
There is a misuse pattern here that does not get talked about enough. Adding more modeling layers can mask weak data quality rather than fix it. If upstream signals are unreliable, hybrids can hide the problem until it surfaces as a business surprise.
Traditional machine learning components in HML systems can add transparency, especially when they are responsible for the final decision or when their outputs are visible as intermediate signals. Decision trees or linear models can complement deep learning by offering clearer reasoning paths, which helps stakeholders understand results and spot potential bias.
Specific mechanisms that can make hybrid systems easier to explain include:
That said, hybrid systems are not automatically more interpretable. When the deep learning component dominates the final output and the rule-based component is only a minor input, the system can be just as opaque as a pure neural network. The interpretability benefit depends entirely on how the hybrid is architected and which components carry the most weight in the final prediction. If you cannot explain the handoff points, you do not really have interpretability. You have a story.
Hybrid models can run across multiple environments, from on-premises systems to cloud platforms, which helps organizations scale without replatforming every workflow. Decide early what must run close to the data (for residency or latency) and what can run in shared services. Skip that decision and you will end up with duplicated pipelines and inconsistent outputs.
Hybrid ML is not a theoretical upgrade. It shows up where single-model approaches struggle under real constraints.
Manufacturing operations use hybrid ML to predict equipment failures before they happen. This is a hybrid system because it combines deep learning models (like LSTMslong short-term memory networks (LSTMs) or CNNs) for pattern recognition in sensor time-series data with traditional ML models (like Random Forests) that incorporate structured maintenance records and operational parameters.
A common implementation gap: teams often train the deep model on pristine historical sensor windows while production data arrives with gaps, missed readings, and sensor downtime. Plan for missingness up front, not as an afterthought.
The deep learning component identifies subtle degradation patterns in vibration, temperature, or pressure data that would be invisible to rule-based systems. The traditional ML component weighs those signals against equipment age, maintenance history, and operating conditions to produce a remaining useful life (RUL) estimate that maintenance teams can act on.
In self-driving systems, accuracy is not enough. You also have to be safe. Neural networks handle perception, identifying pedestrians, reading signs, tracking lane markings, while rule-based systems enforce safety constraints that the neural network alone cannot guarantee.
No amount of training data can cover every edge case a vehicle might encounter. The rule-based layer provides hard constraints (never accelerate toward a detected pedestrian, always yield at stop signs) that override the neural network's outputs when safety is at stake. Teams sometimes treat those rules as a last-minute patch. They work best when designed and tested as first-class requirements with clear precedence from the start.
Medical imaging analysis often pairs deep learning for image recognition with clinical decision rules for diagnosis support. A CNN might identify suspicious regions in a mammogram or CT scan, while a rule-based system cross-references those findings against patient history, risk factors, and clinical guidelines.
Regulatory requirements demand explainability, which is why pure deep learning, even at high accuracy, often cannot stand alone in clinical settings. Clinicians need to understand why a system flagged a particular image. Regulators need audit trails that document the reasoning.
The operational pitfall here is data labeling inconsistency across sites. If your training labels reflect local practice patterns, the model may "learn the clinic," not the condition.
In finance, accuracy fights compliance every day. Hybrid ML helps by letting pattern-recognition models score risk while rule-based systems enforce policies and route decisions to people when necessary.
A platform supporting hybrid ML pipelines can combine deterministic compliance rules (transactions over a threshold require review, certain country combinations trigger alerts) with probabilistic ML models that score transaction risk. Human-in-the-loop checkpoints allow analysts to review and approve flagged accounts before action is taken, creating the audit trail that regulators require.
Rules and models tend to evolve on separate timelines in most organizations. When policy thresholds change and the model's calibration does not, alert volumes can spike overnight.
Hybrid ML's upside comes with real operational complexity. Plan for it before launch, not after.
The most significant challenges include:
One practical problem that shows up fast: hybrid ML usually multiplies data touchpoints, which multiplies privacy risk. Without automated personally identifiable information (PII) monitoring and clear access controls, experimentation can turn into an audit headache. And if your hybrid includes large language models, do not forget prompt and retrieval logs. Those can become sensitive artifacts too.
Mitigation strategies center on centralized governance and pipeline standardization. A unified model registry with staging and production states, lineage metadata (code version, dataset ID, environment tags), and role-based access controls provides the foundation for governing hybrid systems at scale.
ML earns its spot in analytics when it helps you act on the data you have now, not just summarize what already happened. That often means grouping and labeling data in near real time, then turning model outputs into something a team can use without a PhD in model tuning.
When considering how to manage this data, you will need a few key features in your business intelligence tools to support this type of advanced analysis. In addition to basic functionality, look for platforms that provide:
If you are thinking, "Cool, but where does all that actually live?" you will usually see it split across three layers:
Your tool will need to support:
You will want one place to manage your data and train your ML models. Find a tool that will allow for easy integration of all your data sources.
For hybrid ML workloads specifically, look for incremental ingestion (which feeds only changed data into retraining pipelines, reducing compute costs) and event-based pipeline triggers (which invoke ML models as soon as new data arrives, enabling real-time inference). Wire triggers without idempotency and you will find the same event firing twice, creating duplicate predictions or double-written actions.
It also helps when your integration layer includes day-to-day governance features Data Engineers end up rebuilding over and over, like:
Many of the HML models mentioned here function best as they are learning from new data. Find tools that will support real-time ingestion and analysis, and then will push that data out to workers who can use it to improve performance right then.
For Data Engineers, real-time processing is not just about speed. It is about reliability. Inconsistent or delayed data is one of the most common reasons hybrid ML pipelines fail in production. Real-time processing helps keep hybrid models from making decisions on stale inputs, which is the difference between a system people trust and one they quietly work around.
If your hybrid ML setup includes AI agents (for example, workflows that call a large language model alongside a classic classifier), real-time also means the model can read the latest governed data at the moment of decision. Patterns like retrieval-augmented generation (RAG) help here by grounding an agent's response in governed datasets and FileSets instead of whatever the model "remembers." Pointing RAG at unvetted document dumps is a mistake we see repeatedly. If the source content is not governed, you have just moved the risk from the model to the retrieval layer.
Find a tool that will support automatic decisions for your team, with alerts and notifications for when your data passes specific thresholds.
In hybrid ML systems where multiple model types contribute to a single output, human-in-the-loop validation is often the governance hinge. The ability to require human review before a model-driven decision executes is what makes the system auditable and trustworthy. Define the review triggers up front (confidence bands, dollar thresholds, policy flags) so you do not end up with either alert fatigue or silent automation.
In practice, this is where an orchestration and workflow layer earns its keep. For example, Agent Catalyst can combine deterministic steps (business rules, approvals) with probabilistic steps (model calls), while still keeping guardrails like:
Once your hybrid ML output exists, the BI layer has to speak the same business language as the rest of your reporting. A certified metrics and semantic layer, AI-powered alerts, and statistical analysis with AI guidance help BI and Analytics Leaders keep AI-driven insights consistent and trustworthy. Skip that layer and you will notice a familiar problem: the model is "right," but every team interprets "right" differently.
No matter your industry, your data will continue to play an increasingly important role in how you do business. Incorporating hybrid machine learning techniques can help you build tools that get value from your data now, and keep working as your business grows.
The four commonly cited types are supervised learning (training on labeled data), unsupervised learning (finding patterns in unlabeled data), semi-supervised learning (combining small labeled sets with large unlabeled sets), and reinforcement learning (learning through trial and error with rewards). Hybrid ML often combines two or more of these paradigms, for example, using semi-supervised learning to expand a limited labeled dataset, then applying supervised learning for the final classification task. Be explicit about which paradigm owns which part of the workflow. Unclear training objectives are where things go wrong, not the architecture.
XGBoost is an ensemble model (gradient-boosted decision trees), not typically labeled "hybrid" on its own. However, XGBoost becomes part of a hybrid system when combined with a different model paradigm, for example, using CNN embeddings as input features for an XGBoost classifier. The distinction: ensemble methods combine multiple instances of the same model type, while hybrid systems combine fundamentally different model types. In reviews, make sure everyone is using the same definition, or you will spend the meeting debating vocabulary instead of architecture.
A fraud detection system that uses rule-based triage for obvious cases (transactions over a threshold, known fraud patterns) combined with a neural network for scoring ambiguous transactions is a hybrid AI system. The rule-based component provides transparency and enforces compliance requirements, while the ML component handles the nuanced pattern recognition that rules alone cannot capture. Define what the rules catch, what the model scores, and where a person must review. That handoff is the part most implementations leave vague.
Ensemble learning combines multiple instances of the same model type (e.g., multiple decision trees in a Random Forest, or multiple weak learners in gradient boosting). Hybrid ML combines fundamentally different model types, such as a deep learning feature extractor feeding a traditional ML classifier, or a neural network working alongside a rule-based system. The key distinction is architectural diversity, not just model quantity. If your models are all from the same family, you are usually in ensemble territory even if the pipeline feels complex.
At minimum, you need a data integration layer that can handle diverse data types, a model training environment that supports multiple frameworks, a model registry for versioning and governance, and a deployment infrastructure that can serve predictions in real time. Look for platforms that offer BYOM (Bring Your Own Model) support, lineage tracking, and role-based access controls. The governance layer is especially important for hybrid systems because you need to track how multiple model components contribute to each prediction. Without that traceability, debugging turns into guesswork.




.png)
.png)