Machine Learning Pipelines: What They Are, Importance, Examples, and Uses Cases


What is a machine learning pipeline?
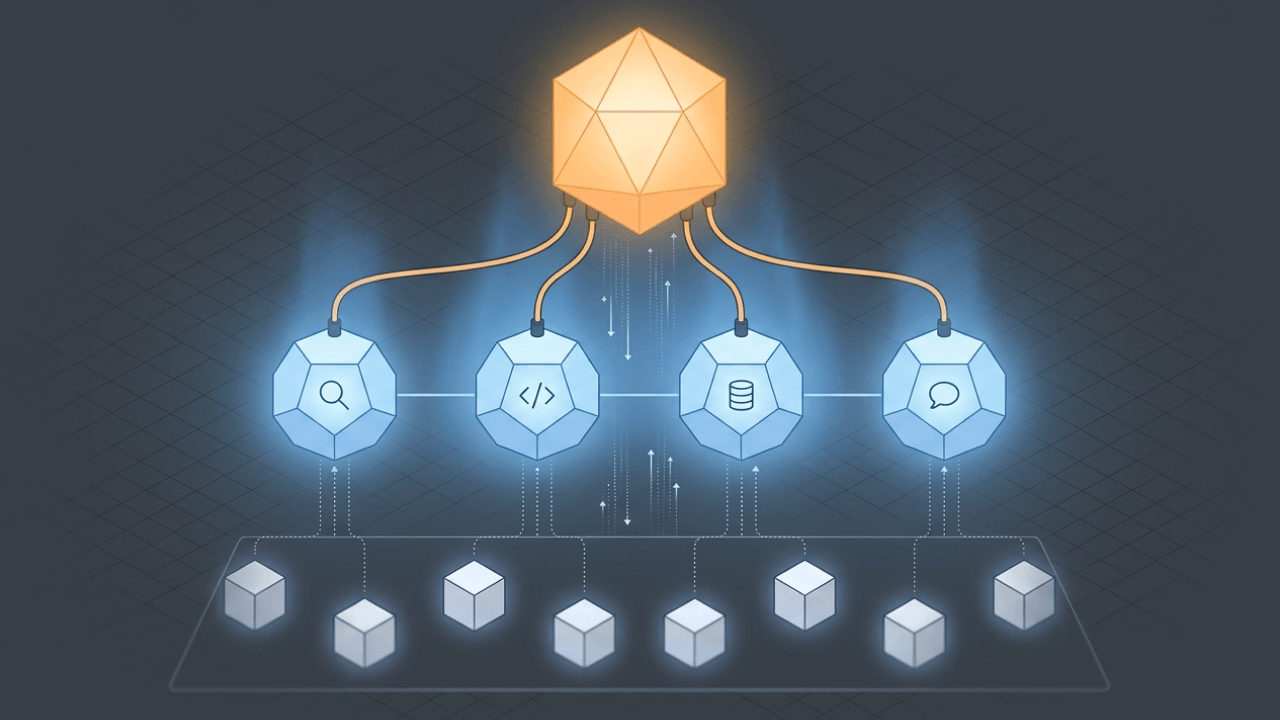
A machine learning (ML) pipeline is a structured, automated workflow that connects every step of the ML lifecycle—from raw data to real-time predictions. It links processes like data collection, preprocessing, feature engineering, model training, evaluation, deployment, and ongoing maintenance into one streamlined system.
By automating these steps, ML pipelines improve efficiency, reduce human error, and help data teams scale their efforts consistently. Think of it as the backbone that keeps machine learning projects repeatable, scalable, and production-ready.
Key components of a machine learning pipeline
While every pipeline will vary depending on the use case and tools, most ML pipelines share a common set of components. These work together to transform messy, raw data into high-performing predictive models:
- Data acquisition and preparation
Data is collected from various sources—like APIs, databases, or flat files—and cleaned up through deduplication, normalization, and handling of missing values. This step ensures your model has reliable, usable inputs. - Feature engineering
Raw data often needs to be transformed into more meaningful inputs. This step involves creating new features or selecting the most relevant ones to help your model make better predictions. - Model training
Once the data is ready, it’s time to select an algorithm and train the model. This is where the system learns from your historical data to make predictions. - Model evaluation
Trained models are evaluated against metrics like accuracy, precision, or recall to make sure they’re performing well. Cross-validation and test splits help prevent overfitting. - Model deployment
After evaluation, the best model is deployed to a production environment where it can deliver predictions in real time or in batch mode. - Monitoring and maintenance
Even great models can degrade over time. This step ensures the pipeline continues to deliver accurate results, with retraining and updates as needed.
Why are machine learning pipelines important?
Data pipelines for machine learning are important for managing complexity. Pipelines typically have multiple steps, each with unique requirements, such as different libraries and runtimes. They may also need to execute on specialized hardware profiles. ML pipelines allow you to factor these considerations and requirements into development and maintenance.
Benefits of machine learning pipelines
Machine learning pipelines bring order to chaos, especially in data-rich environments. Here’s what they help you achieve:
- Better team collaboration
A well-documented pipeline acts as a shared blueprint, making it easier for teams to collaborate across data, engineering, and business. - Automation at every stage
Automate repetitive tasks like preprocessing, training, and deployment—freeing up time for more impactful work. - Reproducibility you can count on
With standardized, traceable workflows, it’s easier to repeat experiments and debug issues. - Scalability for big data and teams
Pipelines are designed to grow with your data and your org, making it easier to scale models across departments or use cases. - Efficiency from start to finish
Eliminate slow, manual handoffs by turning fragmented processes into streamlined workflows.
ML pipelines empower organizations to handle complexity, enhance scalability, and free up valuable resources for innovation, driving impactful machine learning solutions at scale.
How to build a machine learning pipeline: Step-by-step
If you’re interested in building an ML pipeline to improve consistency, reduce repetitive tasks, and more, here are the key steps at a high level.
1. Data collection
ML relies on data, so the first step is to collect it from all relevant sources, such as databases, APIs, and files. It’s crucial to make sure that the data is high-quality and does not have missing values, duplicate information, or other errors.
2. Data preprocessing
If you’re working with raw data, you may need to preprocess the data. This step converts the raw data into a clean, structured format so it can be used for analysis and model training.
3. Feature extraction and engineering
In this third step, you convert the raw data into useful features to drive the ML model’s predictive capabilities (i.e., feature extraction).
4. Model selection
Model selection refers to the process of evaluating, comparing, and choosing the most ideal model to meet data and problem requirements.
5. Model training and evaluation
Next up is model training and evaluation. In the model training stage, you will train the ML model to make predictions based on the data you’ve prepared.
6. Model deployment
Once the ML model has been evaluated and found to perform satisfactorily, it can be deployed in a production environment.
7. Monitoring and maintenance
Finally, the ML model will need to be monitored continuously and maintained over time.
Use cases and real-world examples of machine learning pipelines
As machine learning expands into multiple domains and applications, there are a growing number of relevant use cases.
Data Collection
An example of data collection is gathering data from all relevant sources.
Data preprocessing
Once you’ve collected your customer churn data, you may find that it is not all suitable for your machine learning data pipeline.
Feature extraction and engineering
In the use case of customer churn prediction, you would select or engineer features relevant to your goal.
Predicting customer churn
Here’s what a typical ML pipeline might look like when predicting customer churn:
- Extract customer data from your CRM and product databases.
- Preprocess the data—cleaning inconsistencies and handling missing values.
- Engineer features like login frequency, past purchases, or support interactions.
- Train a model like logistic regression or a decision tree.
- Evaluate its performance using accuracy, recall, and precision.
- Deploy the model to a live system to predict churn likelihood.
- Monitor the results and retrain the model as needed.
History and evolution of machine learning pipelines
Throughout history, as machine learning and data science have advanced, so has the evolution of machine learning pipelines. Data processing workflows pre-date the 2000s and were primarily used for data cleaning, transformation, and analysis. Unlike today’s workflows, they were largely manual or reliant on spreadsheets.
Machine learning pipelines came to be right around the 2000s. Prior to automated workflows, data scientists and researchers used manual processes to manage machine learning tasks. In 1996, the Cross-industry standard process for data mining (CRISP-DM) was defined as a standard process for data mining. It breaks down data mining into six phases and largely governed the management of ML workflows:
- Business understanding
- Data understanding
- Data preparation
- Modeling
- Evaluation
- Deployment
Workflows continued to be made more systematic and automated as machine learning advanced as a field. Data science entered as a concept across disciplines in the late 2000s. As such, data scientists formalized related workflows and introduced preprocessing, model selection, and evaluation to pipelines. In the 2010s, machine learning libraries and tools emerged. This allowed data scientists and other practitioners to more easily create and evaluate machine learning data pipelines. During this time, there was a greater emphasis on scalable pipelines due to more big data technologies.
In the 2010s, the concept of automated machine learning (AutoML) came to the forefront. Practitioners now had more tools and platforms available to automate the building, deployment, and management of machine learning pipelines and related tasks. During this time, machine learning pipelines were also integrated with DevOps practices. This integration allowed for continuous integration and deployment (CI/CD) models, known as machine learning operations (MLOps).
The concepts of containerization and microservices became more popular during this time period as well. Docker was released in 2013 and is one of the top platforms for containerization due its facilitation of packaging and deploying software apps. Kubernetes emerged in 2014 and automates tasks associated with containerized apps, including machine learning workloads.
.png)
.png)