Vous avez économisé des centaines d'heures de processus manuels lors de la prévision de l'audience d'un jeu à l'aide du moteur de flux de données automatisé de Domo.
Regardez la vidéo


The modern data stack (MDS) is a modular, cloud-native ecosystem of best-in-class tools that handle the full data lifecycle — from ingestion and storage to transformation, analysis, governance, and observability. Unlike legacy, on-premises systems, the modern stack is flexible, automated, and scalable, enabling real-time insights and AI-driven decision-making.
Data is the backbone of modern business. Over the past decade, the tools and architectures used to handle data have evolved dramatically. In 2025, we reached a new era of scalability, automation, and AI augmentation, enabled by a powerful framework known as the modern data stack (MDS).
What started as a buzzy catchphrase in tech circles, has matured into a foundational concept that shapes how organizations collect, transform, govern data. The modern data stack of 2025 is far more than a collection of cloud-native tools. It enables real-time insights, smarter decision-making, and faster innovation.
In this guide, we’ll walk you through what the modern data stack looks like in 2025 and how it has evolved, along with its core components, some use cases, and best practices for integrating it into your workflows. Whether you’re rebuilding legacy infrastructure or looking to future-proof your analytics architecture, this blueprint is essential for your success.
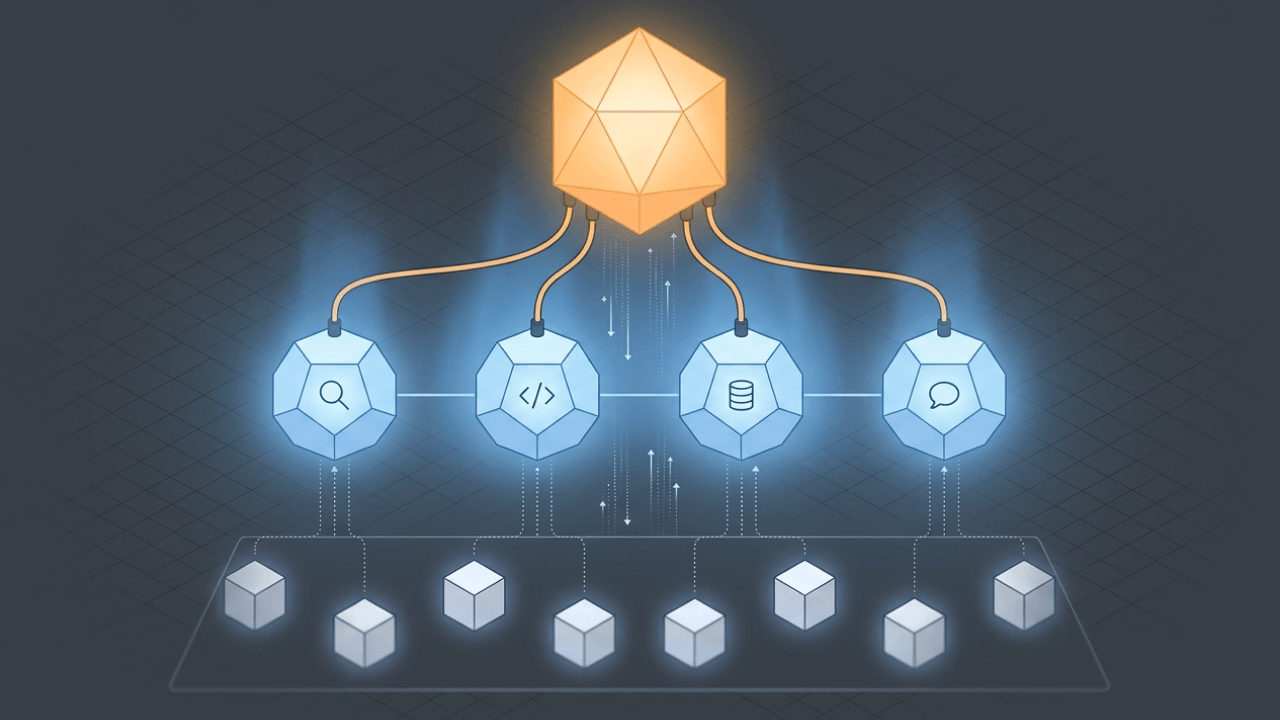
The modern data stack is a collection of interoperable, cloud-based tools and services, designed to manage the complete data lifecycle—from ingestion and storage to transformation, analysis, and activation. Unlike traditional systems that required manual integration and were difficult to scale, the modern stack is composable, elastic, and developer-friendly.
At its core, the modern stack enables you to:
Modern data stacks are built to support real-time data needs, self-service analytics, advanced machine learning (ML), and compliance with data privacy regulations.
To better understand the modern data stack in 2025, we can look back at how data architectures have evolved.
In the early 2010s, most organizations relied on their on-premises data warehouses and monolithic BI tools. Data pipelines were often rigid, expensive to maintain, and designed for batch processing. At the time, “big data” was the buzzword. However, few companies had the cloud infrastructure to use it effectively.
The turning point came with the rise of cloud-native platforms like Amazon Redshift, Google BigQuery, and Snowflake. These tools made scalable data storage more widely accessible, enabling organizations of all sizes to store and query massive data sets without managing physical servers.
Around the same time, companies like Fivetran, dbt, and Looker emerged, offering modular solutions to ingest, transform, and visualize data. By the mid-2010s, the phrase “modern data stack” began to gain traction among startups and data-savvy tech teams.
By 2022, the stack had become a mainstream concept. With more people working remotely and businesses embracing digital transformation and AI, enterprises realized that legacy systems couldn’t keep up. The modern data stack became the new standard.
Now in 2025, we’ve seen massive maturity in tools, architecture, and practices. AI has become embedded into nearly every layer of the stack. And the need for speed, governance, and insight has never been higher.
The modern data stack is modular by design. Each component handles a specific function, allowing for flexibility, customization, and innovation.
Here’s what a typical 2025 stack includes:
Tools like Fivetran, Airbyte, Stitch, and Supermetrics extract data from source systems—CRMs, SaaS apps, databases—and load it into a central warehouse. In 2025, most teams favor ELT (Extract, Load, Transform) over traditional ETL for better scalability and performance. With ELT, raw data is preserved in the warehouse, allowing for dynamic modeling and retrospective changes.
Many ingestion tools now support real-time sync via change data capture (CDC), making it easier to replicate on-prem data to the cloud with minimal lag. In addition, low-code interfaces and pre-built connectors have made integration faster and more accessible to teams without deep engineering resources.
These platforms are the backbone of your data architecture. In 2025, most organizations use:
Lakehouse architectures are gaining popularity for their ability to store raw and processed data in a single environment, supporting both analytics and AI with minimal friction. The unified approach helps reduce data duplication and complexity while supporting a wide range of file formats and access patterns.
The industry leader remains dbt (data build tool), with competitors like Dataform and Coalesce offering alternatives. These tools allow teams to write SQL-based transformations that are version-controlled, testable, and reusable. Developers benefit from Git integration, modular codebases, and templating, reducing duplication and improving consistency.
In 2025, transformation tools are tightly integrated with Git-based workflows, observability platforms, and even AI assistants that auto-generate modeling logic or suggest optimizations. Many tools include visual editors and testing frameworks, making it easier for analysts and engineers to collaborate on trusted data models.
Self-service analytics is the ultimate goal for many businesses, and modern BI tools deliver on that promise. They also now offer embedded analytics, allowing data teams to deliver insights directly inside other tools like Salesforce, Slack, or internal apps. In 2025, many platforms offer AI-generated narratives and explainability features, allowing users to not only see the data but also understand the “why” behind the trends.
This is where analytics meets operations. Reverse ETL tools like Hightouch, Census, and Weld sync data from the warehouse back to business systems—powering personalization, campaign automation, and customer support. These tools make the warehouse more than a place for analysis; it becomes the engine for action.
Many of these tools support event-driven architectures and integrate directly with customer data platforms (CDPs), CRMs, and feature flag tools. Newer solutions embrace “composable CDP” models, allowing companies to activate their data without vendor lock-in.
Data stacks are only as reliable as they are trustworthy. Modern stacks include:
Governance has shifted upstream to the beginning of development instead of bolted on after the fact. In 2025, these tools increasingly include AI-powered tagging, PII detection, and impact analysis, helping teams move faster without compromising on trust or compliance.
The newest addition to the stack is intelligent automation. In 2025, AI-powered agents assist with:
This “agentic layer” is still maturing, but it’s quickly becoming essential for productivity and data democratization. As LLMs improve, these agents are beginning to act not just as assistants but as autonomous collaborators. They can recommend optimizations, propose new KPIs, or detect root causes of data anomalies. The organizations embracing this layer are already seeing a steep reduction in manual overhead and time-to-insight.
Track freshness, volume anomalies, schema changes, and pipeline SLAs. Modern tools detect issues early and provide lineage for impact analysis, so teams can fix problems before they affect dashboards and models.
Define access, privacy, and compliance policies, while a data catalog documents metadata and lineage. In 2025, AI-assisted tagging and PII detection accelerate stewardship without slowing delivery.
Any organization pursuing real-time decision-making, automation, or AI benefits—from SaaS and e-commerce to finance, healthcare, logistics, and manufacturing. Common triggers include rapid data growth, compliance needs, self-service analytics demand, or stalled AI initiatives.
Whether you’re a Fortune 100 company or a digital-first startup, the modern data stack solves critical pain points across the organization.
The modern data stack supports real-world business outcomes. Some of the most common applications include:
Operational efficiency: Identify bottlenecks in supply chains, onboarding, or support by analyzing system data. Automate reporting, spot anomalies, and drive down response times across business units.
Implementing the modern stack doesn’t mean ripping everything out. In fact, the best approach is incremental. Here’s how to get started:
Rather than starting with tools, start with a question: What decision do you want to support with better data? Choose one domain (e.g., marketing attribution, sales forecasting) and build a vertical stack that delivers end-to-end value.
Pick a cloud data warehouse that fits your volume, complexity, and budget. Most teams choose Snowflake, BigQuery, or Databricks—but make sure it integrates with your existing tools and workflows.
Use ELT tools to start pulling in data from core systems. Begin with low-hanging fruit like Salesforce, Google Analytics, or internal databases.
Use dbt or similar tools to clean, model, and document your data. Create reusable models that reflect business logic—such as revenue calculations, active users, or churn definitions.
Deploy a BI tool that enables non-technical users to explore data on their own. Then, use reverse ETL to push insights into the tools where decisions happen.
Set up observability tools to track freshness, volume anomalies, and schema changes. Use data catalogs to maintain trust and compliance.
While the modern data stack offers powerful capabilities, it’s not without challenges:
The stack continues to evolve, and in 2025, three trends stand out:
Every layer of the stack is gaining AI-powered assistants. From pipeline generation to anomaly detection to executive summaries, intelligent agents are accelerating work across roles. These agents enhance creativity, suggest transformations, and help business users phrase better questions. In some tools, AI copilots now monitor pipeline health, write documentation, and even proactively flag anomalous data points before they impact decisions.
The result? A more agile, intelligent, and proactive data culture.
The rise of APIs and data modeling languages (like dbt and ThoughtSpot’s TML) is making it easier to build stack components that snap together like LEGO blocks. This unlocks flexibility without sacrificing control. Organizations can mix and match best-in-class tools while maintaining a consistent metadata layer and governance model. Developers benefit from reusability, while analysts gain the freedom to innovate without breaking production systems. The composable approach is transforming the stack from a rigid pipeline into a dynamic ecosystem.
More companies are embracing decentralized models, where domain teams own their data products. Combined with modern stack tools, this leads to more scalable and sustainable architectures.
Instead of relying on a centralized data team for every request, product, marketing, and operations teams now own and manage their own trusted data assets, complete with documentation, quality checks, and access controls.
With proper training and tooling, data becomes a first-class citizen across the organization. The modern data stack makes this shift possible by reducing technical barriers and encouraging accountability.
The modern data stack has come a long way, from early startup adoption in 2015 to enterprise mainstay in 2025. Today, it powers everything from personalization engines to executive dashboards to AI copilots.
But like any good architecture, it’s not about the tools—it’s about outcomes. The best data stacks are those that support clear goals, grow with your business, and empower your people.
If you’re still running on legacy infrastructure, now is the time to explore what’s possible. And if you’ve already made the leap, take a step back and ask: Are we building the right things? Are our tools serving us or slowing us down?
The modern data stack isn’t just modern anymore. It’s mission-critical.
Explore how Domo helps you modernize your data stack and turn it into a real driver of business value.




.png)
.png)